Download to read offline







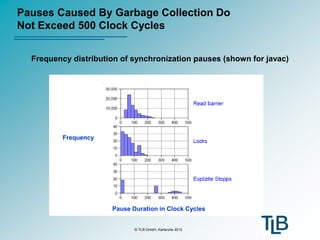













The document presents a novel RISC processor architecture designed to improve garbage collection in embedded systems, aimed at addressing buffer overflow vulnerabilities that cause significant security issues. This architecture features a dedicated coprocessor for real-time parallel garbage collection, minimizing overhead and maintaining cache coherence, thus allowing for efficient memory management with limited pauses. A prototype has been developed, demonstrating that the approach enables efficient synchronization and low runtime overhead, making it suitable for real-time applications.



































































