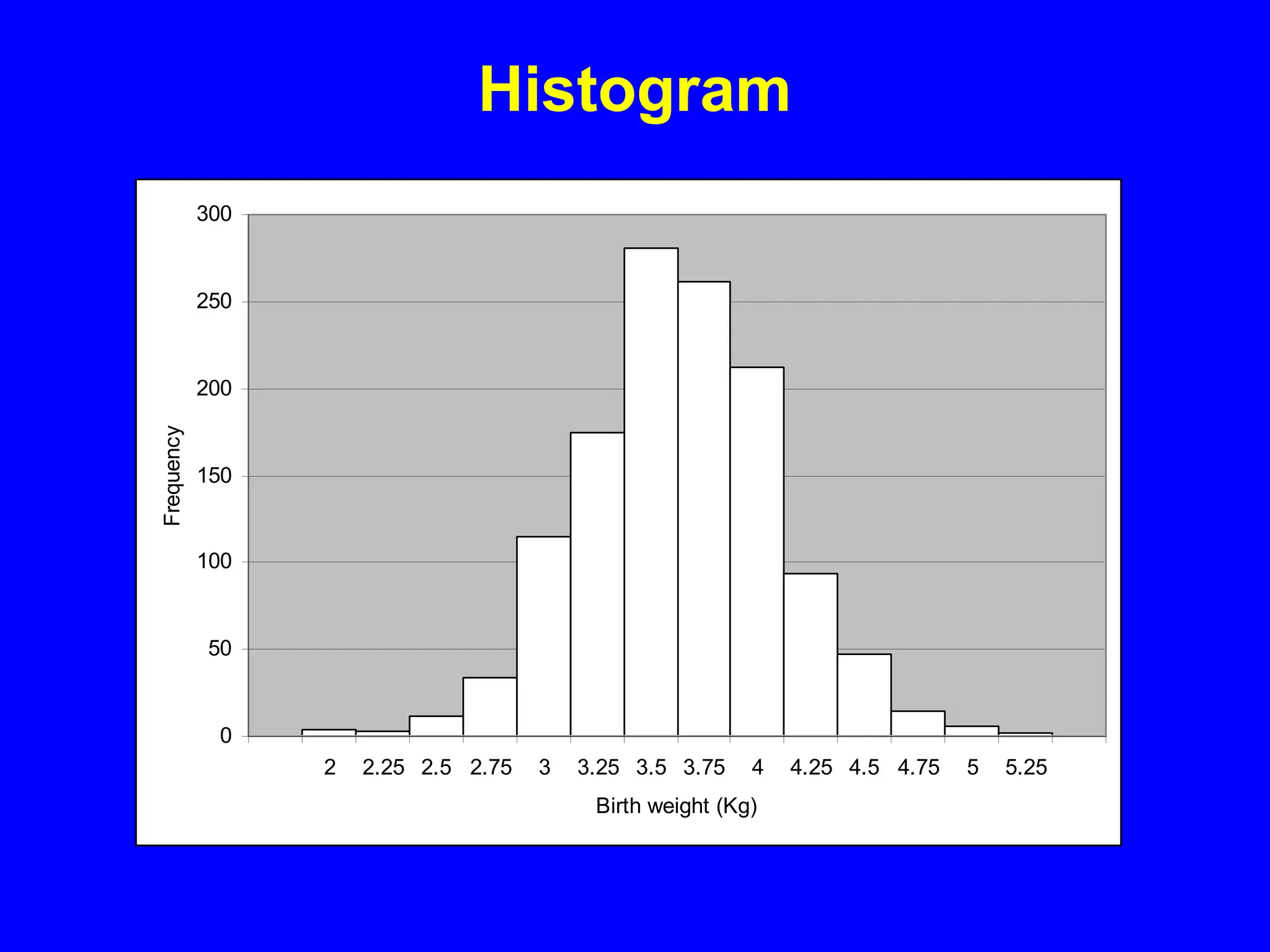
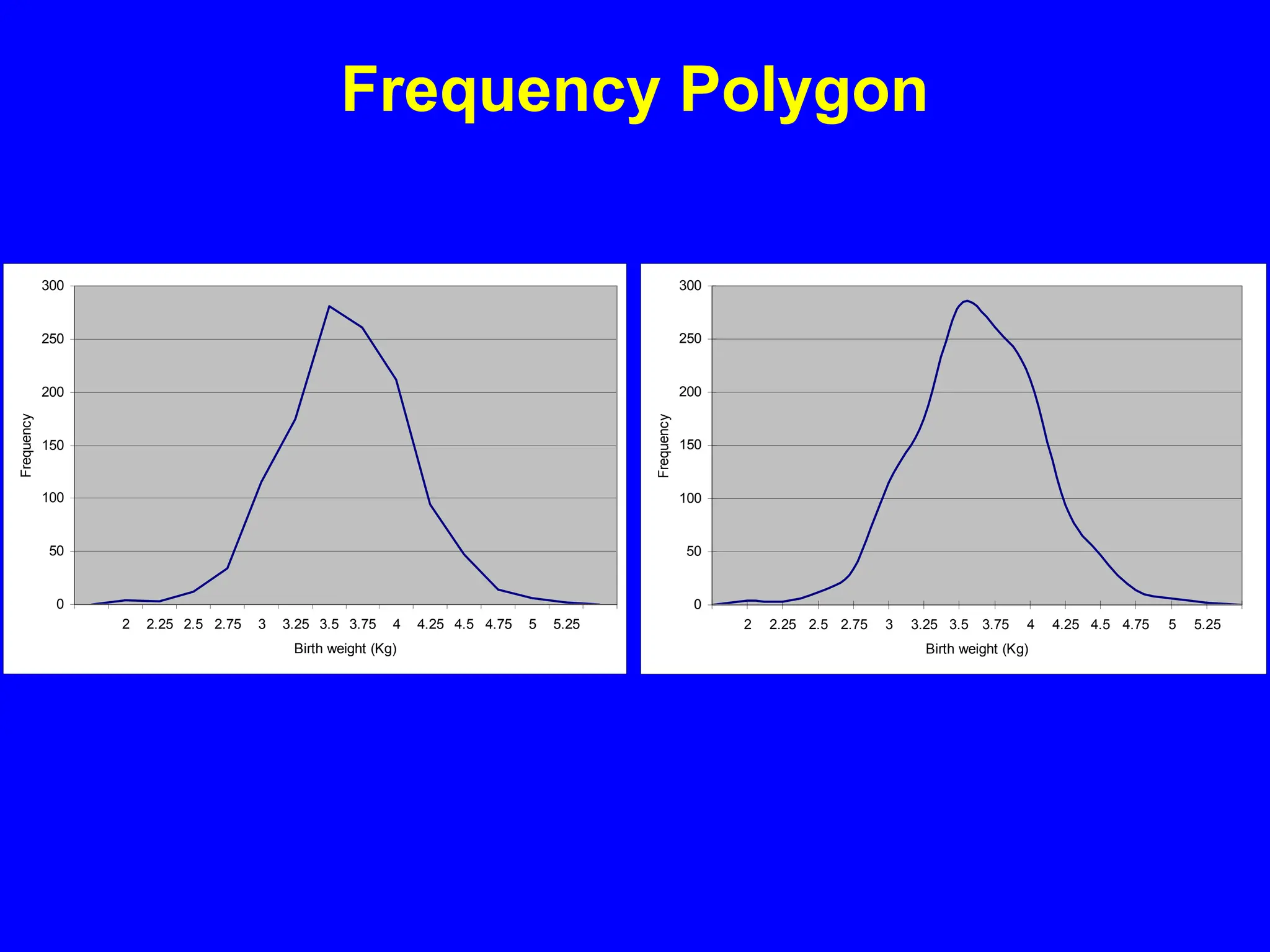
The document provides an overview of statistical methods, focusing on data types, distributions, and their applications in health sciences. It emphasizes the importance of data collection, analysis, and interpretation in making informed decisions about patient care and public health. Key concepts include the handling of variation, types of statistical distributions, and the use of descriptive statistics to summarize data.