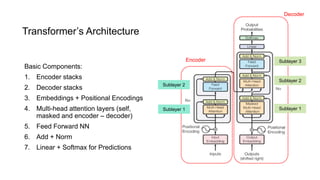
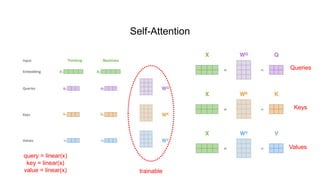
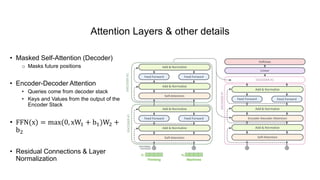
1) The document discusses using a Transformer model for protein secondary structure prediction (PSSP). Transformers use self-attention and avoid issues with long-term dependencies that RNNs face.
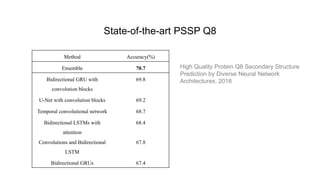
2) Several experiments were conducted to determine the best Transformer architecture for PSSP, varying number of layers (N), hidden sizes (d_model), attention heads (h), and other hyperparameters. The best results were around 63-64% accuracy with N=2, d_model=128-256, and h=8.
3) Future work proposed includes exploring n-gram representations, pretraining on larger datasets, and ensembling with other models.












































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)

![240318_JW_labseminar[Attention Is All You Need].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/240318jwlabseminartransformer-240409103857-bb3838b7-thumbnail.jpg?width=640&height=640&fit=bounds)








![[PR12] PR-036 Learning to Remember Rare Events](https://cdn.slidesharecdn.com/ss_thumbnails/pr12pr-036learningtoremeberrareevents-170917140144-thumbnail.jpg?width=640&height=640&fit=bounds)



























