

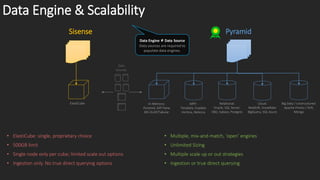
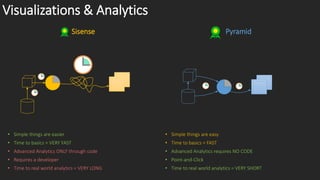

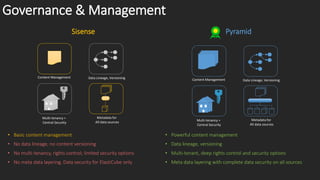
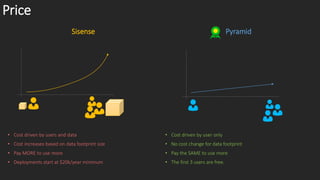


The document compares the data engines and scalability of Sisense and Pyramid, highlighting Sisense's limitations with a 500GB cap and single node per cube versus Pyramid's unlimited sizing and multiple scaling strategies. It outlines that Pyramid offers advanced analytics without coding and has better data governance, content management, and security features. In conclusion, Sisense is recommended for small departments with simple needs, while Pyramid is suited for broader applications.









































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)














