The document serves as an introduction to machine learning, outlining its definition, applications, and various types of learning techniques. It covers key concepts such as supervised and unsupervised learning, regression, classification, and commonly used algorithms and their components. Moreover, the document highlights the importance of data in training models and discusses the need for machine learning in scenarios where human expertise is insufficient or unavailable.







![ Web mining: Search engines
Computational biology
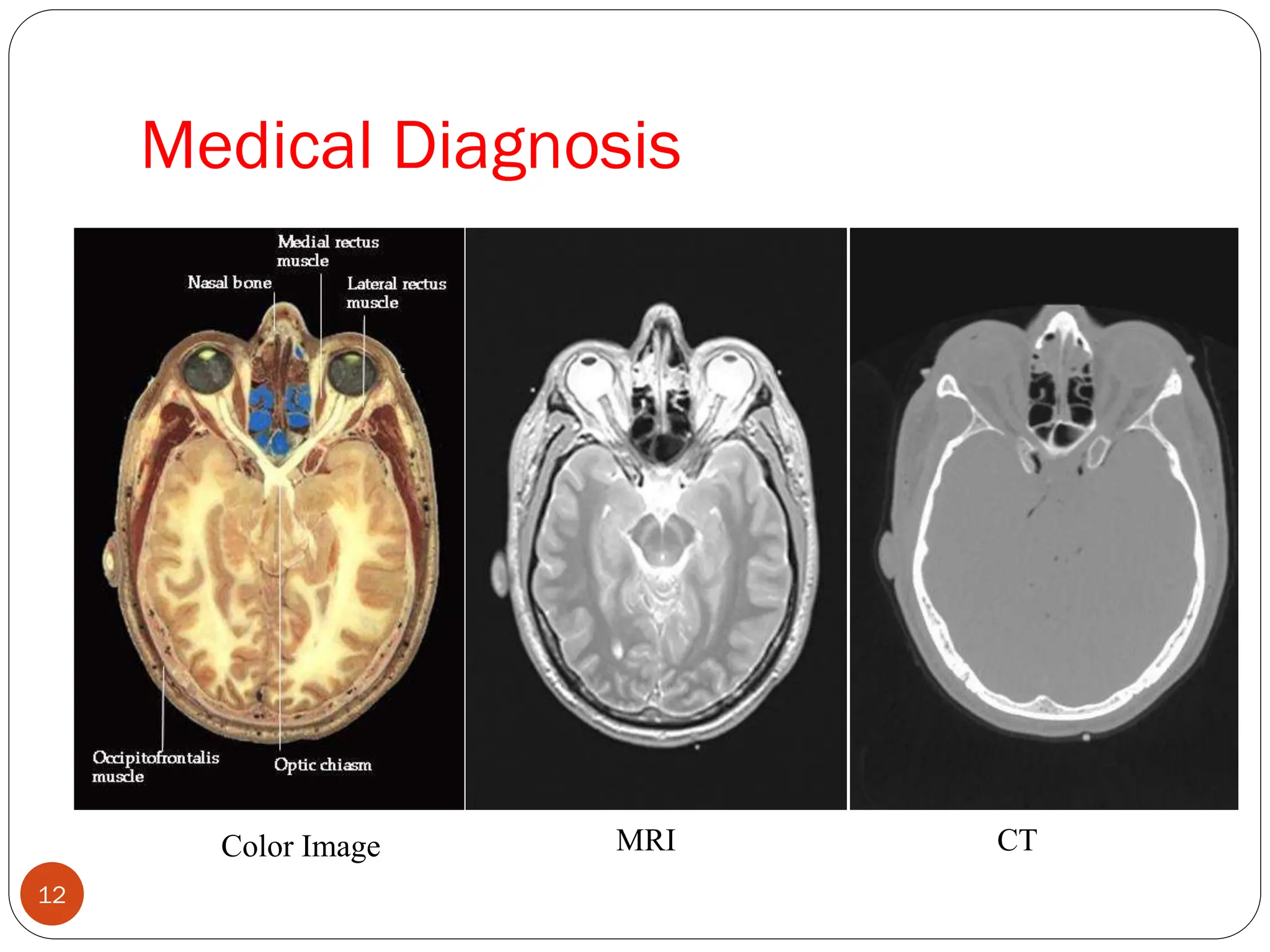
Medicine: Medical diagnosis
Retail: Market basket analysis, Customer relationship management (CRM)
Finance: Credit scoring, fraud detection
Manufacturing: Optimization, troubleshooting
E-commerce
Space exploration
Robotics
Information extraction
Social networks
Debugging
[Your favorite area]
Sample Applications
10](https://image.slidesharecdn.com/presentation-19-250107152711-4044e7cd/75/Presentation-19-08-2024hvug7gugyvuvugugugugugug-10-2048.jpg)