Download to read offline






![PyCUDA + Примеры
import pycuda.autoinit
import pycuda.driver as drv
import numpy
from pycuda.compiler import SourceModule
mod = SourceModule(“””
__global__ void add_vect(float *dest, float *a, float *b){
const int i = threadIdx.x;
dest[i] = a[i] * b[i];
}
“””)
func = mod.get_function(“add_vec”)
func(drv.Out(dest), drv.In(a), drv.In(b), block=(400,1,1), grid=(1,1))](https://image.slidesharecdn.com/pythonandgpgpu-petrenko-151013051232-lva1-app6892/75/Python-GPGPU-10-2048.jpg)
![PyCUDA + Примеры
import pycuda.autoinit
import pycuda.driver as drv
import numpy
from pycuda.compiler import SourceModule
mod = SourceModule(“””
__global__ void mult_matrix(float *dest, float *a, float *b, int N){
const int tx = threadIdx.x;
const int ty = threadIdx.y;
const int i = tx*N + ty;
dest[i] = 0;
for(int k = 0; k < n; k++){
dest[i] = a[tx*N + k] * b[k*N + ty];
}
}
“””)
func = mod.get_function(“mult_matrix”)
func(drv.Out(dest), drv.In(a), drv.In(b), block=(40,40,1), grid=(1,1))](https://image.slidesharecdn.com/pythonandgpgpu-petrenko-151013051232-lva1-app6892/75/Python-GPGPU-11-2048.jpg)
![PyCUDA + Примеры
__global__ void kernelBlur(uchar4* in_image, uchar4* out_image, int w, int h){
int i = blockIdx.y*blockDim.y + threadIdx.y;//row
int j = blockIdx.x*blockDim.x + threadIdx.x;//colomn
if(i >= h || j >= w) return;
if(i == 0 || i == h-1 || j == 0 || j == w-1){
out_image[i*w+j].x = in_image[i*w+j].x;
…
return;
}
int red = 0, green = 0, blue = 0;
for(int k = -1; k < 2; ++k){
for(int m = -1; m < 2; ++m){
red += Blur[(k+1)*3+(m+1)]*in_image[(i+k)*w+j+m].x;
}
}
out_image[i*w+j].x = red/blurSumm;
…
out_image[i*w+j].w = in_image[i*w+j].w;
}](https://image.slidesharecdn.com/pythonandgpgpu-petrenko-151013051232-lva1-app6892/75/Python-GPGPU-12-2048.jpg)



![Особенности оптимизации программ
__global__ mult_matrix(float *C, float *A, float *B, int wA, int wB){
//Конфигурации
float Csub = 0;
for (int a = aBegin, b = bBegin;
a <= aEnd;
a += aStep, b += bStep){
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
As[ty][tx] = A[a + wA * ty + tx];
Bs[ty][tx] = B[b + wB * ty + tx];
__syncthreads();
for (int k = 0; k < BLOCK_SIZE; ++k){
Csub += As[ty][k] * Bs[k][tx];
}
__syncthreads();
}
int c = wB * BLOCK_SIZE * by + BLOCK_SIZE * bx;
C[c + wB * ty + tx] = Csub;
}](https://image.slidesharecdn.com/pythonandgpgpu-petrenko-151013051232-lva1-app6892/75/Python-GPGPU-18-2048.jpg)









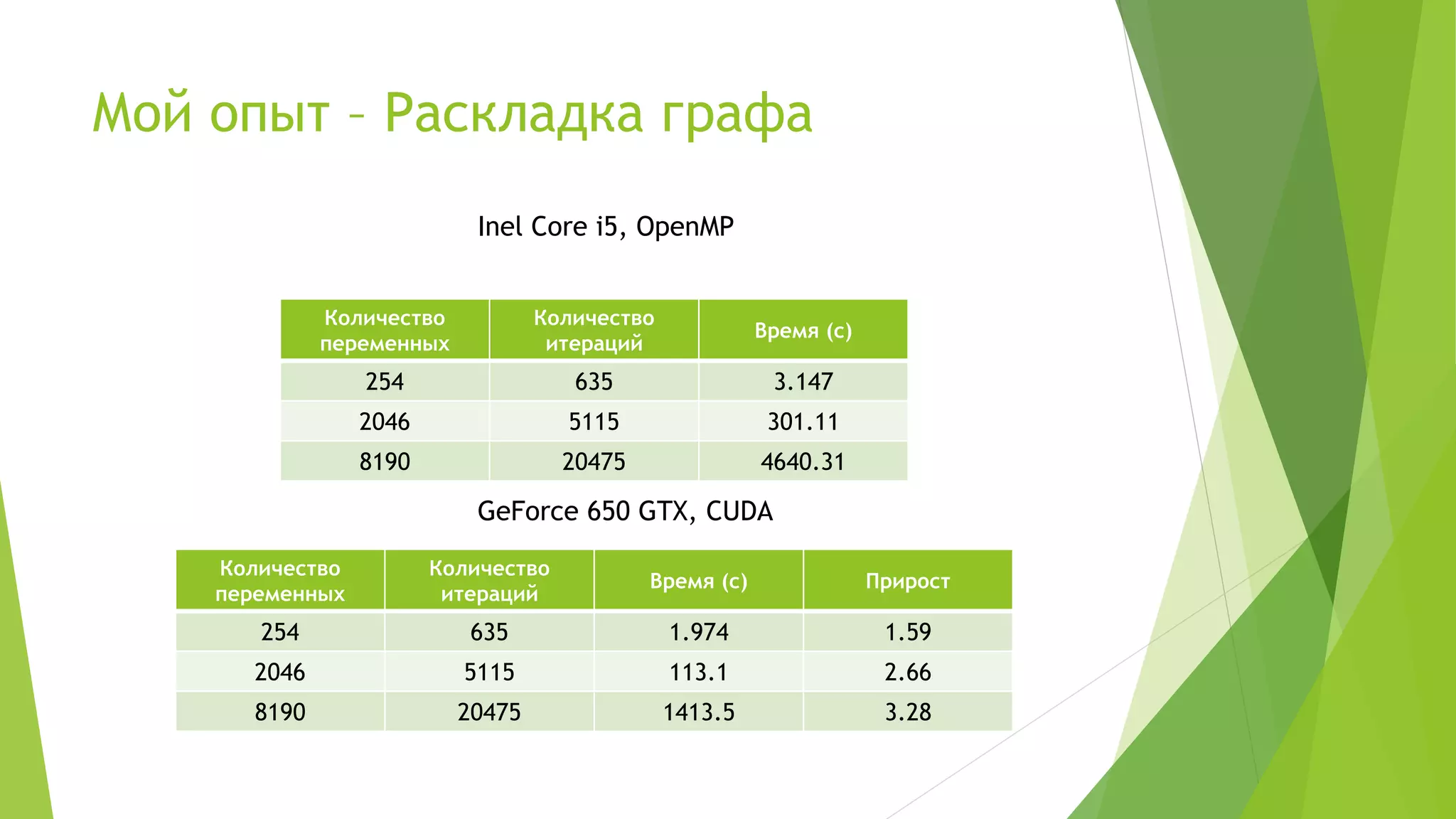

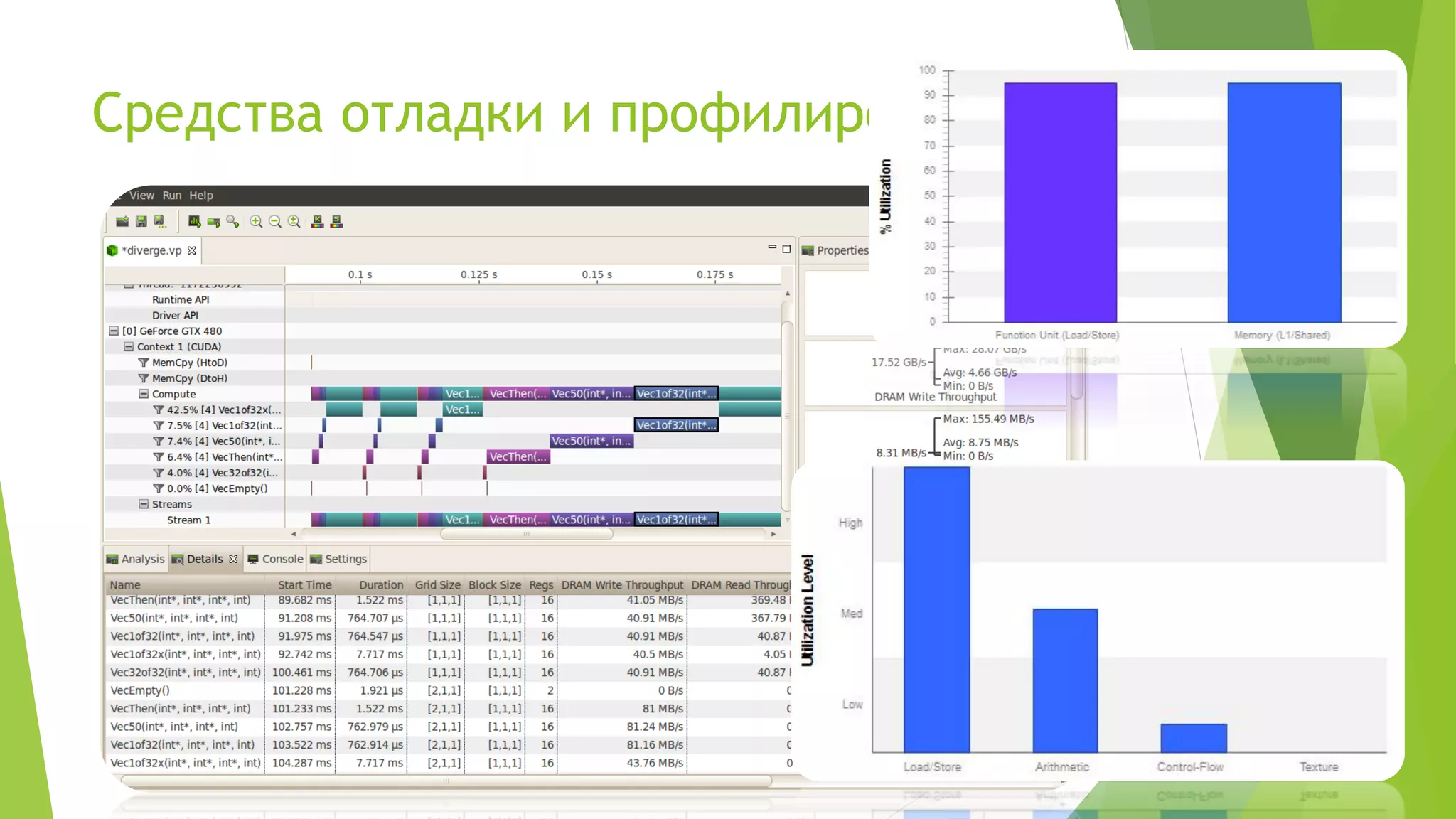



Доклад Евгения Петренко посвящён технологии GPGPU с акцентом на использование CUDA и PyCUDA для разработки высокопроизводительных программ. Раскрываются преимущества и недостатки данной технологии, а также обсуждаются ключевые аспекты, такие как модель памяти, оптимизация программ и типичные задачи, решаемые с помощью CUDA. Доклад включает примеры кода и личный опыт автора в области разработки алгоритмов на GPU.



































































