Download as PDF, PPTX






![Ontology
An ontology is an explicit, formal knowledge representation that
expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain;
Properties of those entities;
Relationships among entities;
Processes and events that happen with those entities;
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 4
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-7-2048.jpg)
![Ontology
An ontology is an explicit, formal knowledge representation that
expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities;
Relationships among entities;
Processes and events that happen with those entities;
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 4
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-8-2048.jpg)
![Ontology
An ontology is an explicit, formal knowledge representation that
expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities; firstName, lastName, ...
Relationships among entities;
Processes and events that happen with those entities;
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 4
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-9-2048.jpg)
![Ontology
An ontology is an explicit, formal knowledge representation that
expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities; firstName, lastName, ...
Relationships among entities; motherOf, ownerOf, isFrontOf ...
Processes and events that happen with those entities;
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 4
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-10-2048.jpg)
![Ontology
An ontology is an explicit, formal knowledge representation that
expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities; firstName, lastName, ...
Relationships among entities; motherOf, ownerOf, isFrontOf ...
analyzing if requirements
Processes and events that happen with those entities; are met,
choosing better proposal, ...
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 4
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-11-2048.jpg)
![Probabilistic Ontology
A probabilistic ontology is an explicit, formal knowledge representation
that expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities; firstName, lastName, ...
Relationships among entities; motherOf, ownerOf, isFrontOf ...
analyzing if requirements
Processes and events that happen with those entities; are met,
choosing better proposal, ...
Statistical regularities that characterize the domain;
Inconclusive, ambiguous, incomplete, unreliable, and dissonant knowledge related to entities
of the domain;
Uncertainty about all the above forms of knowledge;
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 5
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-12-2048.jpg)
![Probabilistic Ontology
A probabilistic ontology is an explicit, formal knowledge representation
that expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities; firstName, lastName, ...
Relationships among entities; motherOf, ownerOf, isFrontOf ...
analyzing if requirements
Processes and events that happen with those entities; are met,
choosing better proposal, ...
Statistical regularities that characterize the domain;
Inconclusive, ambiguous, incomplete, unreliable, and dissonant knowledge related to entities
of the domain;
Uncertainty about all the above forms of knowledge;
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 5
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-13-2048.jpg)
![Probabilistic Ontology
A probabilistic ontology is an explicit, formal knowledge representation
that expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities; firstName, lastName, ...
Relationships among entities; motherOf, ownerOf, isFrontOf ...
analyzing if requirements
Processes and events that happen with those entities; are met,
choosing better proposal, ...
Statistical regularities that characterize the domain;
Inconclusive, ambiguous, incomplete, unreliable, and dissonant knowledge related to entities
of the domain;
Uncertainty about all the above forms of knowledge;
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 5
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-14-2048.jpg)
![Probabilistic Ontology
A probabilistic ontology is an explicit, formal knowledge representation
that expresses knowledge about a domain of application. This includes:
Types of entities that exist in the domain; Person, Procurement, Enterprise, ...
Properties of those entities; firstName, lastName, ...
Relationships among entities; motherOf, ownerOf, isFrontOf ...
analyzing if requirements
Processes and events that happen with those entities; are met,
choosing better proposal, ...
Statistical regularities that characterize the domain;
Inconclusive, ambiguous, incomplete, unreliable, and dissonant knowledge related to entities
of the domain; P(isFrontOf|
valueOfProcurement = >1M,
Uncertainty about all the above forms of knowledge; annualIncome = <10k) = 90%
where the term entity refers to any concept (real or fictitious, concrete or abstract) that
can be described and reasoned about within the domain of application. [3]
Introduction - PR-OWL 2.0 - Conclusion 5
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-15-2048.jpg)
![PR-OWL
*reproduced with permission from [3] - extended version
Introduction - PR-OWL 2.0 - Conclusion 6
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-16-2048.jpg)


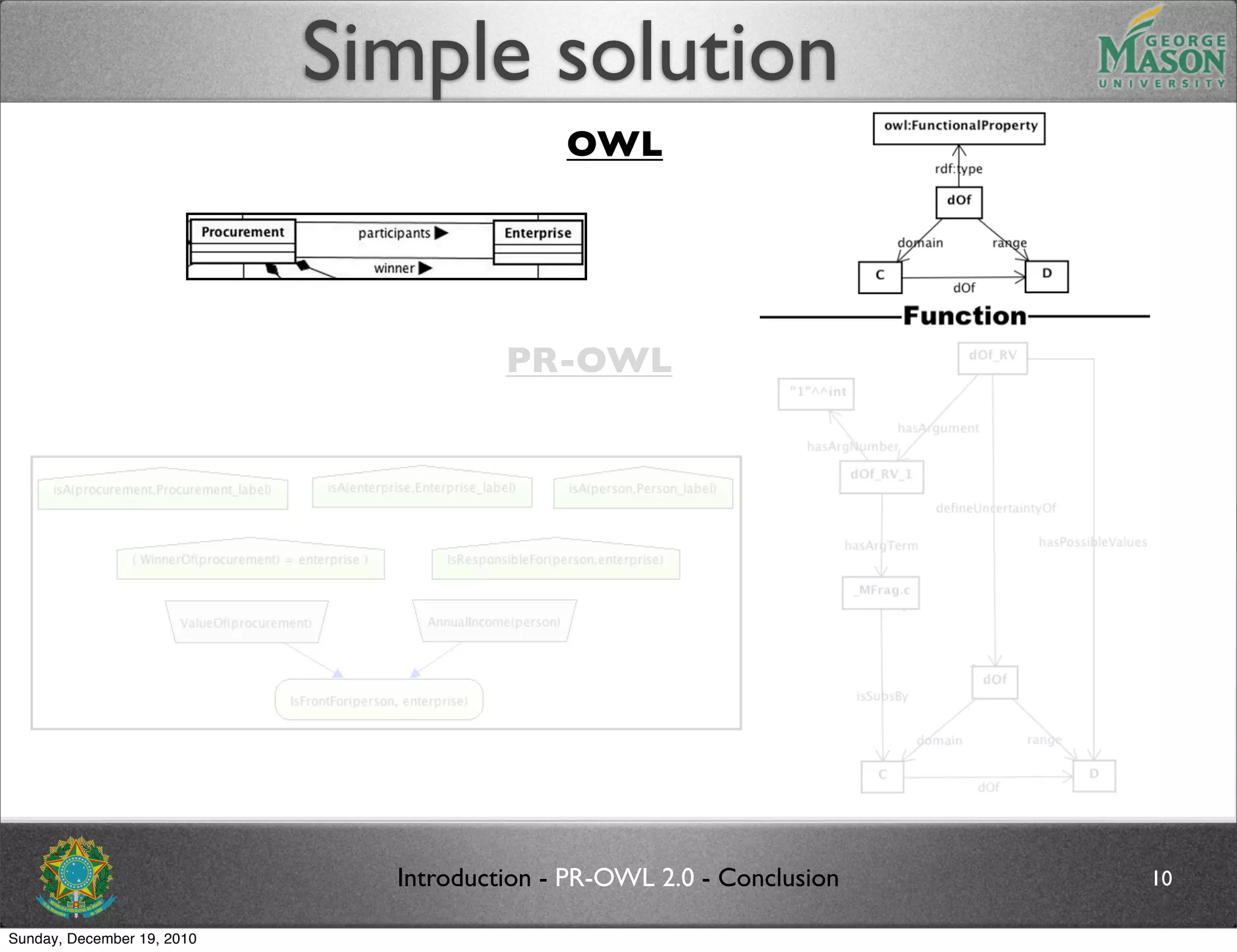
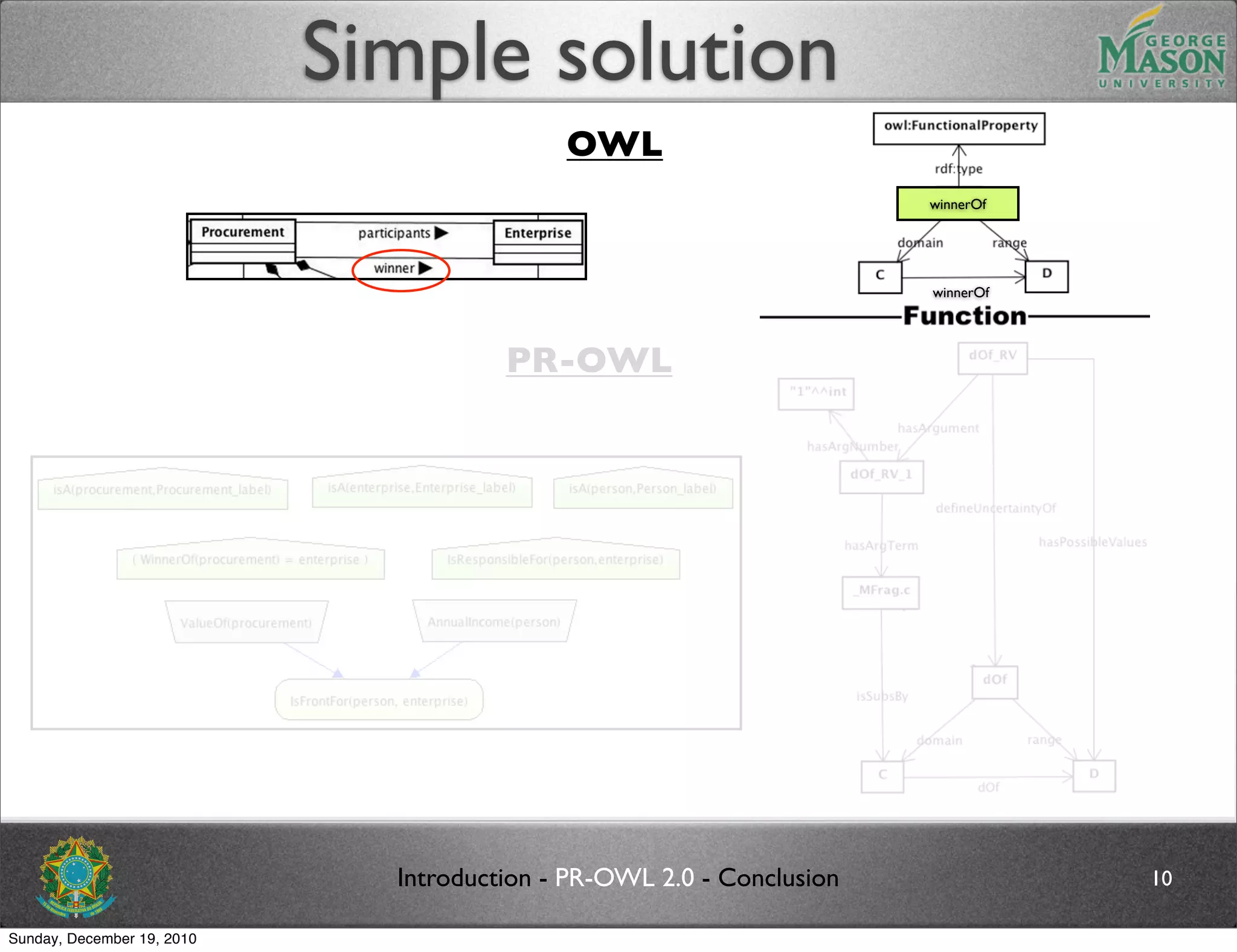
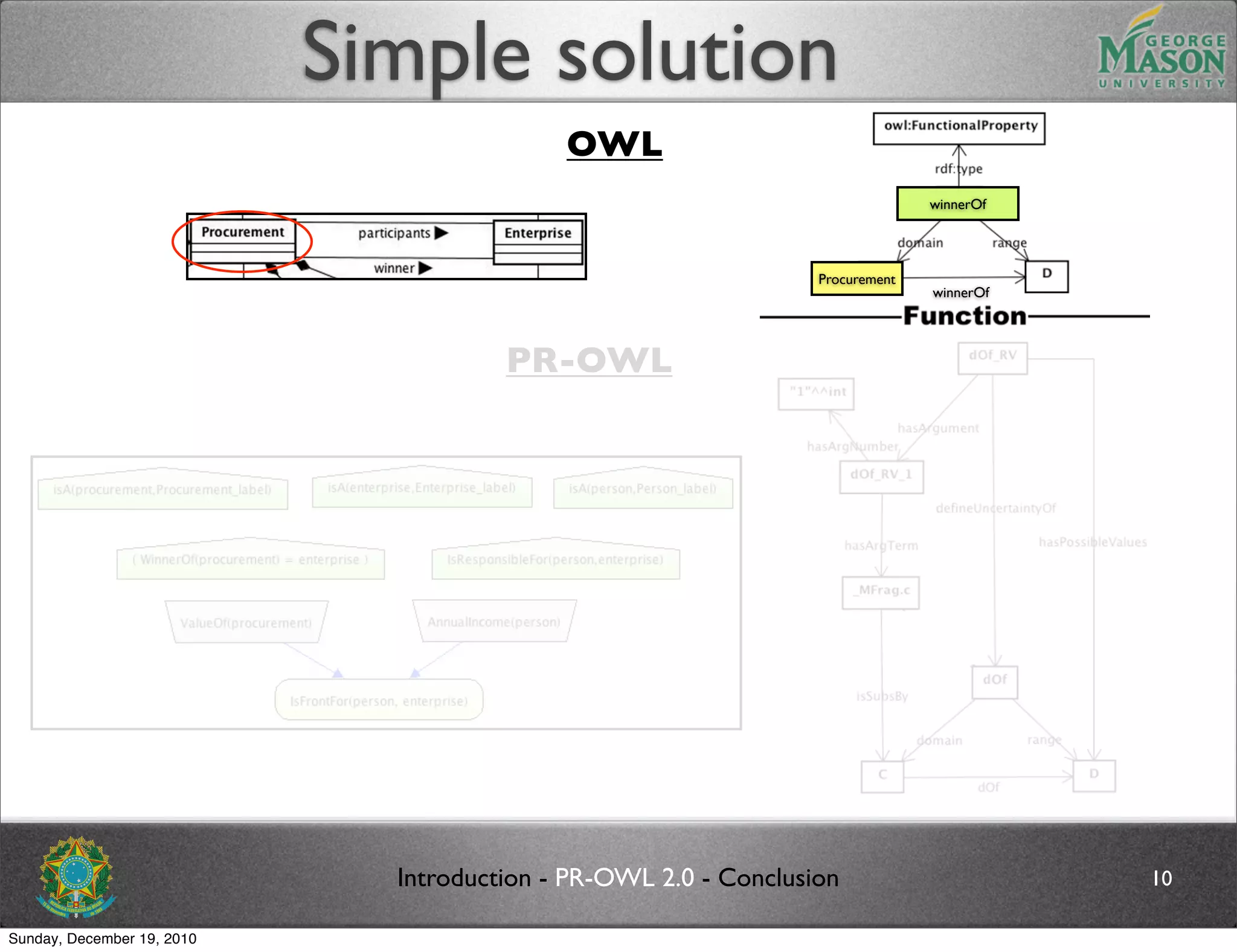
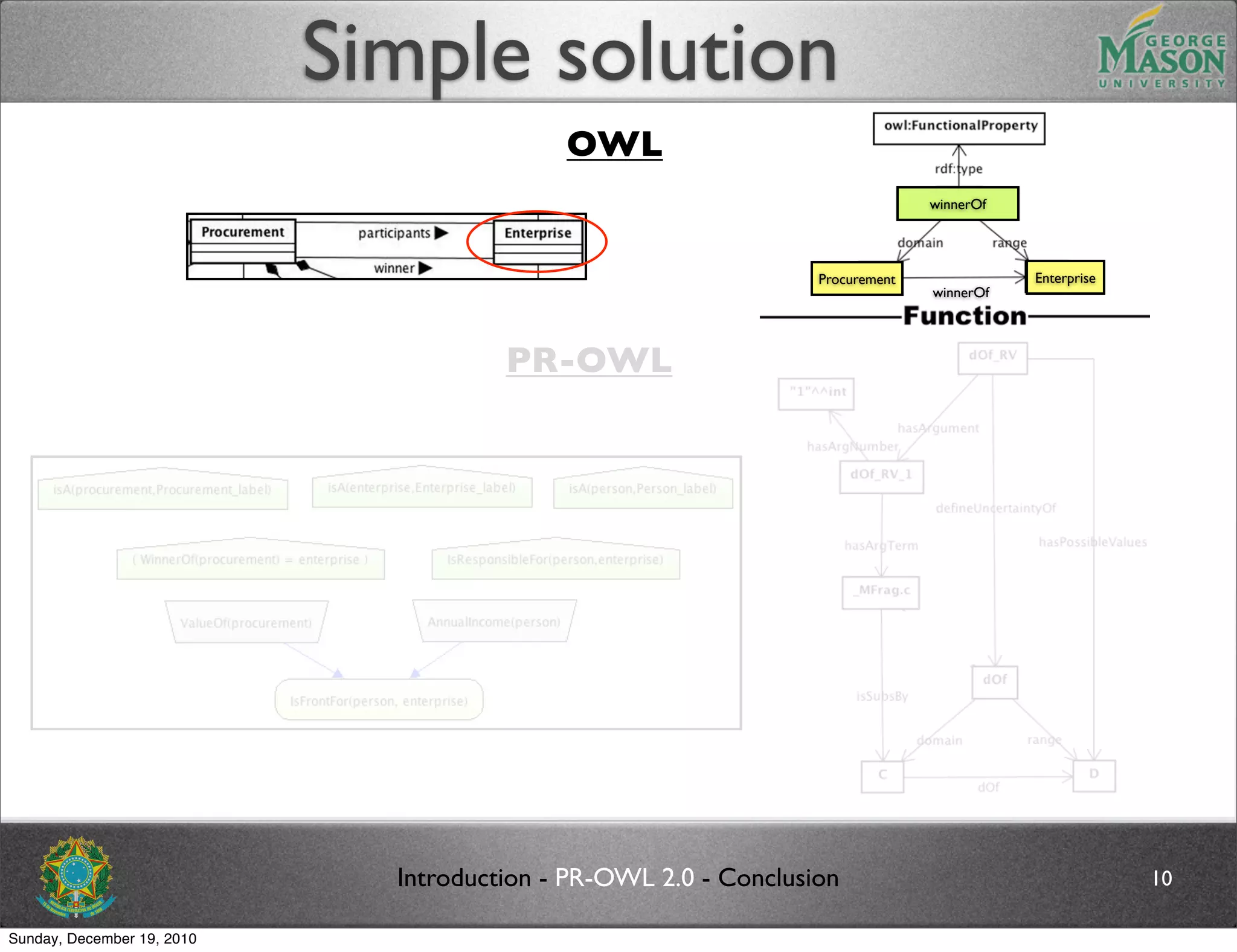
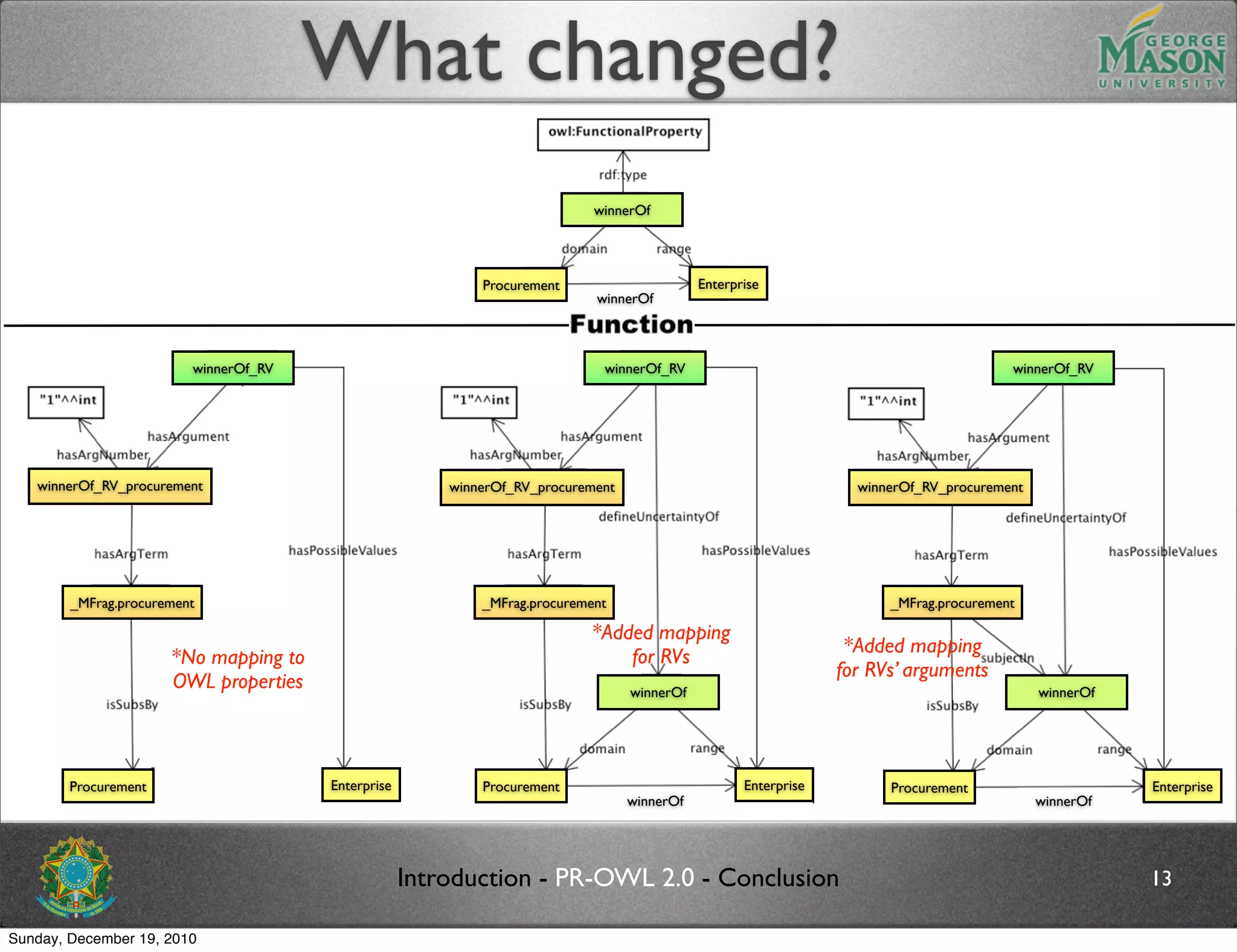
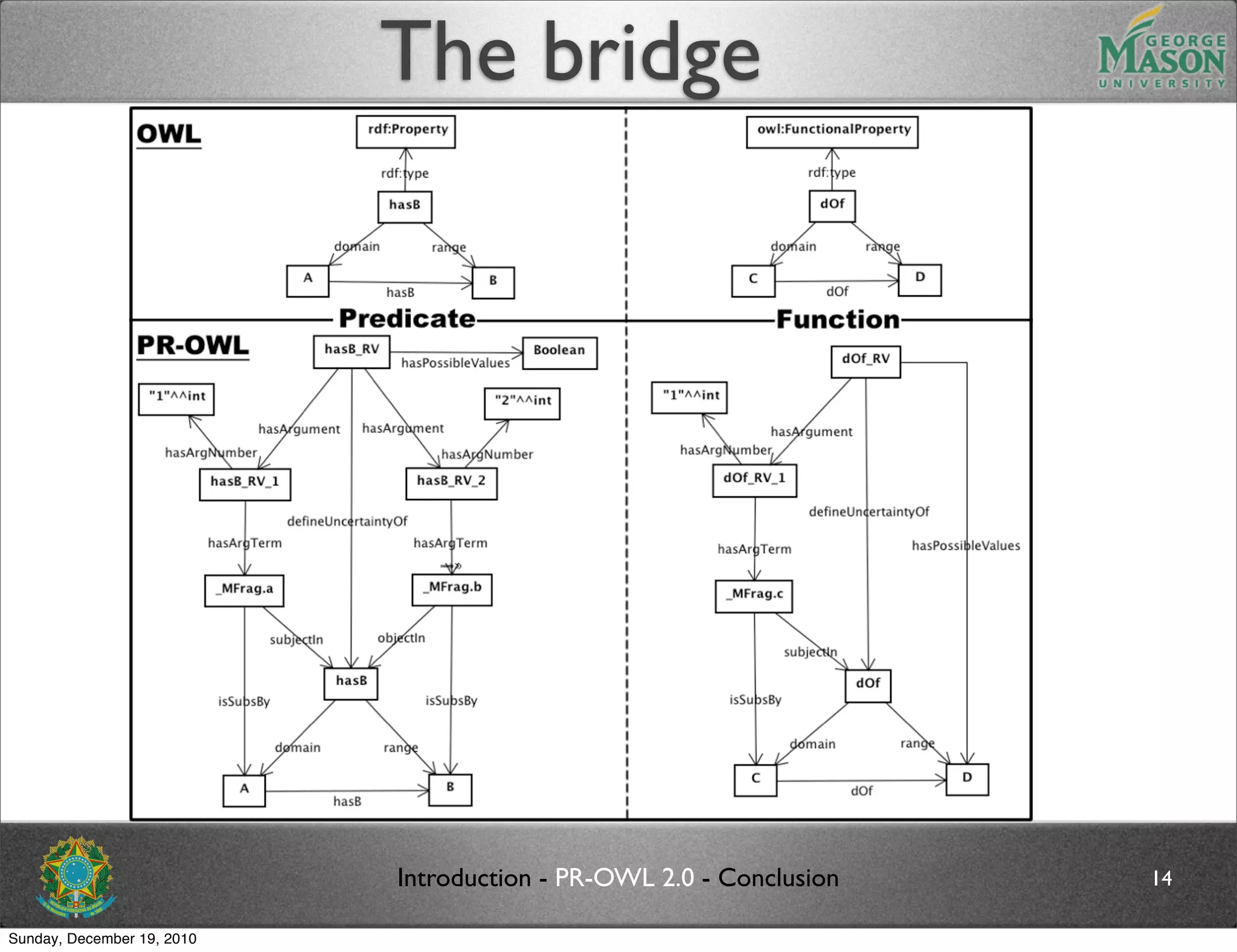











![Future work
Formally define the semantics of the schematic
proposed
Propose an algorithm for performing the mapping
from OWL concepts to PR-OWL RVs, and vice-
versa
In addition, PR-OWL 2 will address other issues
described in [2]
Replace the meta-entity definition in PR-OWL
Use of existing types in OWL, RDF(S), and XML as
possible values for RVs (including data types)
Introduction - PR-OWL 2.0 - Conclusion 17
Sunday, December 19, 2010](https://image.slidesharecdn.com/ursw2010-carvalhoetal-101219161951-phpapp02/75/PR-OWL-2-0-Bridging-the-gap-to-OWL-semantics-68-2048.jpg)


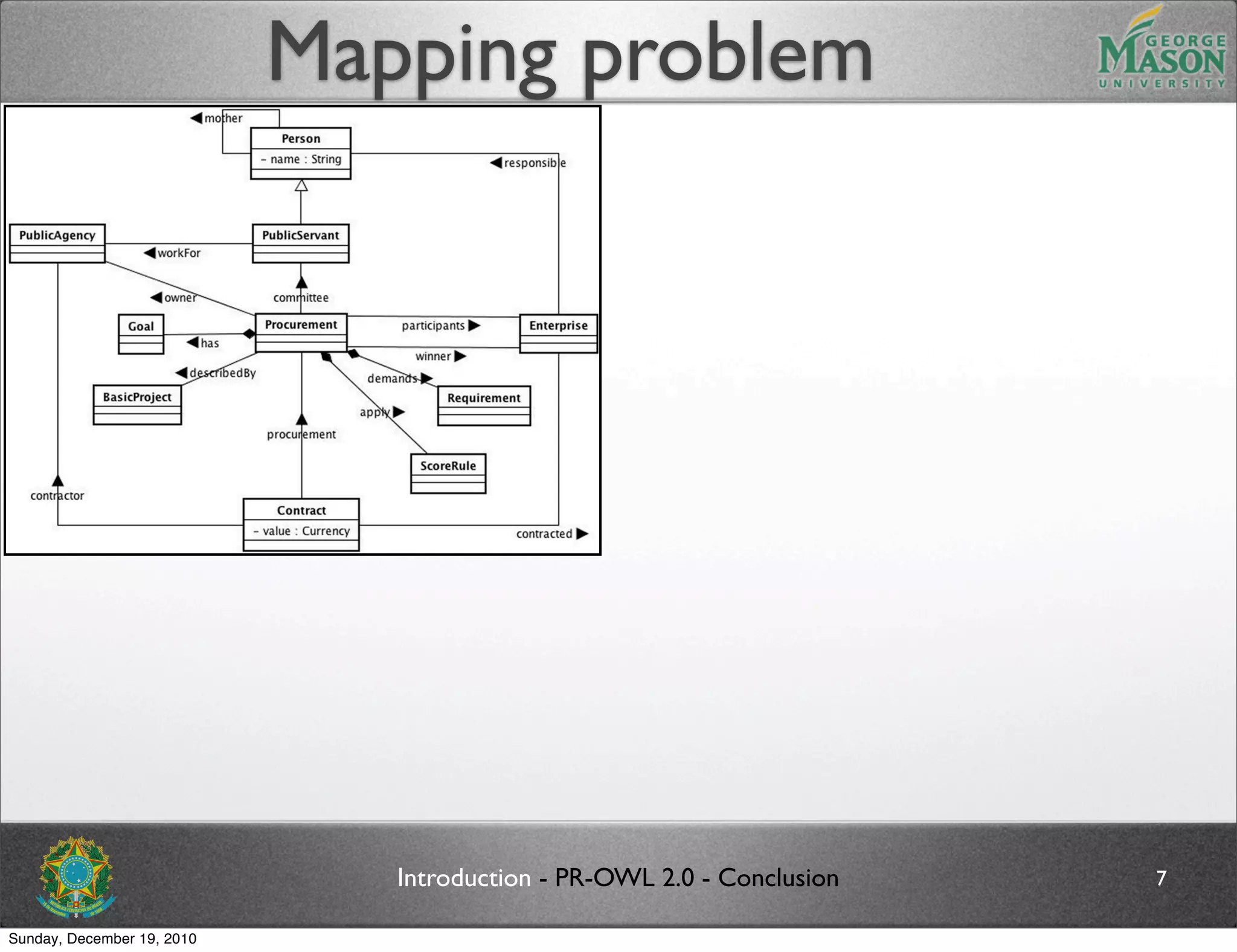
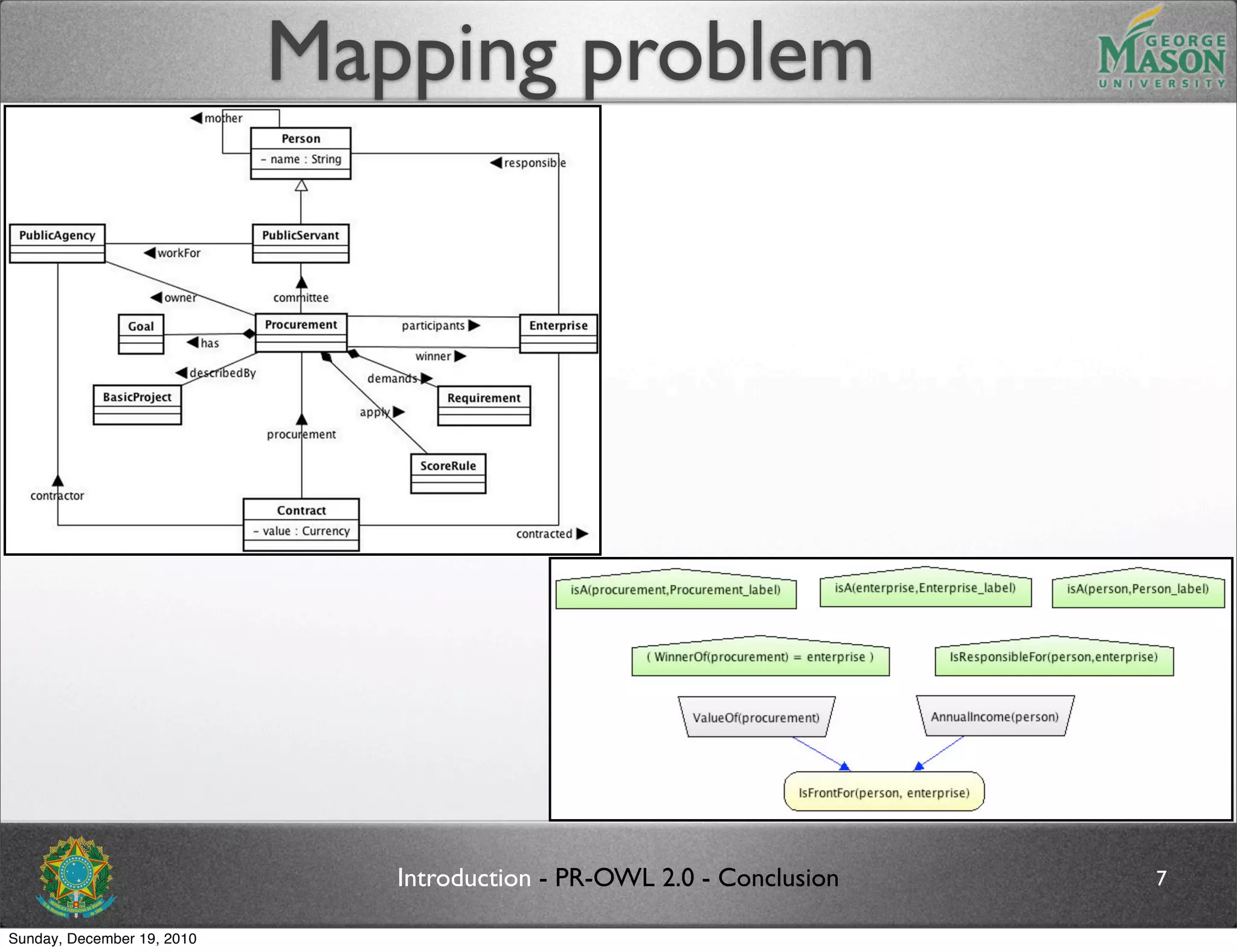
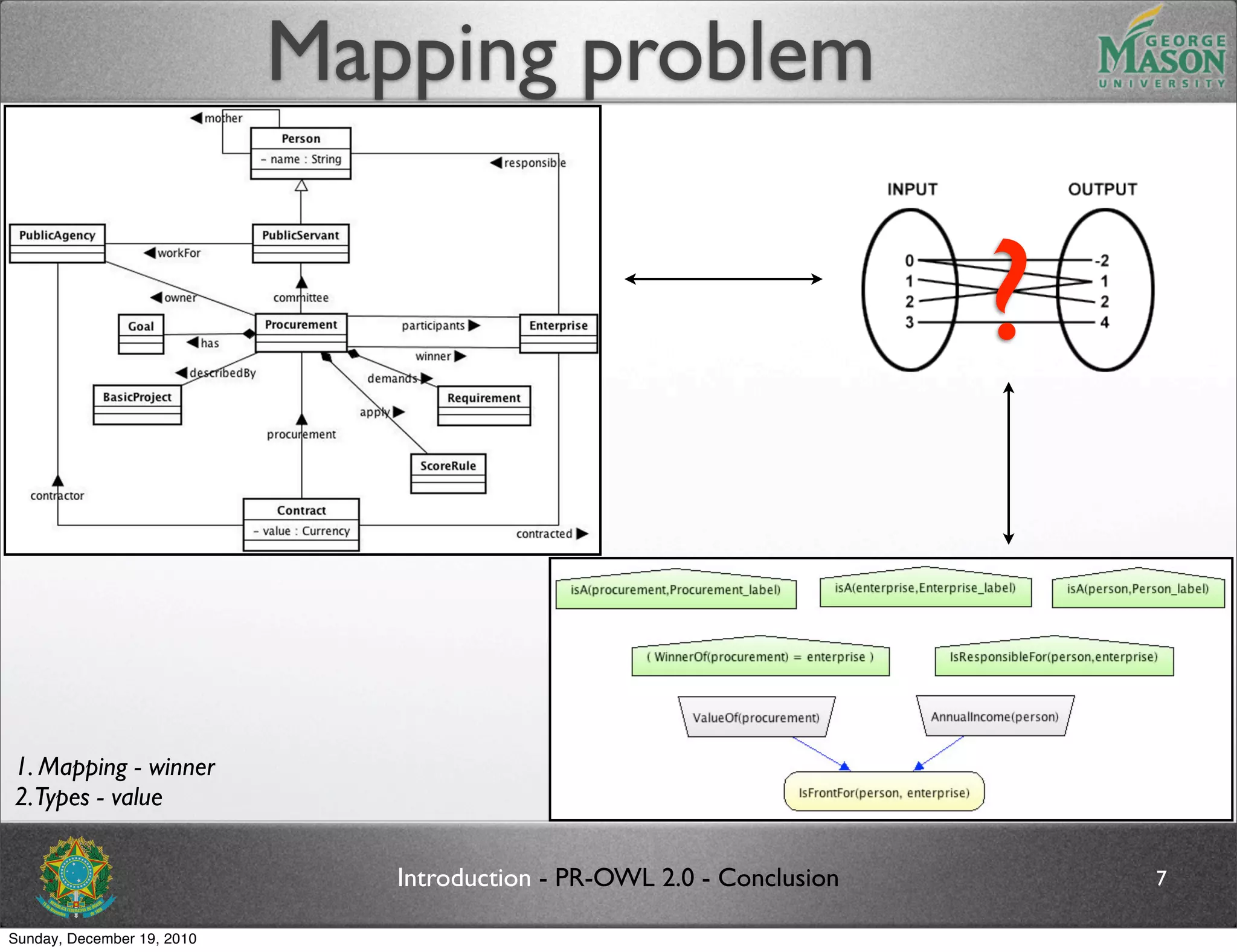
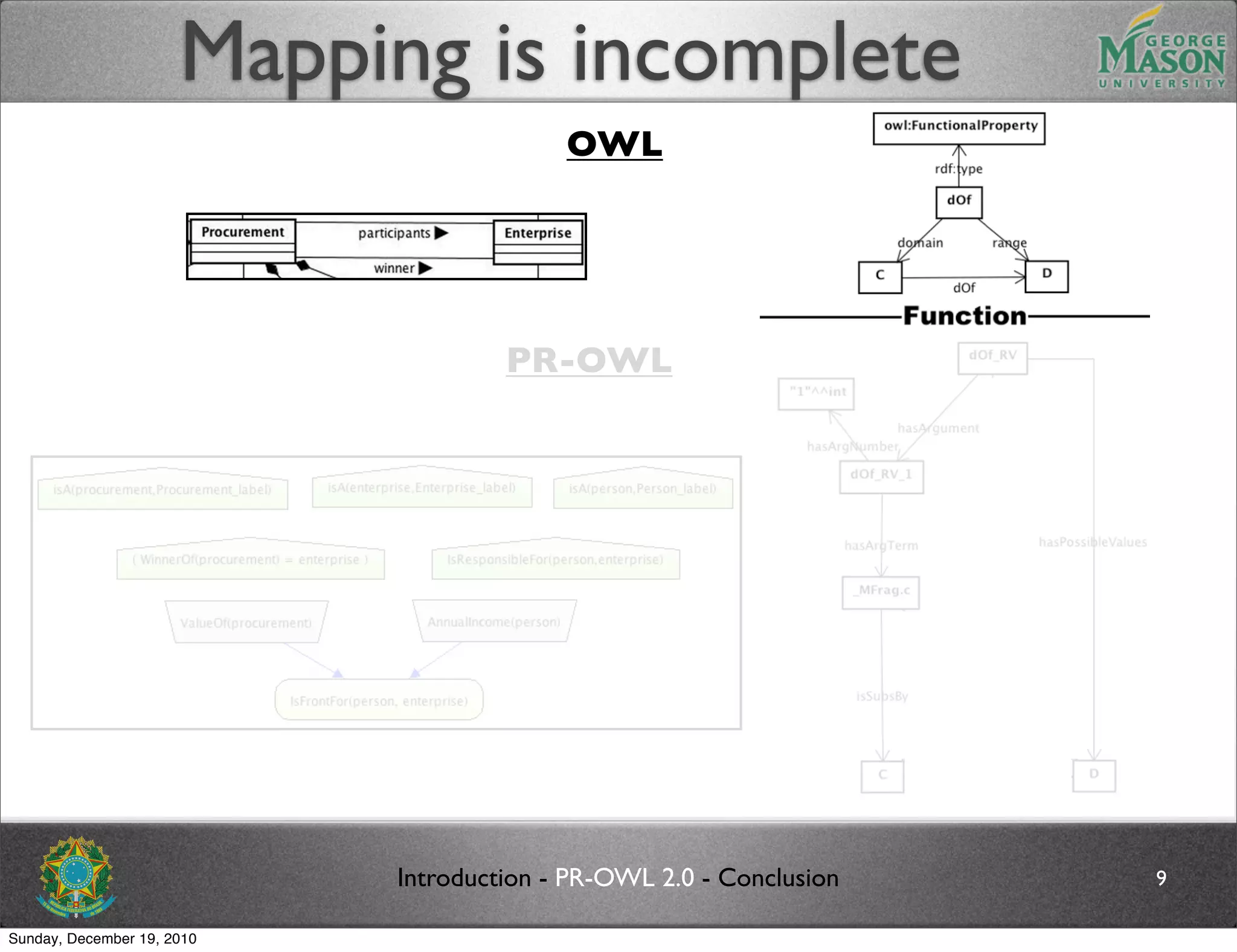
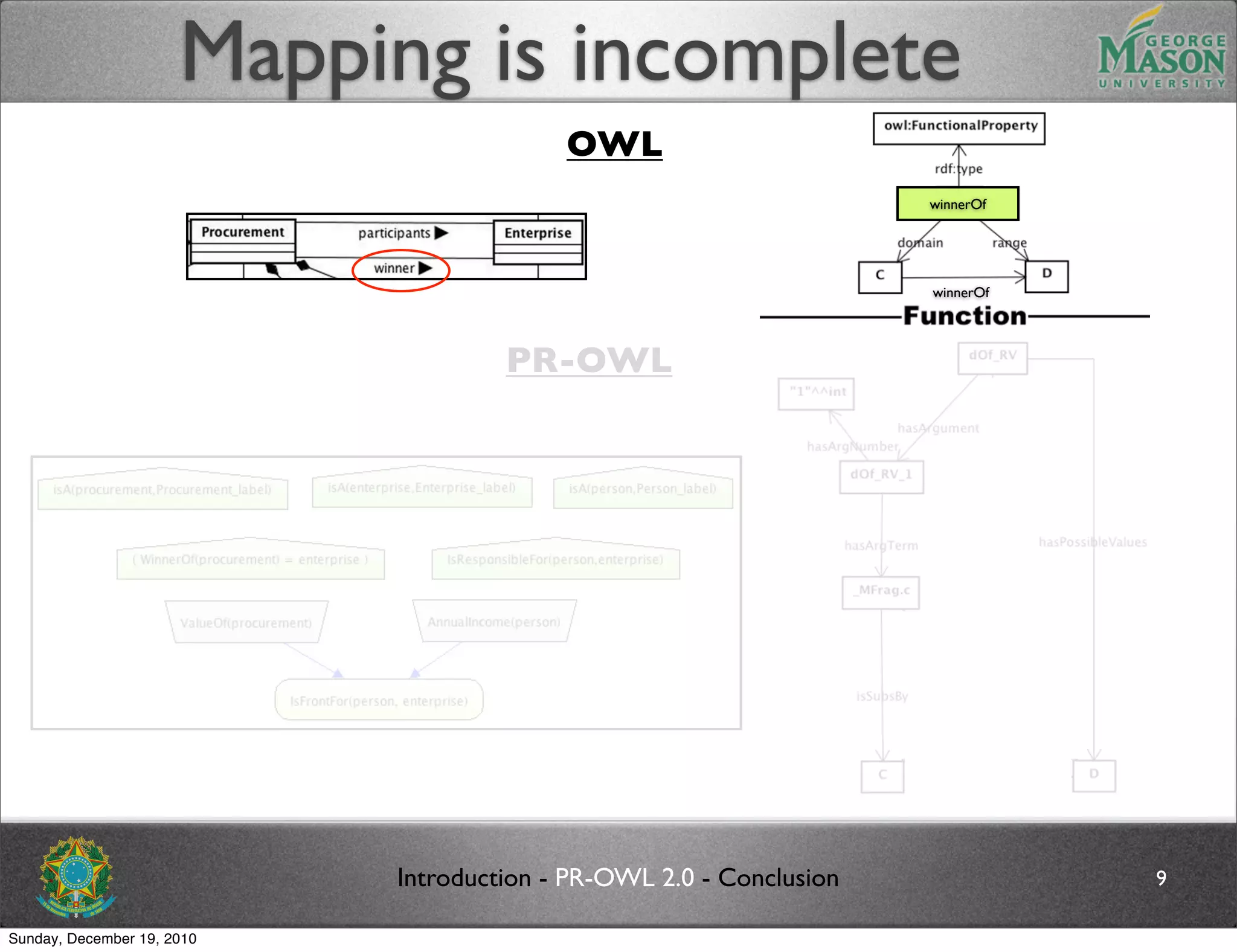
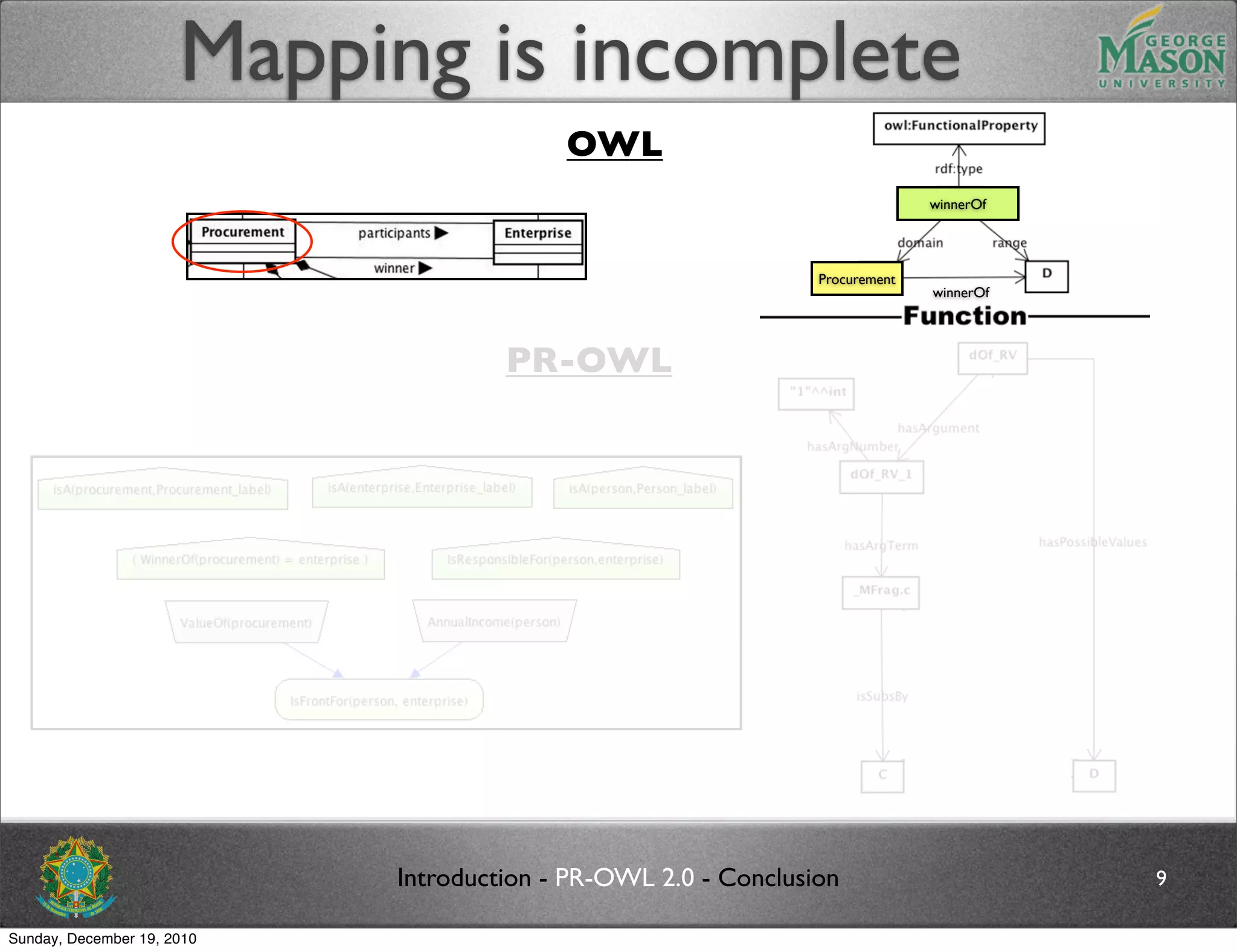
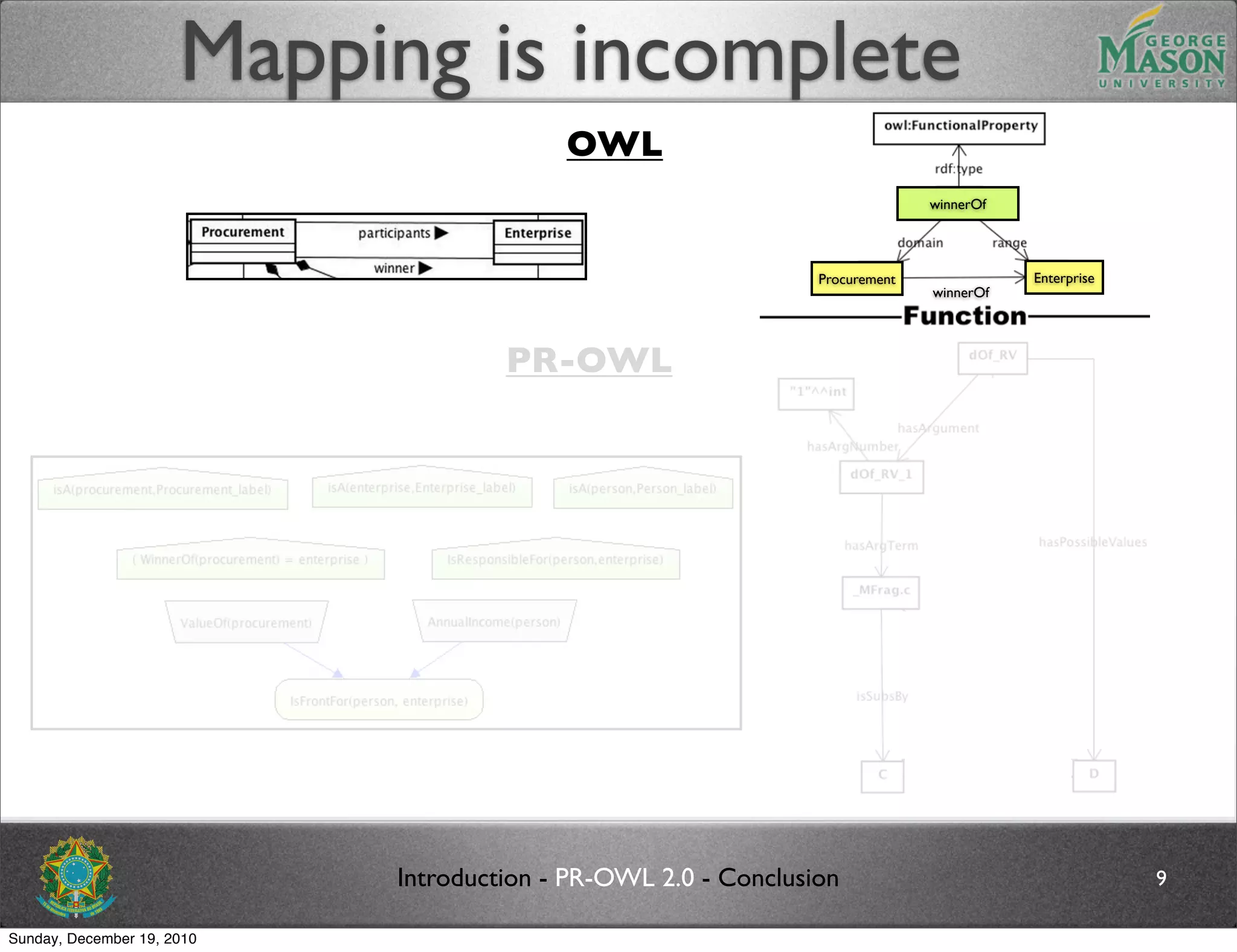
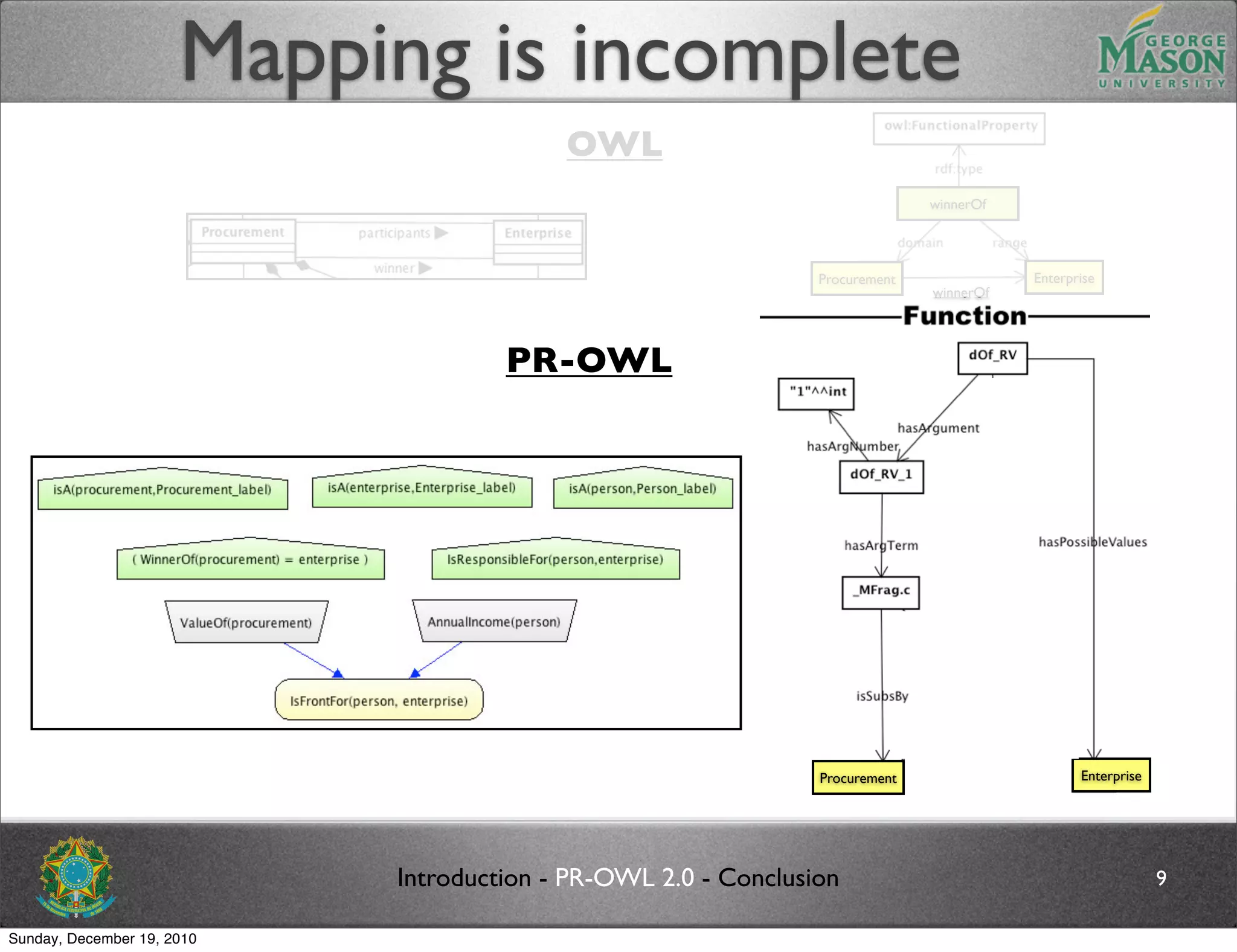
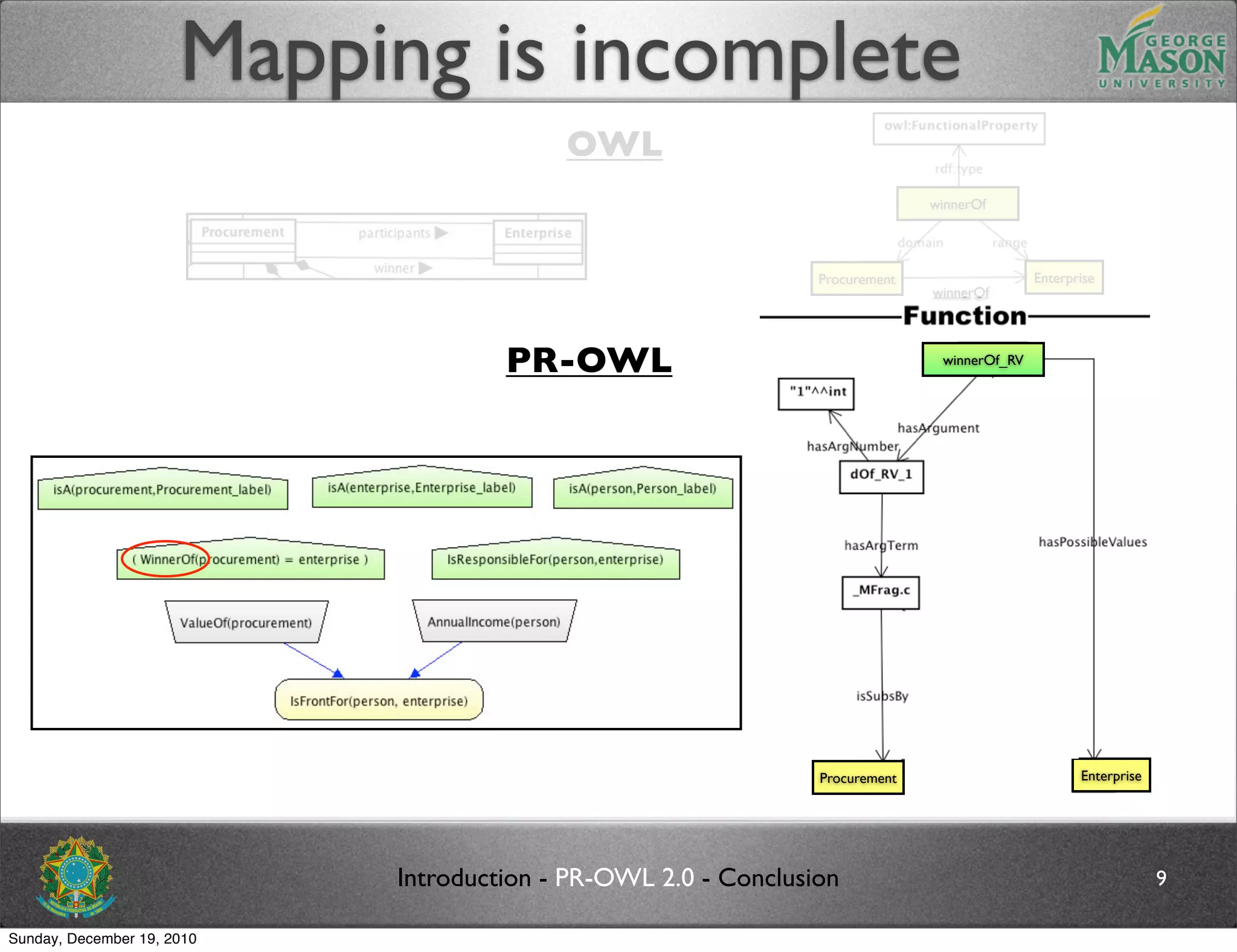
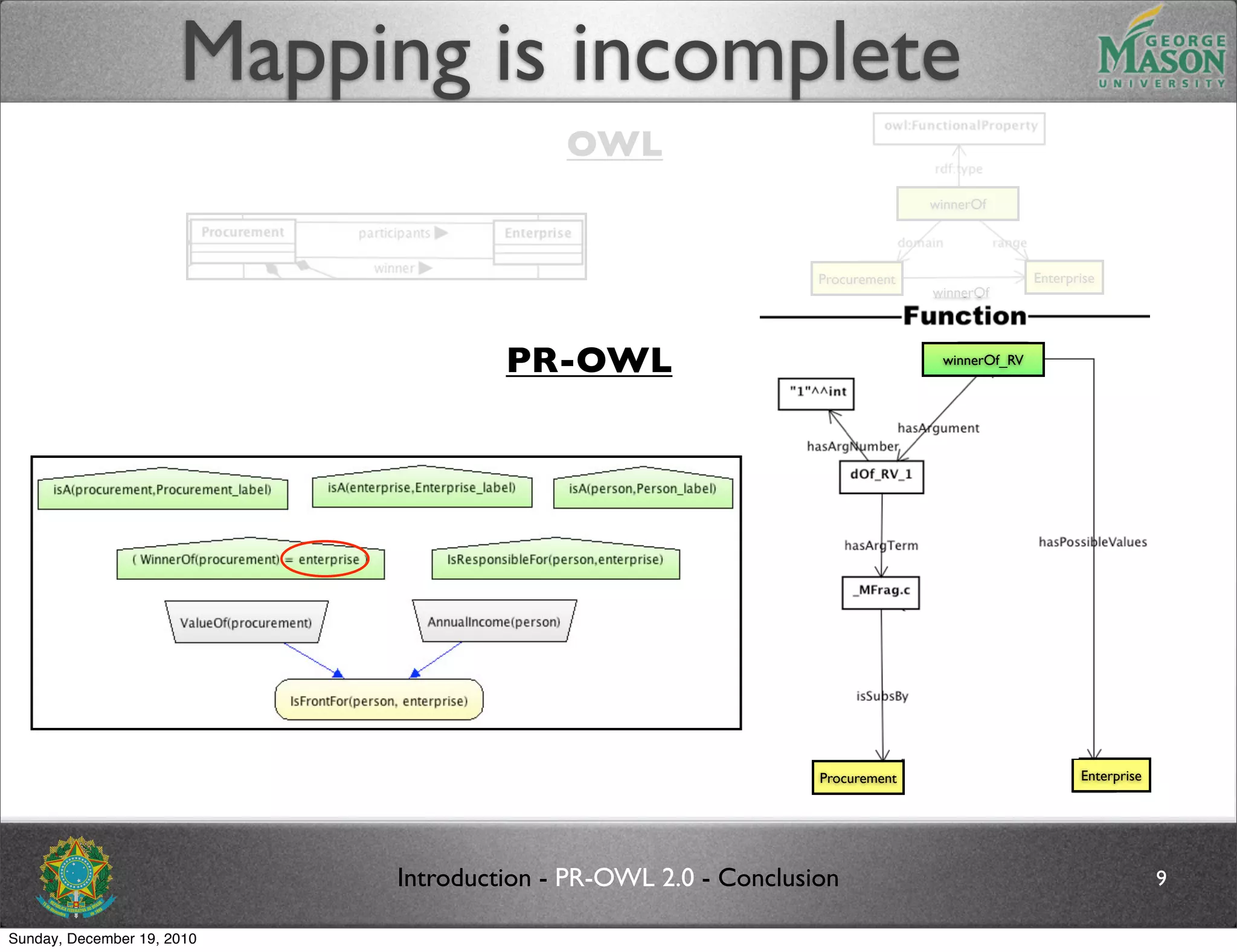
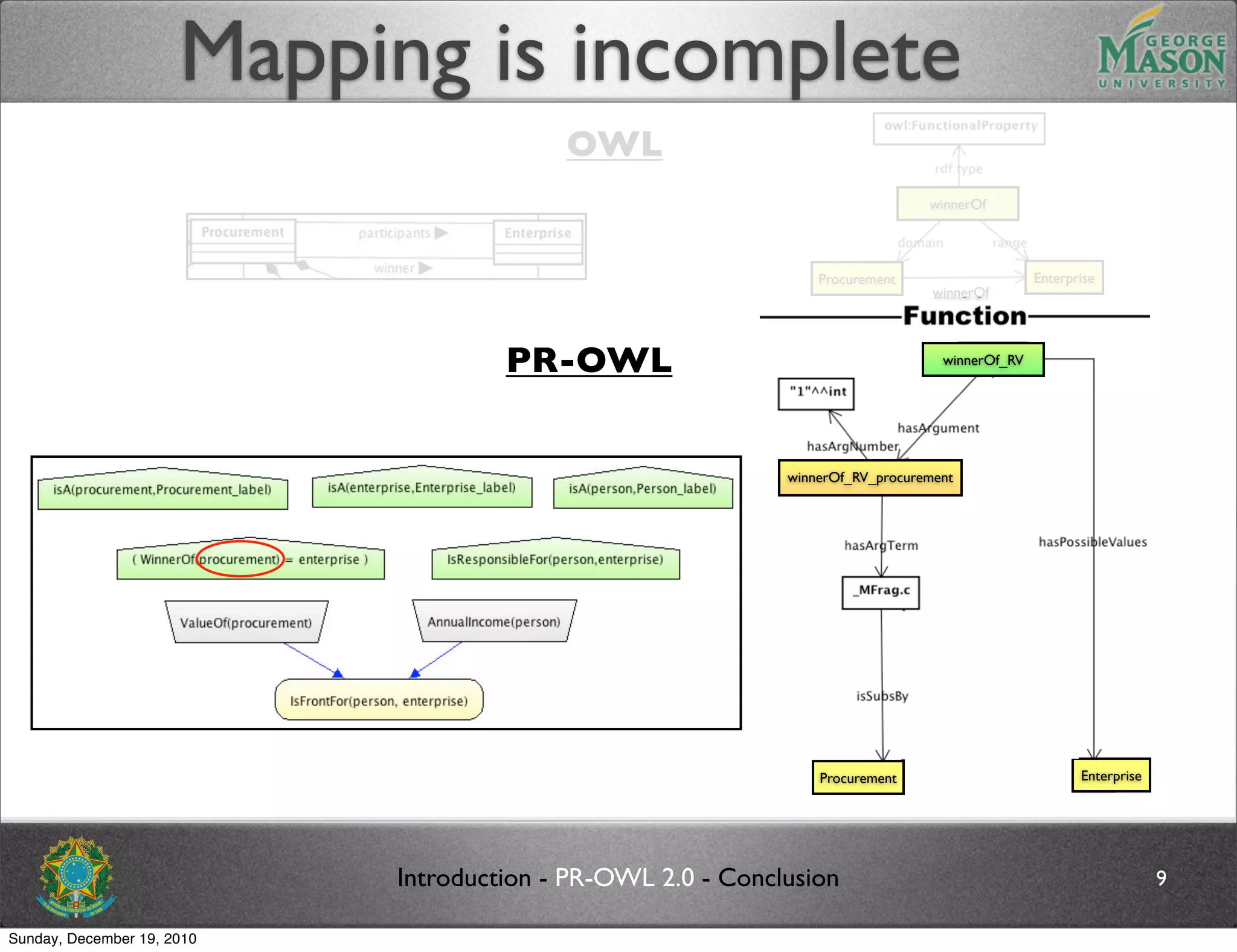
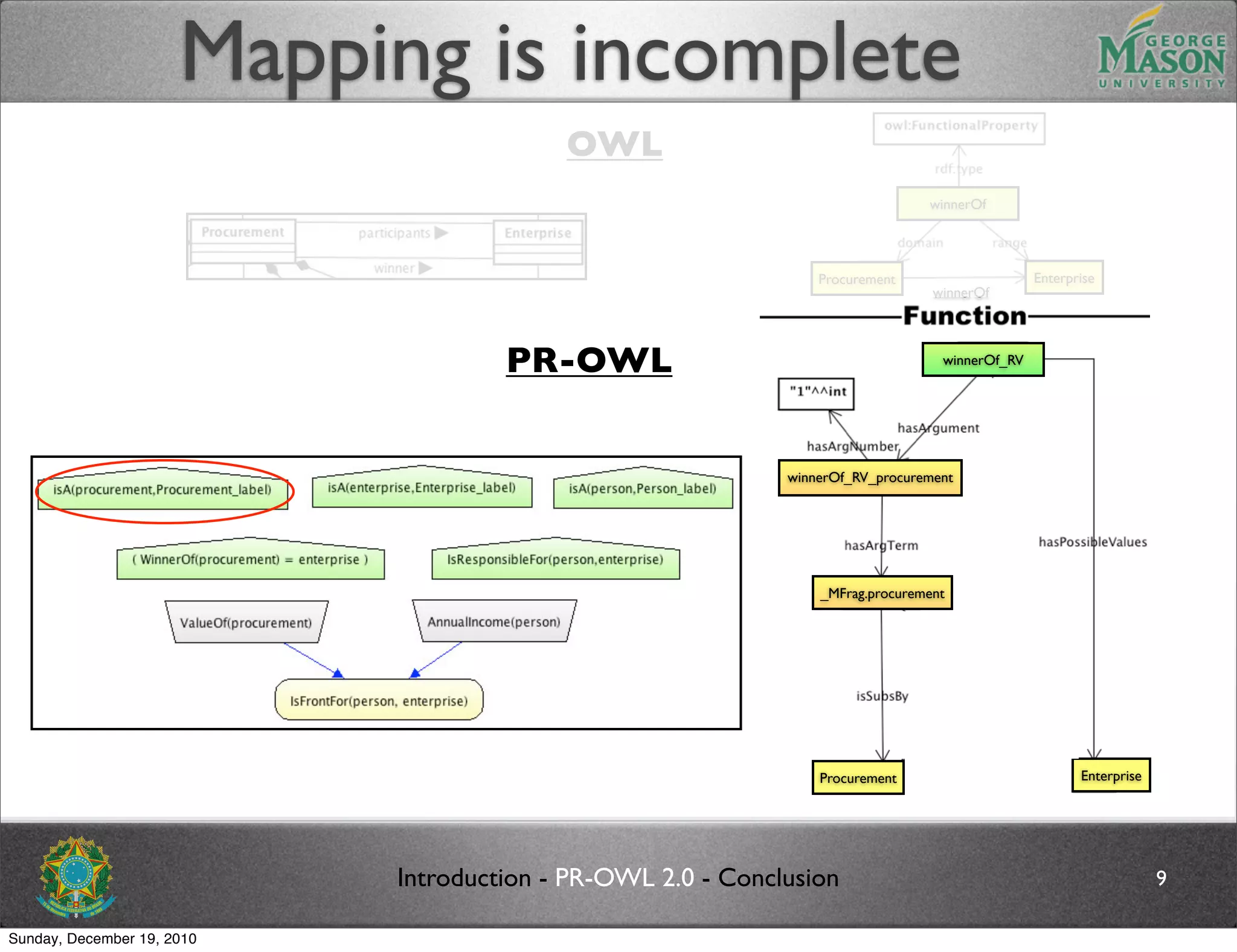
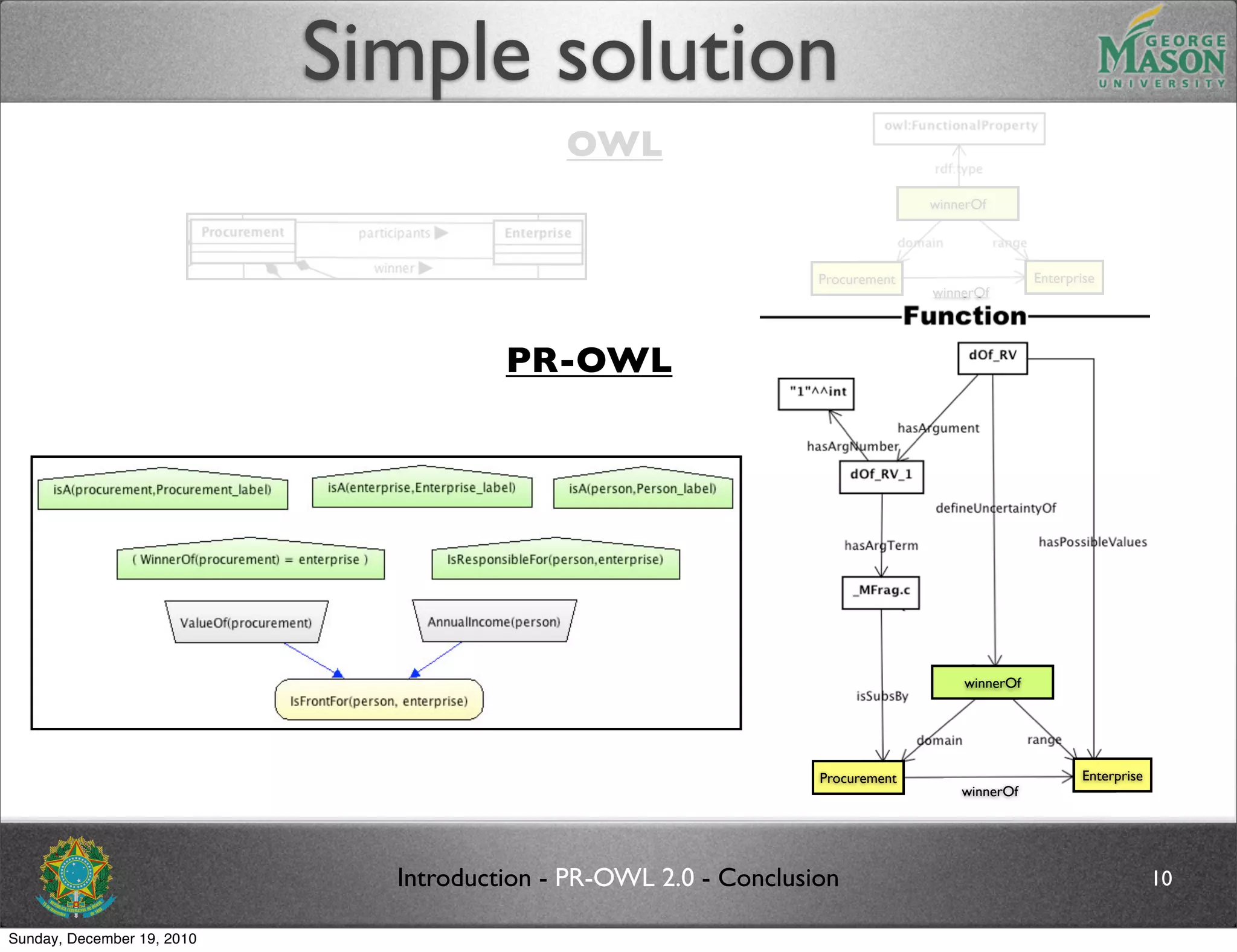
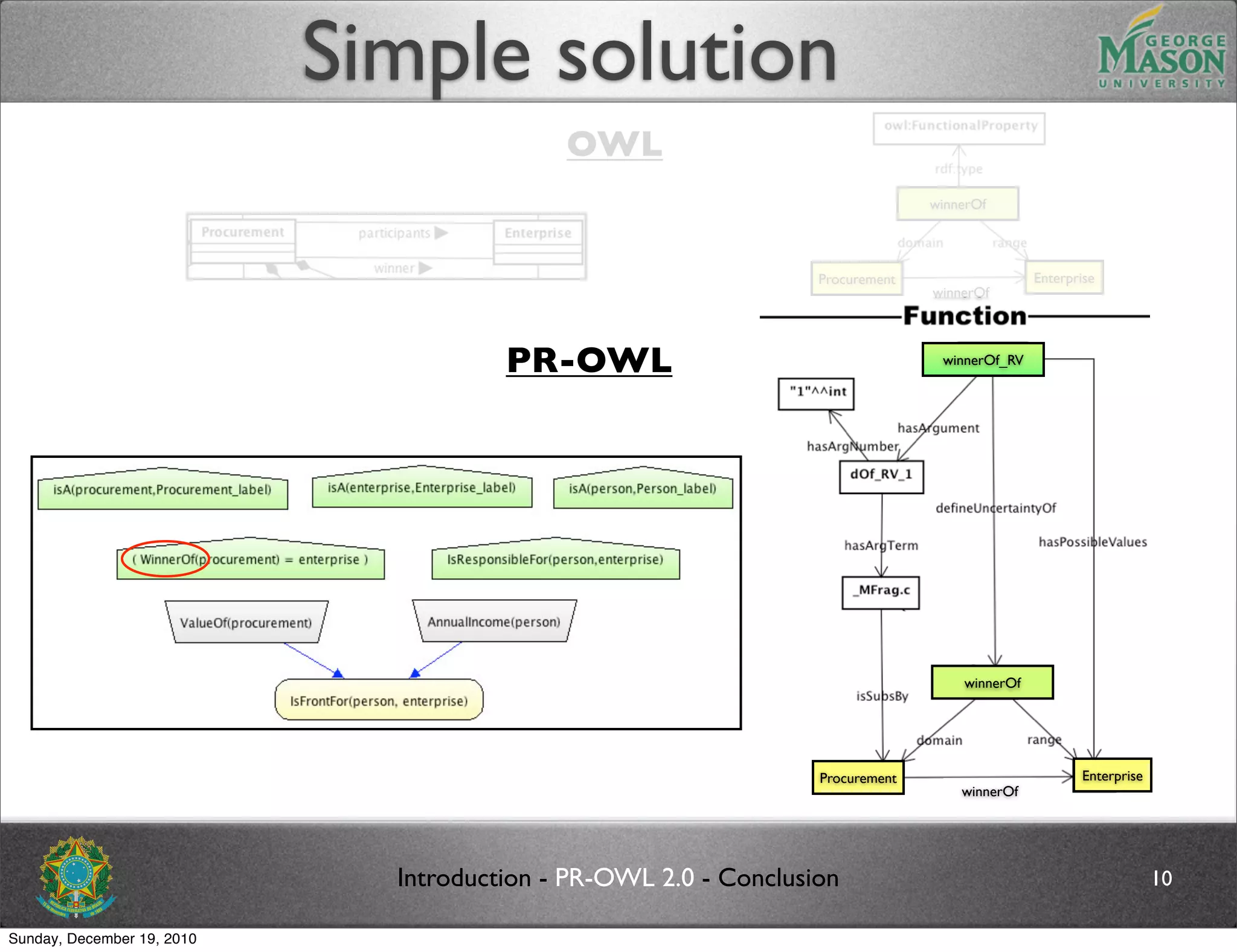
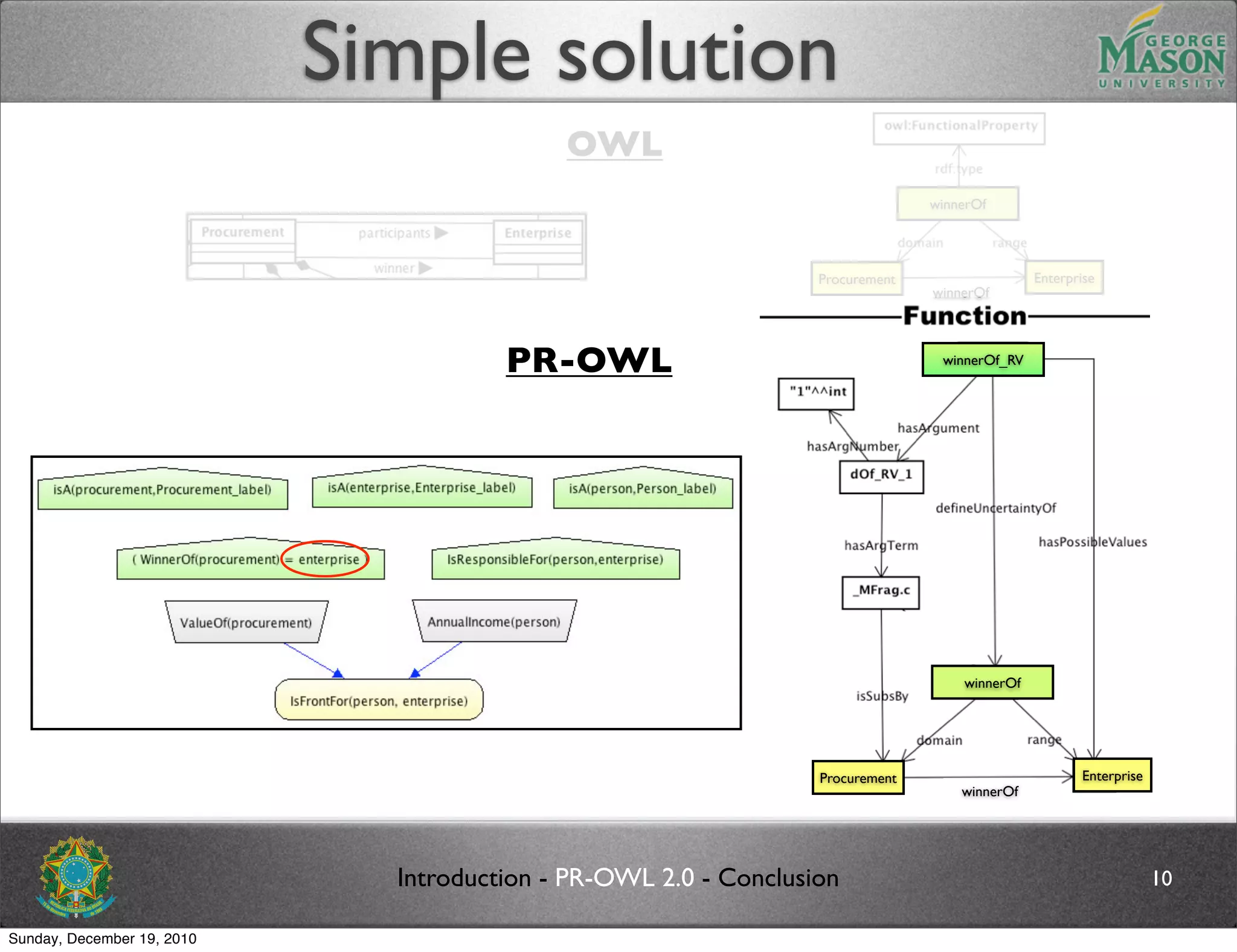
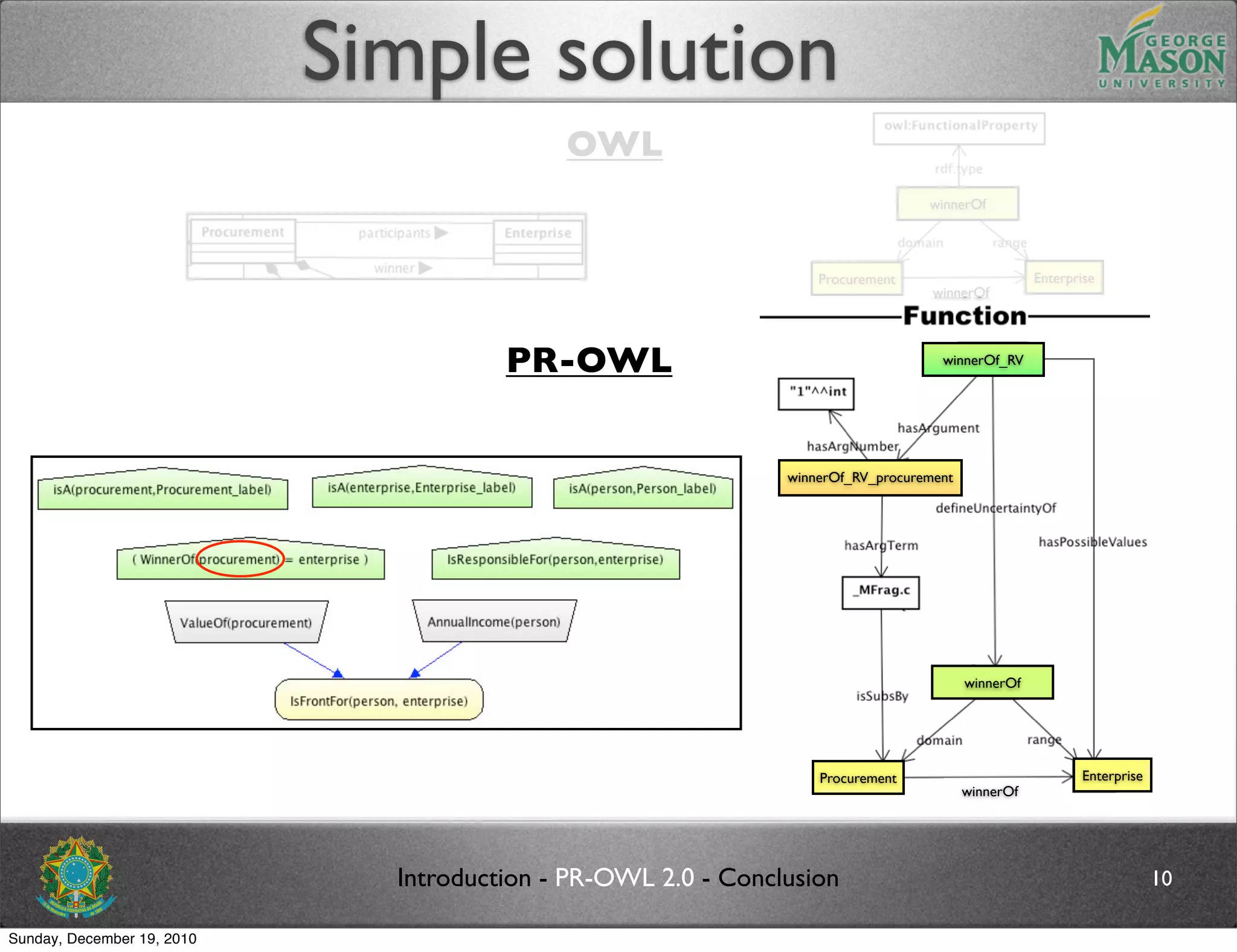
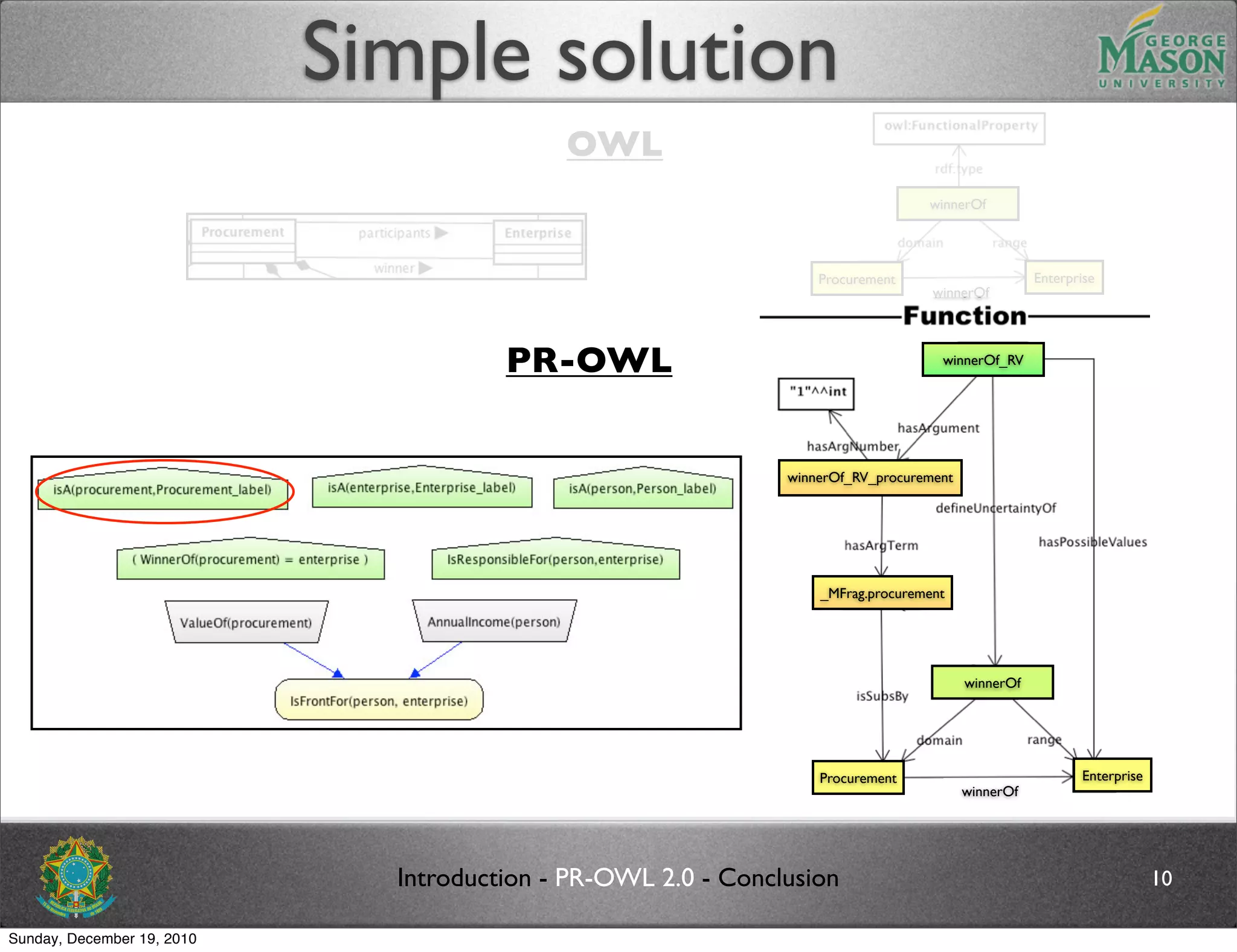
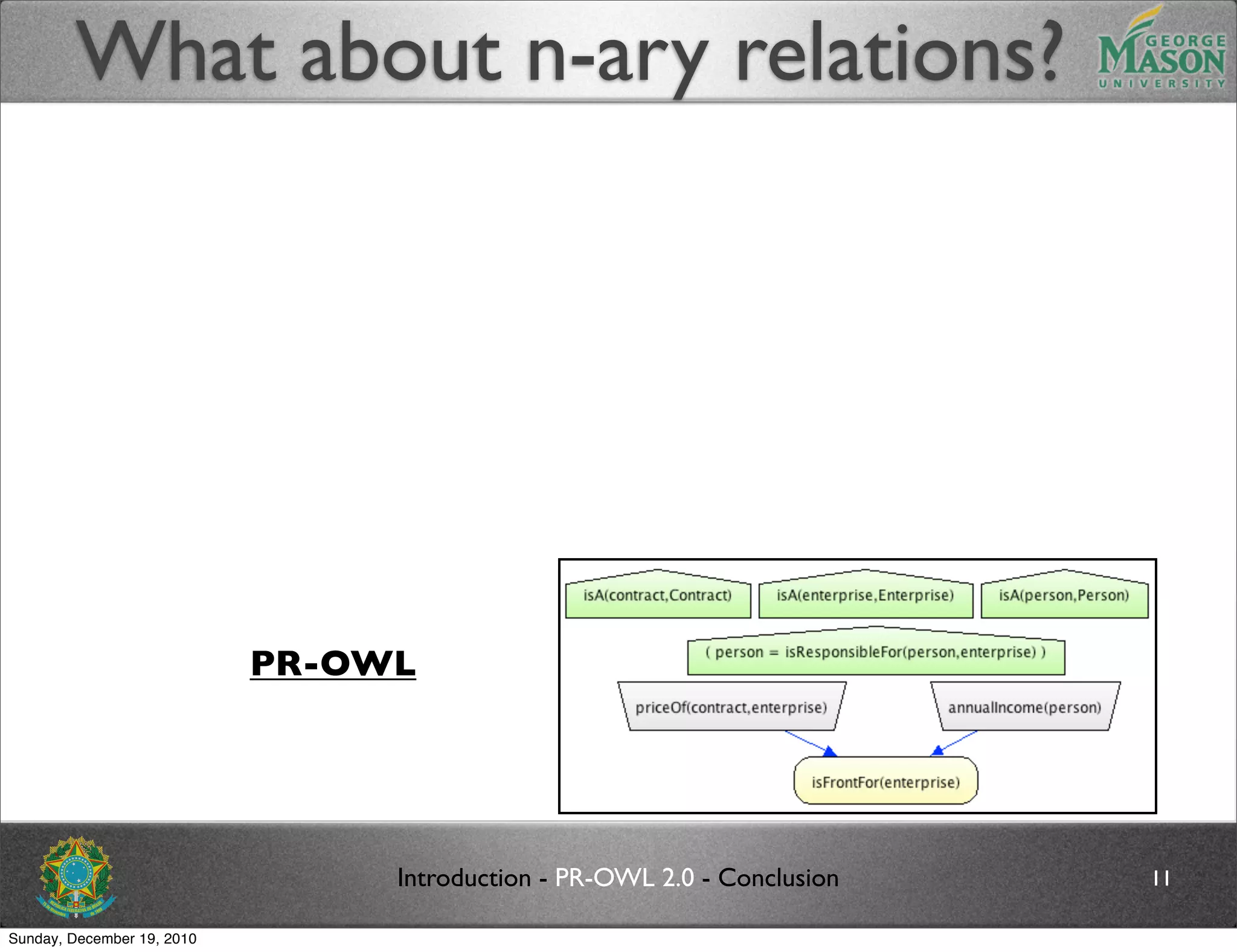
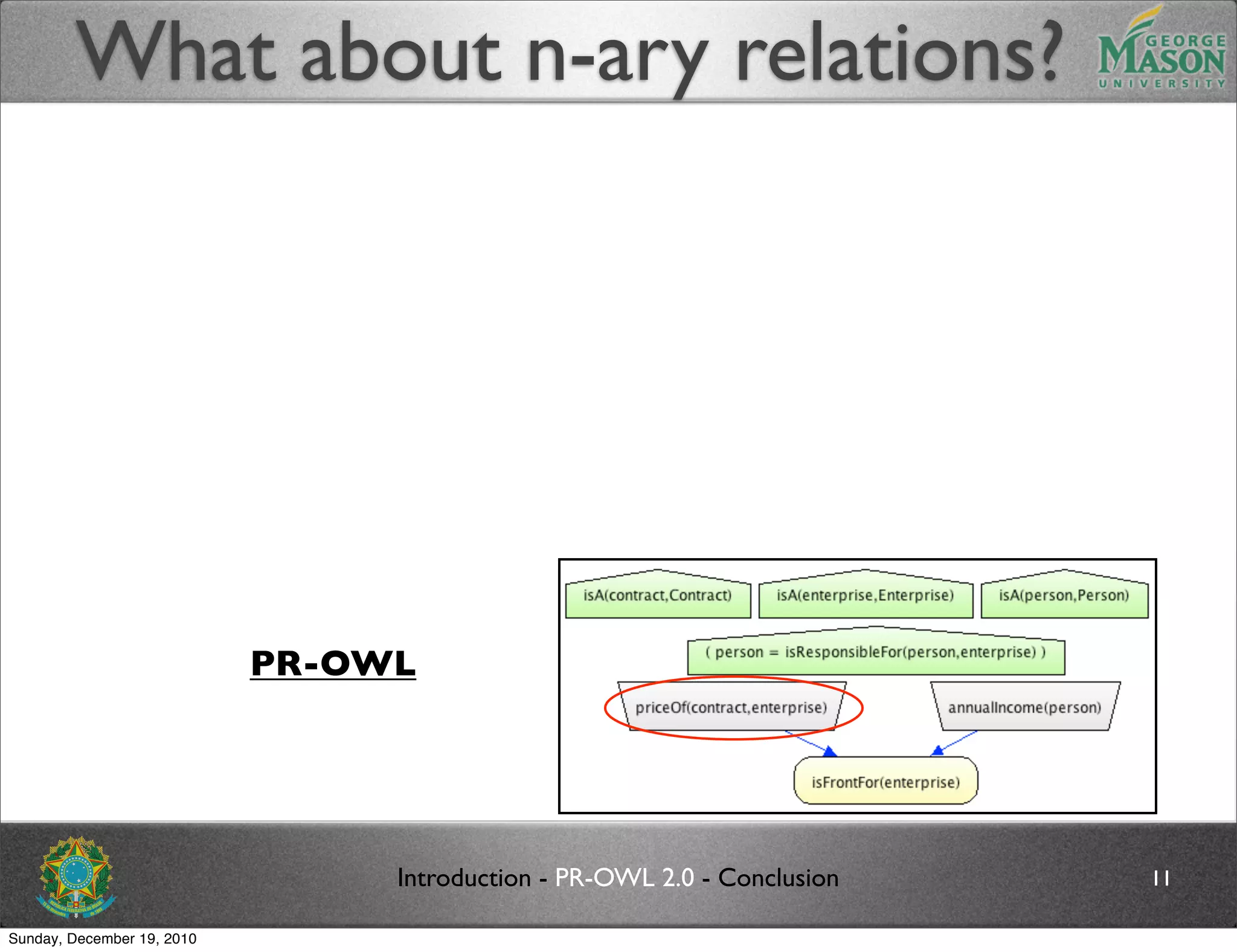
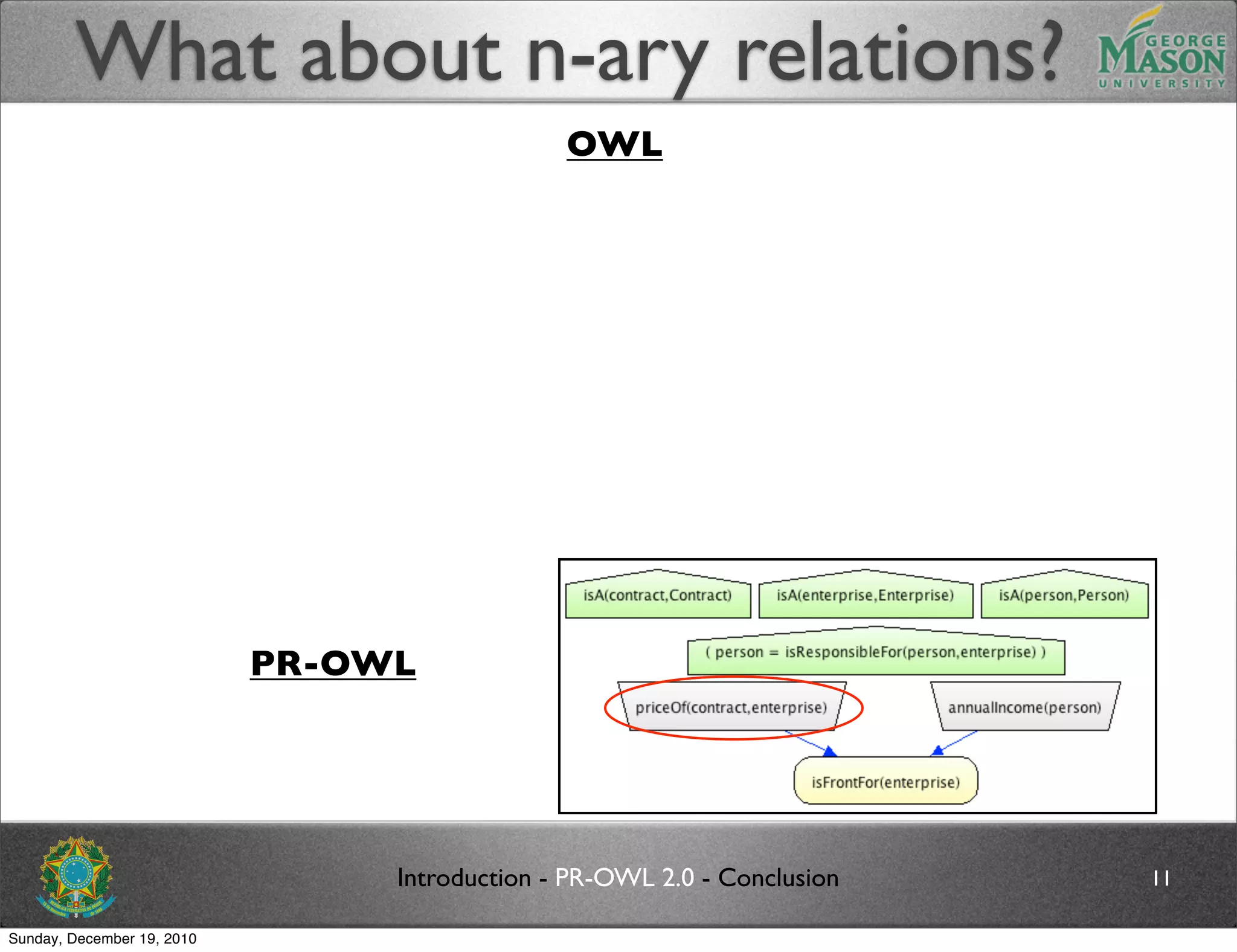
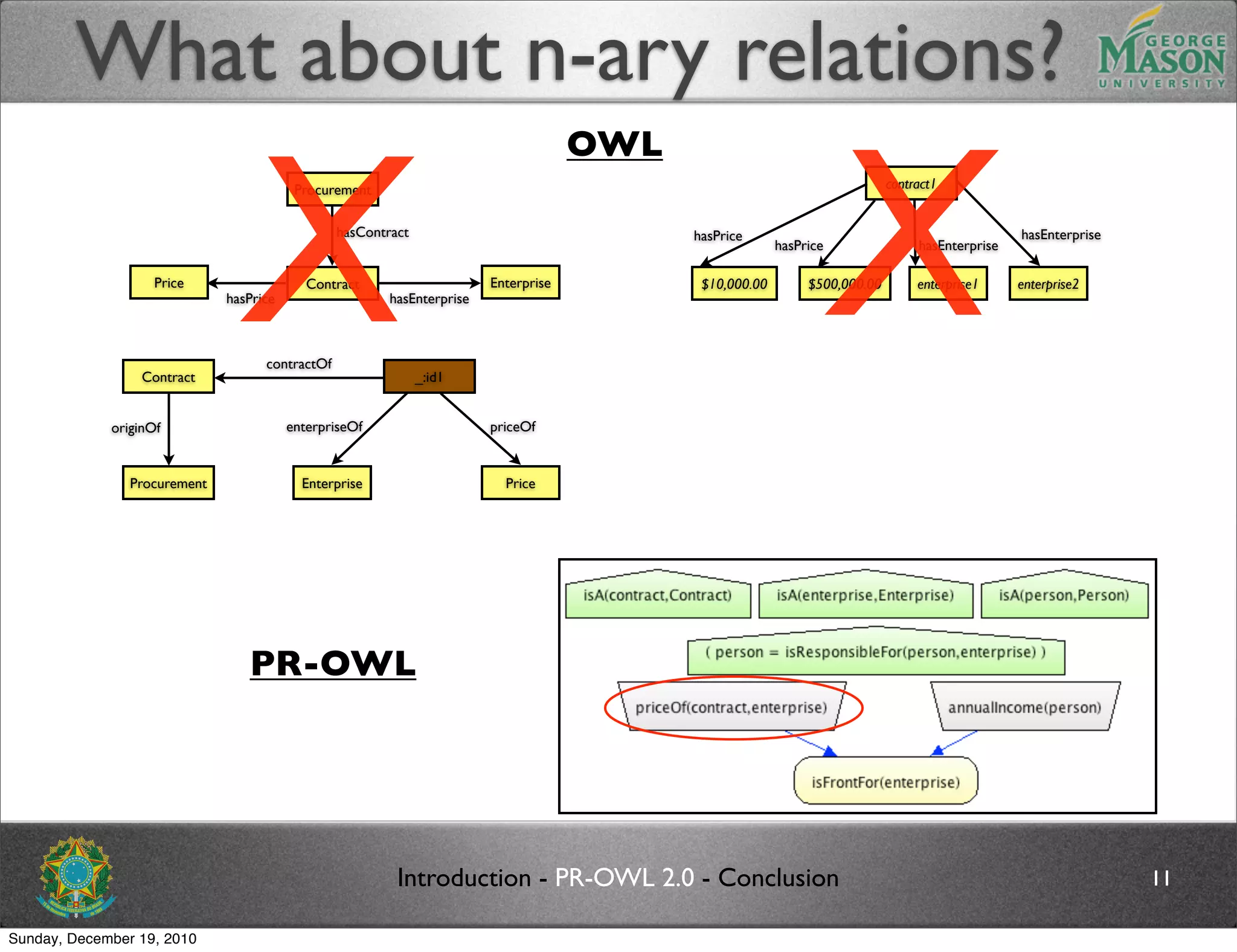
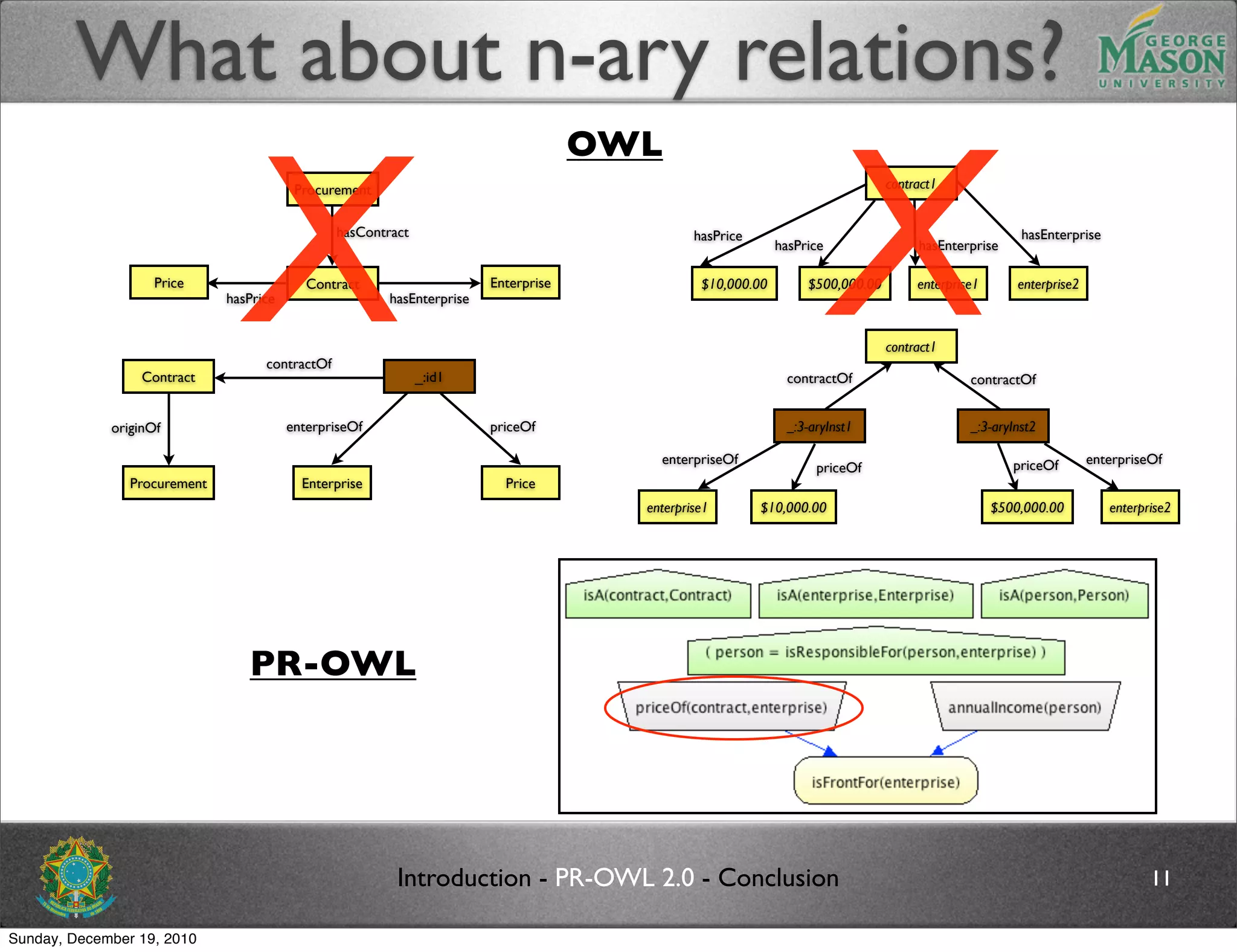
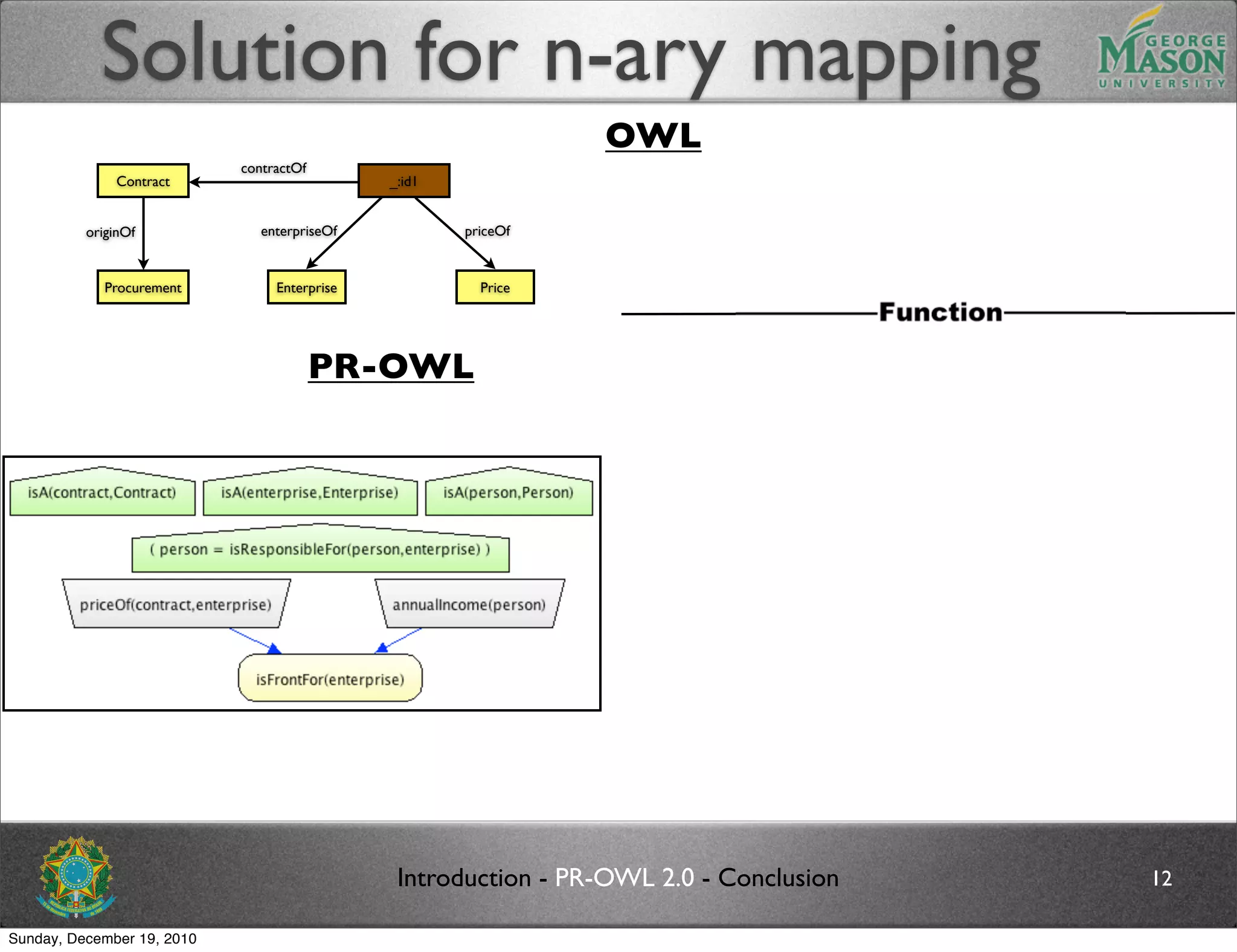
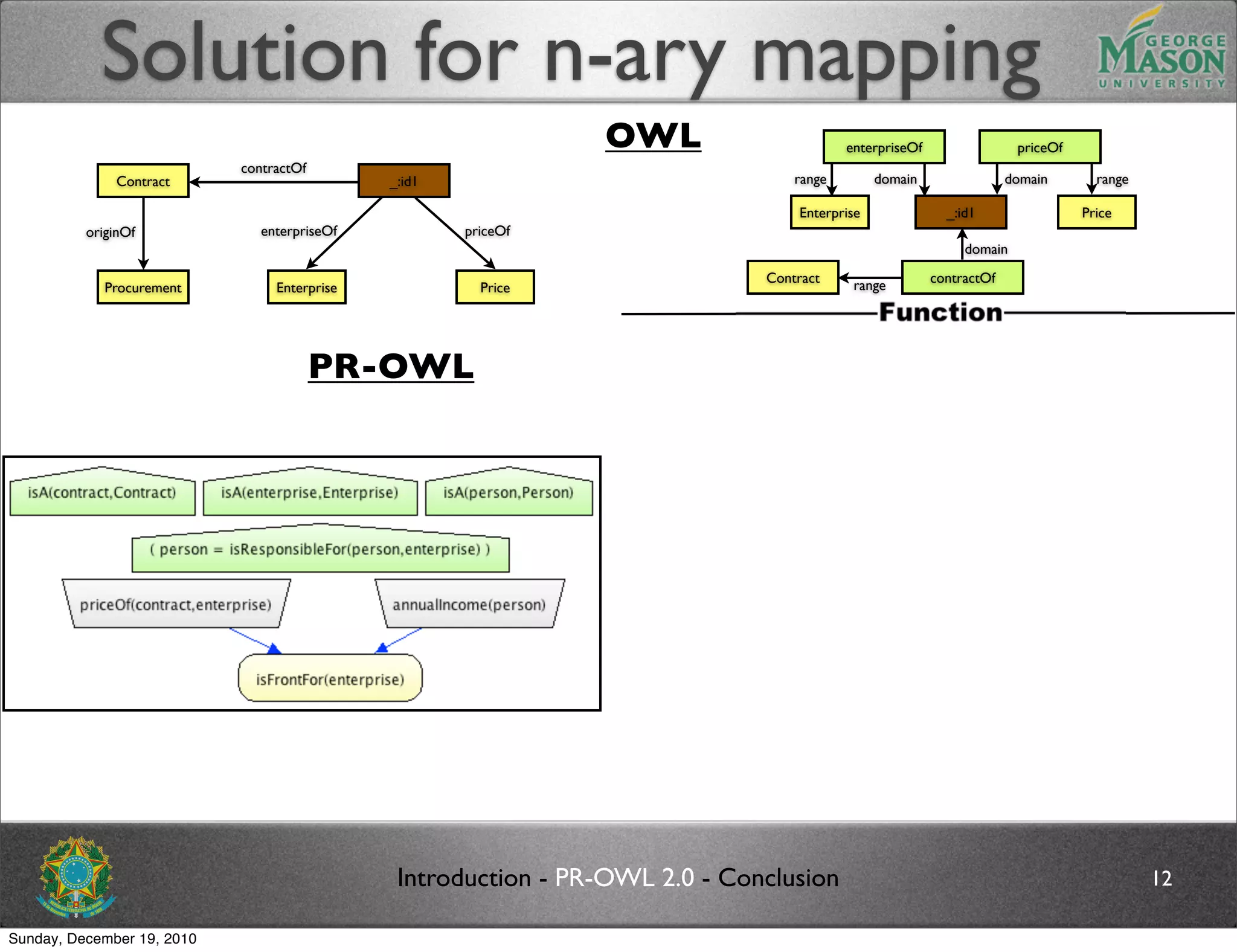
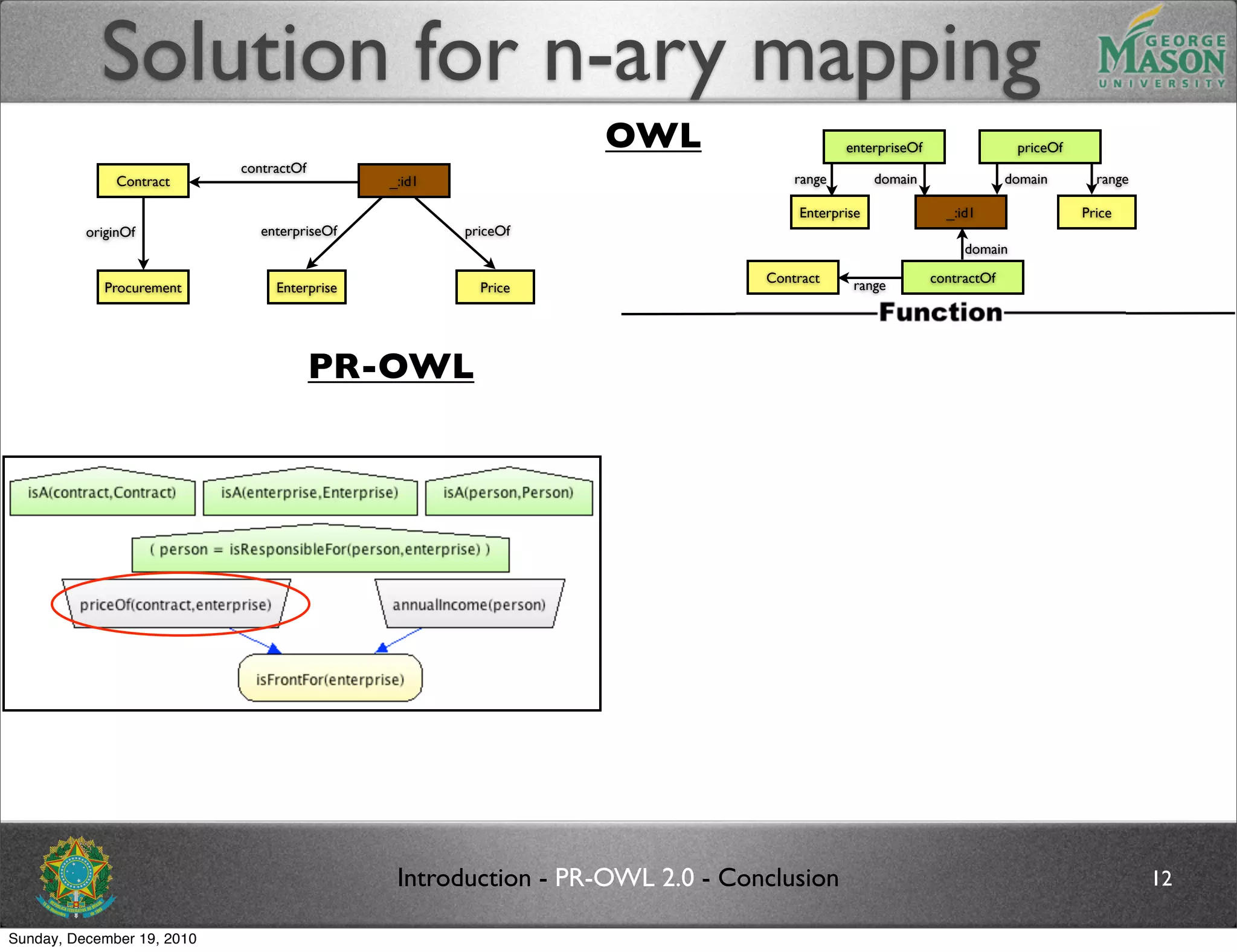
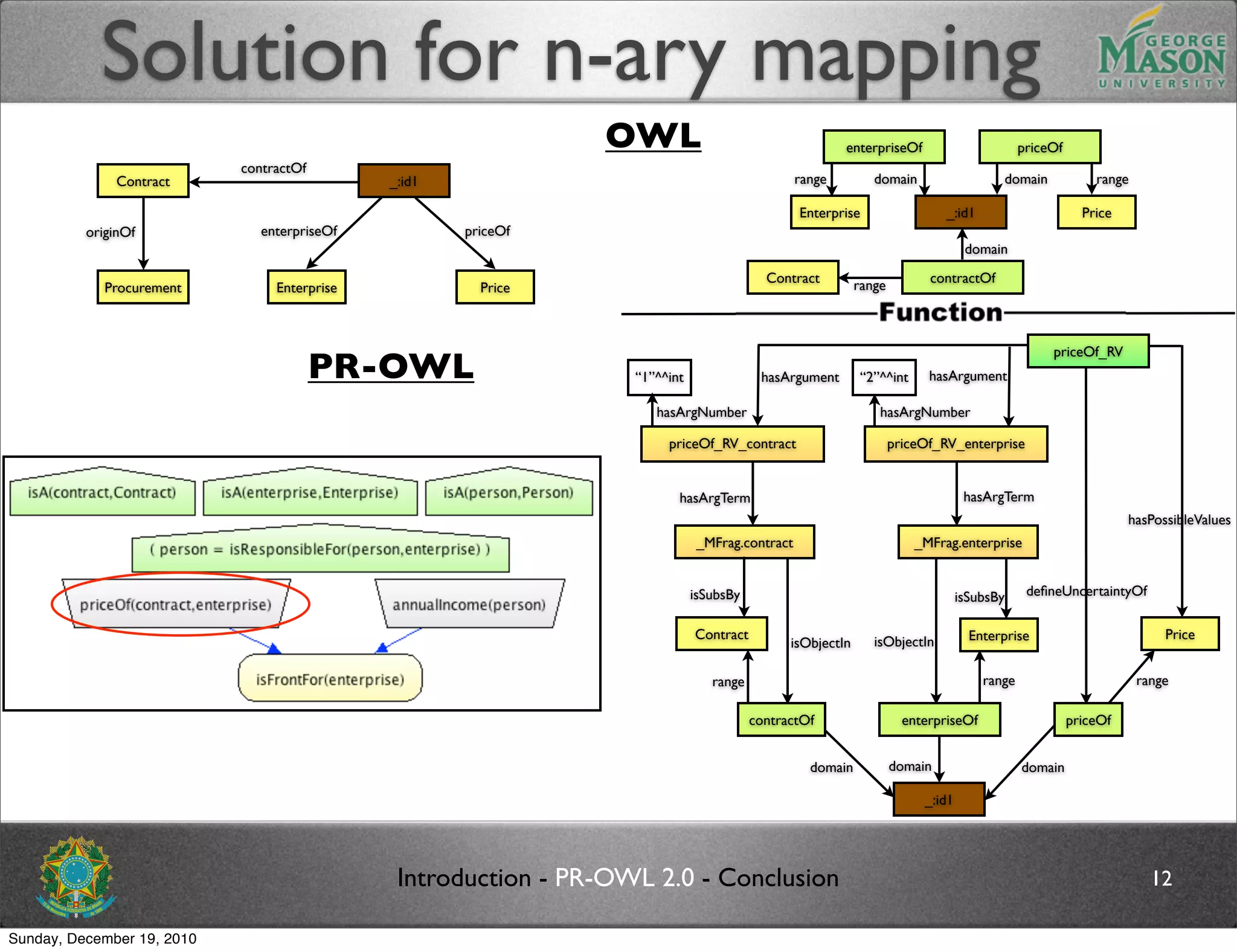
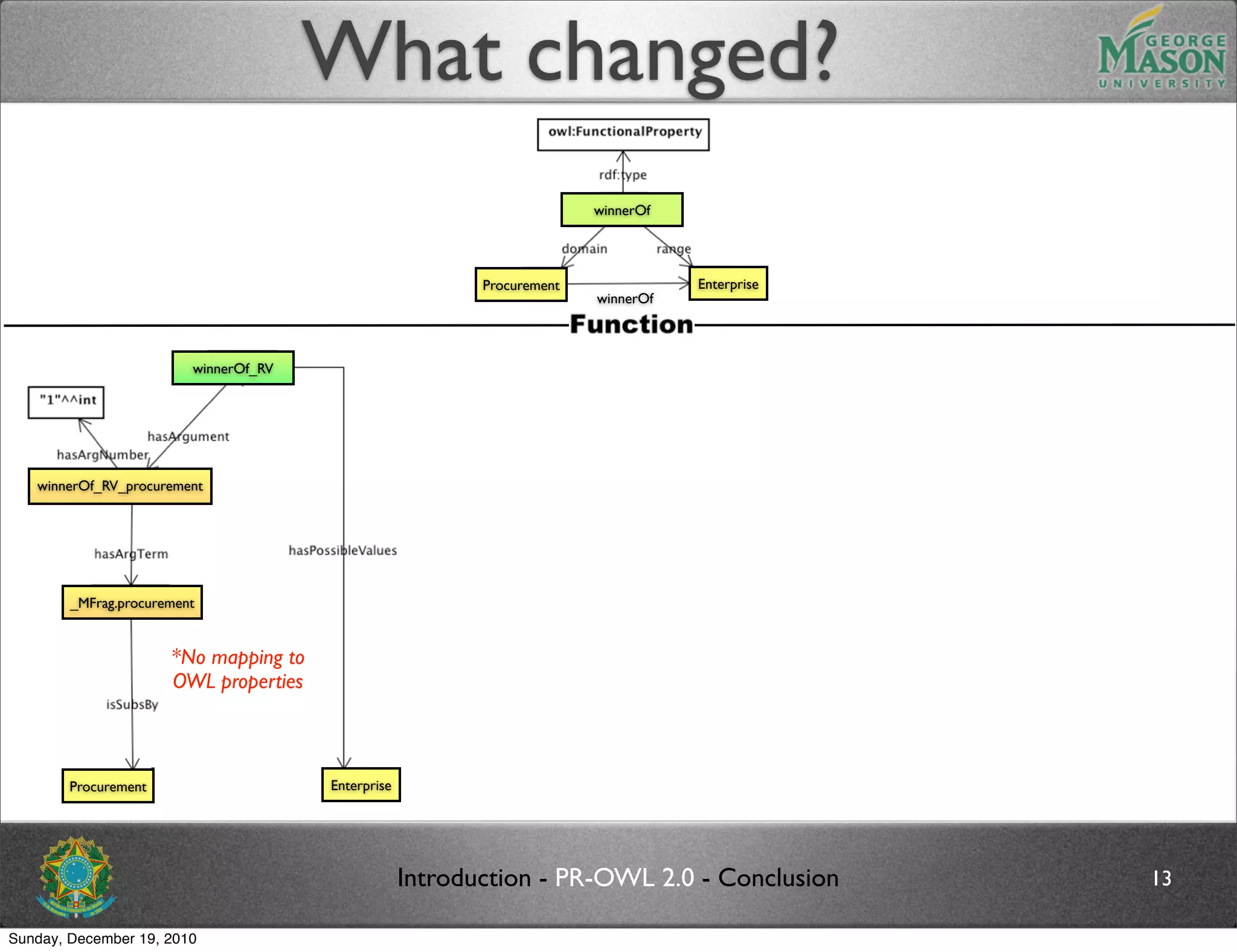
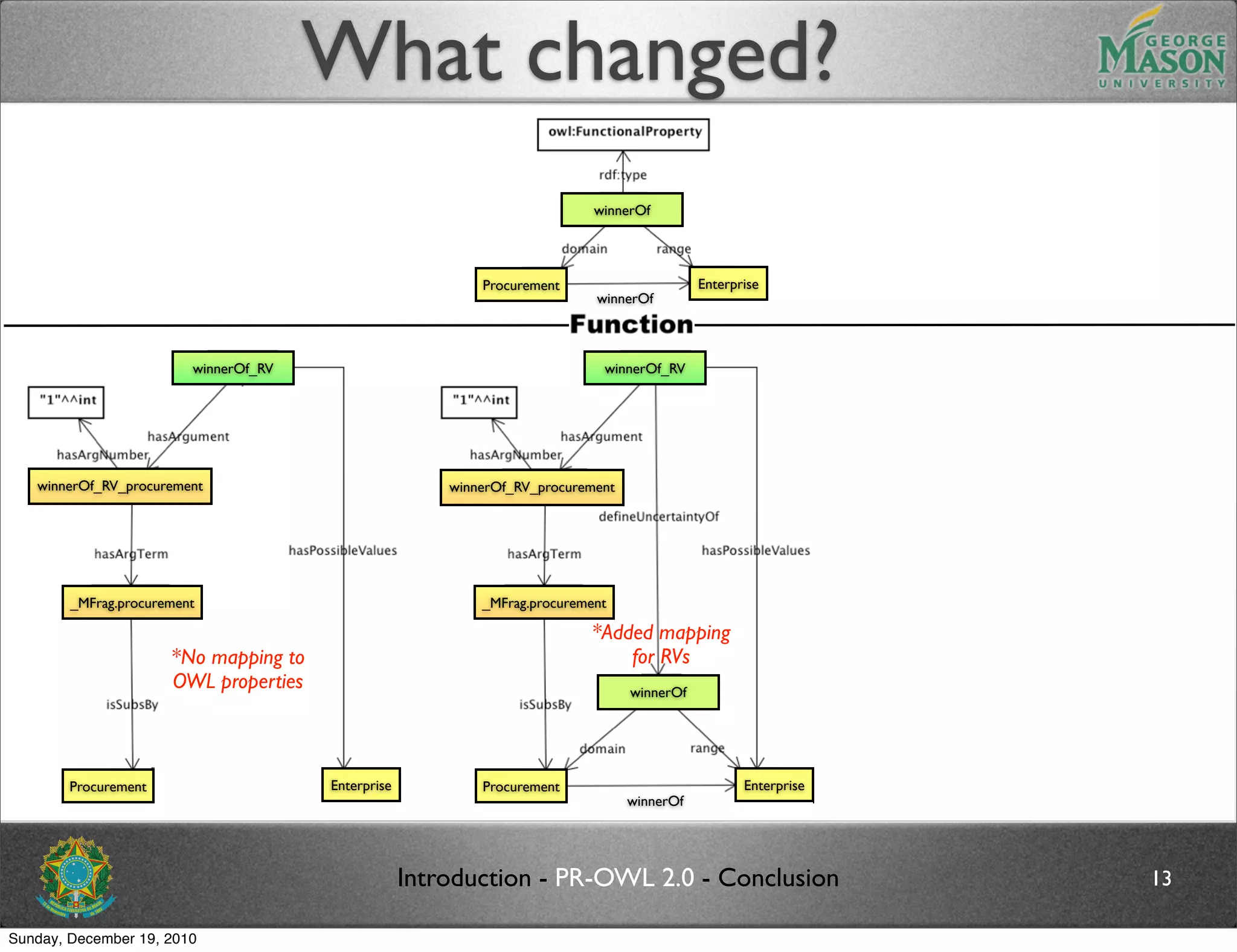
The document discusses bridging the gap between PR-OWL and OWL semantics. It introduces probabilistic ontologies which include types of entities, properties, relationships, processes/events, statistical regularities, and uncertainty. It describes how the mapping between PR-OWL and OWL is currently incomplete and proposes solutions to better represent binary and n-ary relations between concepts.


































































