Download to read offline

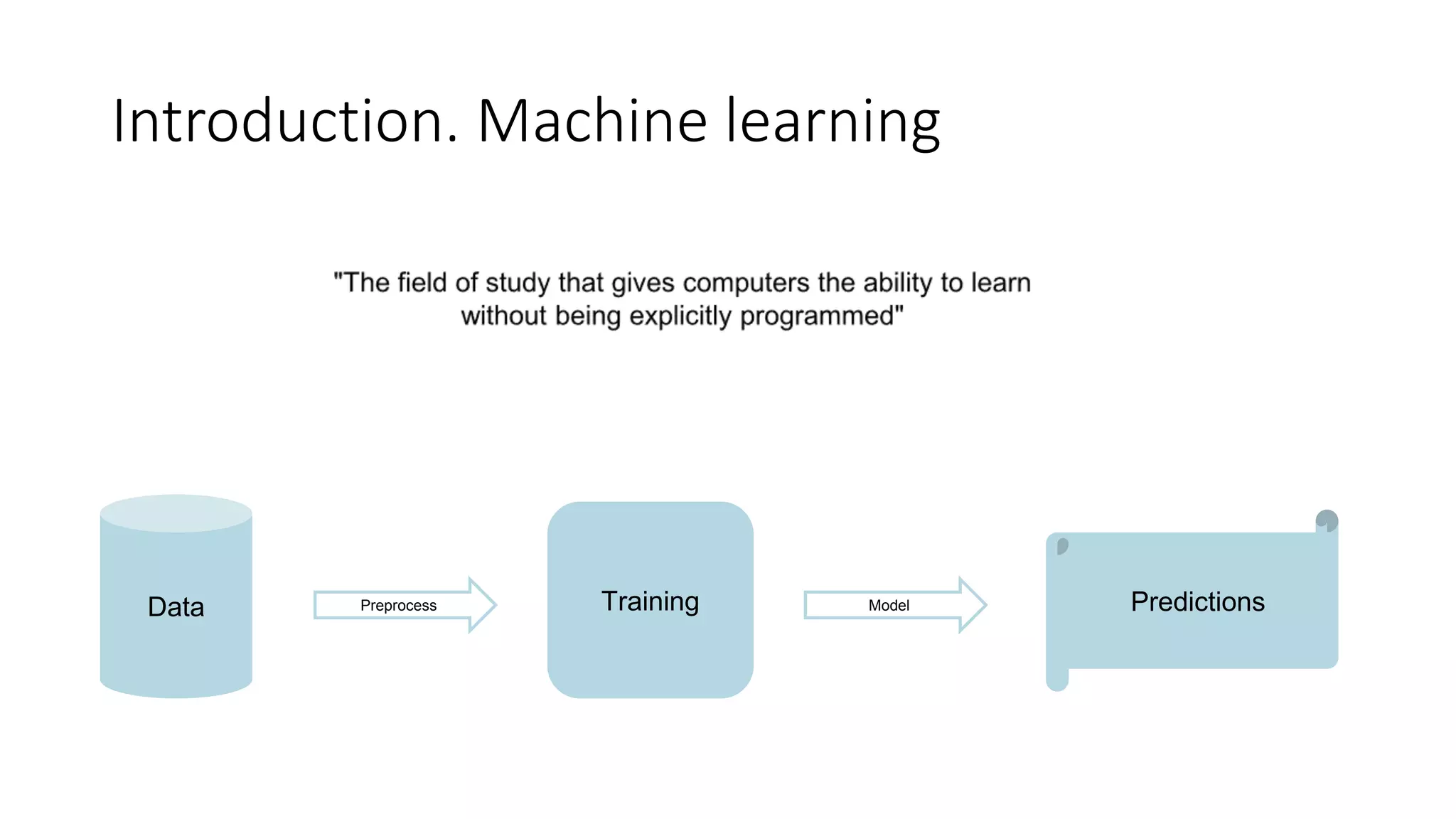




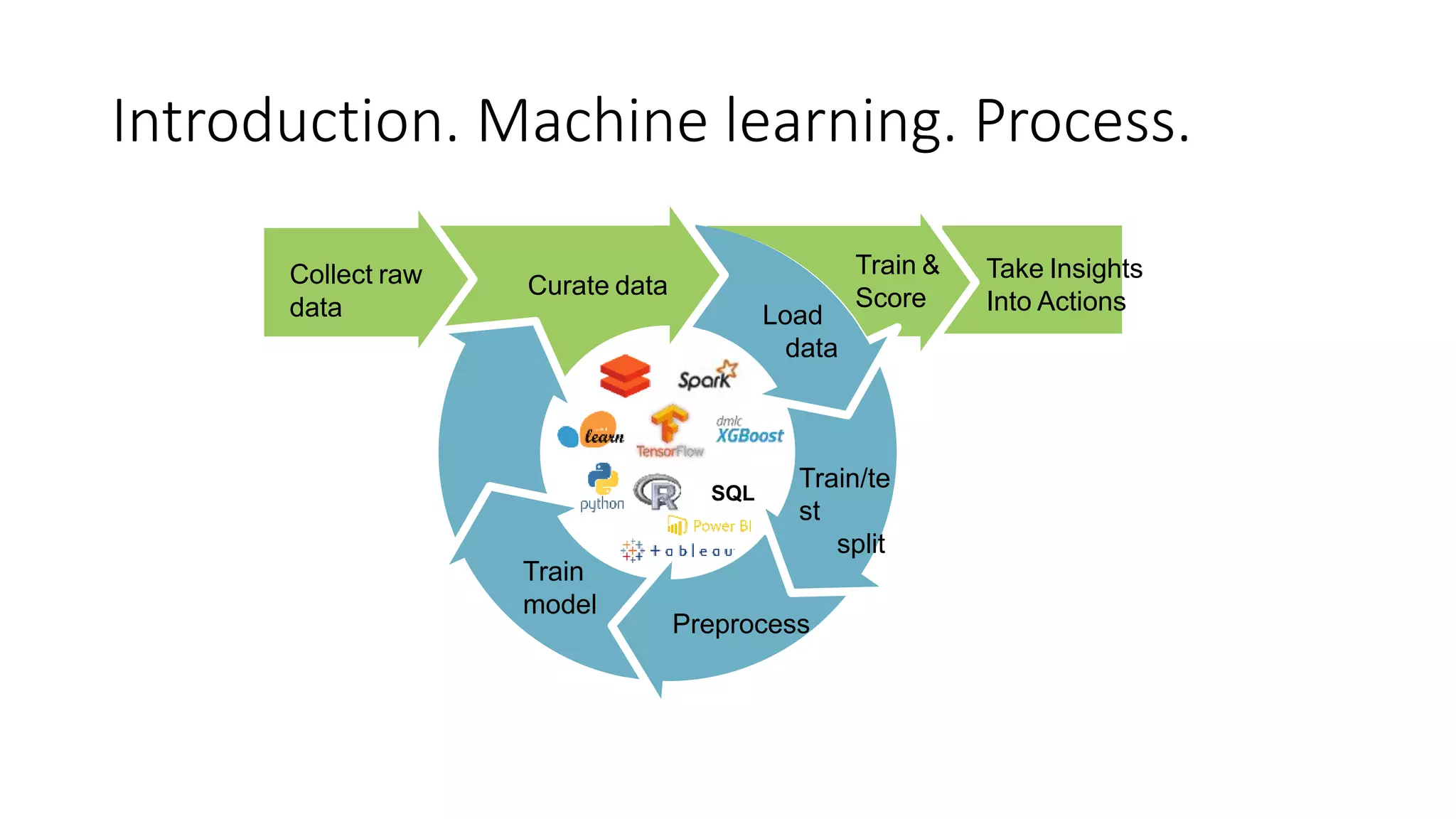












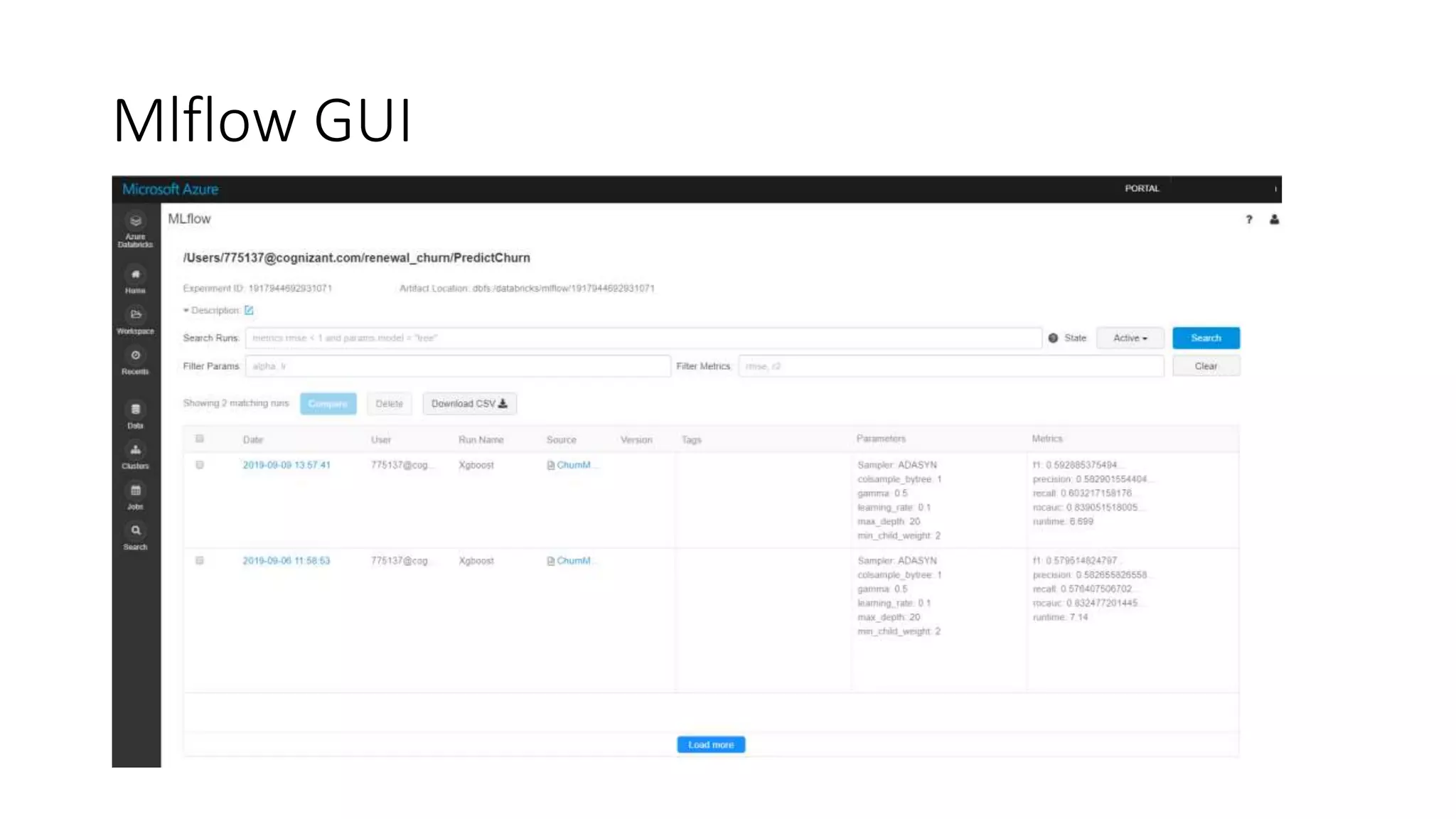

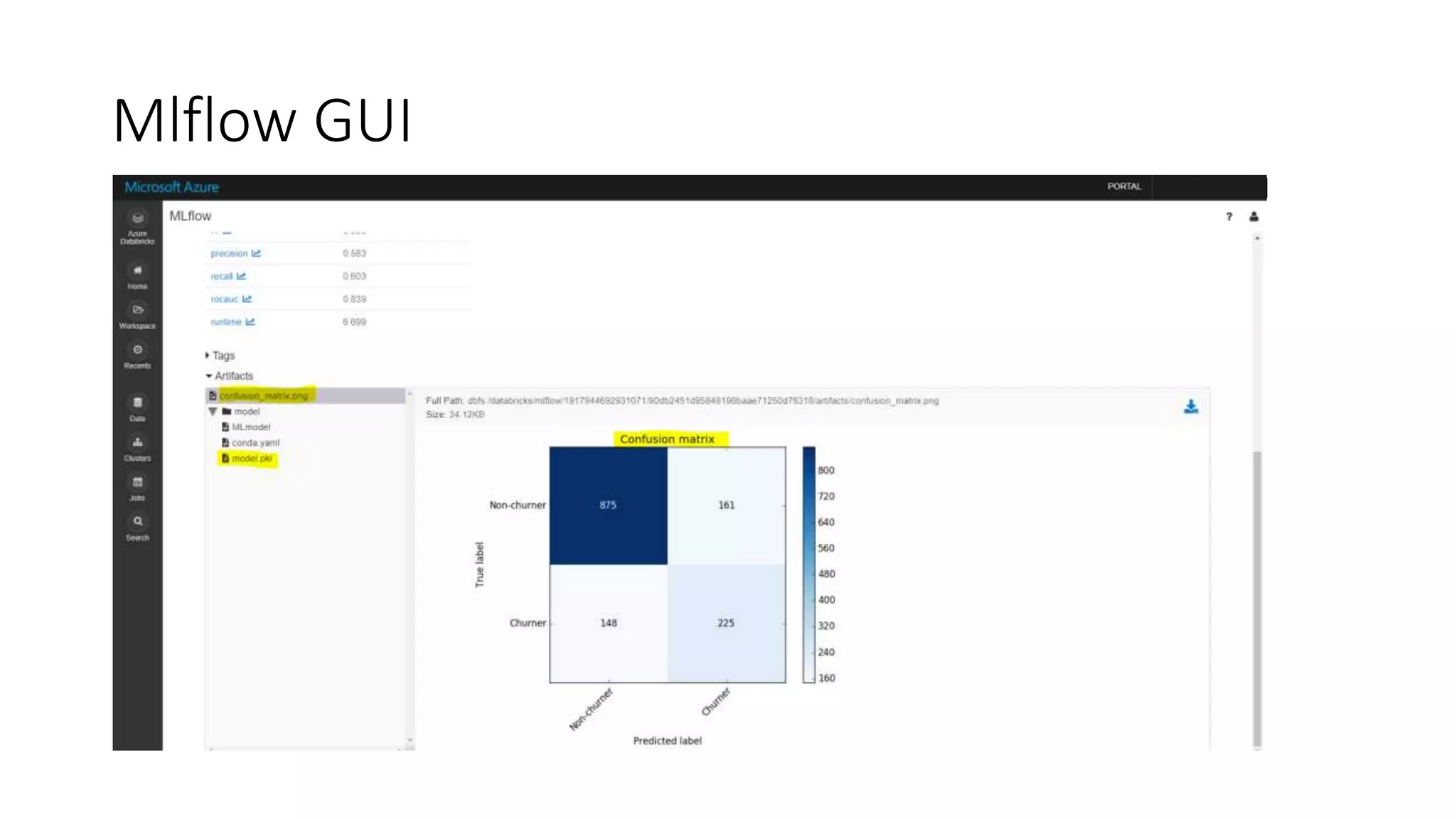







This document discusses predicting customer churn using machine learning models built with Azure Databricks, Scikit-learn, and Mlflow. It involves collecting customer data, preprocessing the data through steps like encoding, scaling, sampling to address class imbalance, and splitting into train and test sets. Various classification models are trained and evaluated on the training data using metrics like f1 score, precision, and recall. Hyperparameter optimization is performed to improve model performance. The best model is stored and tracked using Mlflow for scoring new data and predicting customer churn probabilities. SHAP is used to explain the model predictions.












![[2C2]PredictionIO](https://cdn.slidesharecdn.com/ss_thumbnails/2c2predictionio-deview-140929192352-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
