Downloaded 15 times






![Парсинг по взрослому
grab - http://grablib.org/
scrapy - http://scrapy.org/
8
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['http://blog.scrapinghub.com']
def parse(self, response):
for url in response.css('ul li a::attr("href")').re(r'.*/dddd/dd/$'):
yield scrapy.Request(response.urljoin(url), self.parse_titles)
def parse_titles(self, response):
for post_title in response.css('div.entries > ul > li
a::text').extract():
yield {'title': post_title}
$ scrapy runspider myspider.py](https://image.slidesharecdn.com/python-160306113157/85/Python-8-320.jpg)

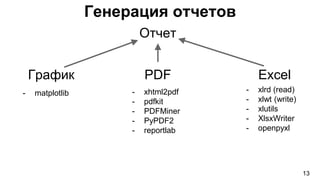






Документ представляет собой руководство по использованию языка программирования Python для решения типичных задач, включая парсинг HTML/XML, генерацию отчетов и создание утилит. Приведены примеры кода и библиотеки, такие как scrapy для парсинга и xlsxwriter для работы с Excel. Также обсуждаются сильные и слабые стороны Python в контексте различных типов приложений.

































