19
Dataset: WAYMO OpenDataset[6]
Model: PointPillars[7], Range Sparse Net(RSN)[8]
3D OBJECT DETECTION
20.
20
[1] Zhaoqi Leng,Mingxing Tan ~Mingxing_Tan3 , Chenxi Liu, Ekin Dogus Cubuk, Jay
Shi, Shuyang Cheng, Dragomir Anguelov. PolyLoss: A Polynomial Expansion
Perspective of Classification Loss Functions. In ICLR 2022.
[2] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A
large-scale hierarchical image database. In 2009 IEEE conference on computer vision
and pattern recognition, pp. 248–255. Ieee, 2009.
[3] Mingxing Tan and Quoc V Le. Efficientnetv2: Smaller models and faster training.
In International Conference on Machine Learning, 2021.
[4] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva
Ramanan, Piotr Dollar, and C Lawrence Zitnick. Microsoft coco: Common objects in
context. In ´ European conference on computer vision, pp. 740–755. Springer, 2014.
[5] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Girshick. Mask r-cnn. In ´
Proceedings of the IEEE international conference on computer vision, pp. 2961–2969,
2017.
Reference
21.
21
[6] Pei Sun,Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai
Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al.
Scalability in perception for autonomous driving: Waymo open dataset. In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pp. 2446–2454, 2020.
[7] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar
Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pp. 12697–12705, 2019.
[8] Pei Sun, Weiyue Wang, Yuning Chai, Gamaleldin Elsayed, Alex Bewley, Xiao Zhang,
Christian Sminchisescu, and Dragomir Anguelov. Rsn: Range sparse net for efficient,
accurate lidar 3d object detection. In Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition, 2021.
Reference


![PolyLoss: A POLYNOMIAL EXPANSION PERSPECTIVE
OF CLASSIFICATION LOSS FUNCTIONS[1]
▪ 著者:
Zhaoqi Leng, Mingxing Tan, Chenxi Liu, Ekin Dogus Cubuk, Jay Shi, Shuyang
Cheng, Dragomir Anguelov (Waymo LLC, Google LLC)
▪ ICLR 2022
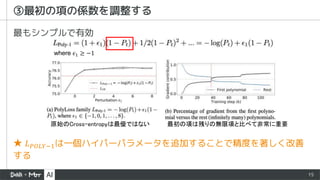
▪ 一言
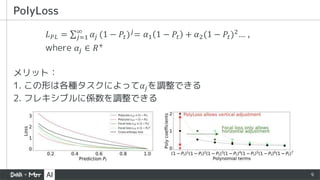
▪ PolyLossという新しいフレームワークで分類損失関数を理解し設計する
4](https://image.slidesharecdn.com/20220513cvplotpolyloss-220606043410-5ac15ab6/85/PolyLoss-A-POLYNOMIAL-EXPANSION-PERSPECTIVE-OF-CLASSIFICATION-LOSS-FUNCTIONS-4-320.jpg)







![17
Dataset: IMAGENET[2]-1K, IMAGENET-21K
Model: EfficientNetV2[3]
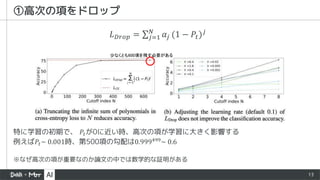
★ 𝜖 が増えるほど(最初の項の係数が小さいほど)Accuracyを向上
★ 𝜖 = 1時は予測自信度を向上、ImageNet-21Kの自信不足を改善
2D CLASSIFICATION](https://image.slidesharecdn.com/20220513cvplotpolyloss-220606043410-5ac15ab6/85/PolyLoss-A-POLYNOMIAL-EXPANSION-PERSPECTIVE-OF-CLASSIFICATION-LOSS-FUNCTIONS-17-320.jpg)
![18
Dataset: COCO Dataset[4]
Model: Mask R-CNN[5] (𝐿𝑀𝑎𝑠𝑘𝑅𝐶𝑁𝑁 = 𝐿𝑐𝑙𝑠 + 𝐿𝑏𝑜𝑥 + 𝐿𝑚𝑎𝑠𝑘の𝐿𝑐𝑙𝑠だけ置換え)
★ 𝜖 が減らすほど(最初の項の係数が小さいほど)Mask R-CNNのAPとARを向上
★ 𝜖 = −1時過度自信の予測を低下させ、不均衡データセットでの性能を改善
2D INSTANCE SEGMENTATION & OBJECT DETECTION](https://image.slidesharecdn.com/20220513cvplotpolyloss-220606043410-5ac15ab6/85/PolyLoss-A-POLYNOMIAL-EXPANSION-PERSPECTIVE-OF-CLASSIFICATION-LOSS-FUNCTIONS-18-320.jpg)
![19
Dataset: WAYMO Open Dataset[6]
Model: PointPillars[7], Range Sparse Net(RSN)[8]
3D OBJECT DETECTION](https://image.slidesharecdn.com/20220513cvplotpolyloss-220606043410-5ac15ab6/85/PolyLoss-A-POLYNOMIAL-EXPANSION-PERSPECTIVE-OF-CLASSIFICATION-LOSS-FUNCTIONS-19-320.jpg)
![20
[1] Zhaoqi Leng, Mingxing Tan ~Mingxing_Tan3 , Chenxi Liu, Ekin Dogus Cubuk, Jay
Shi, Shuyang Cheng, Dragomir Anguelov. PolyLoss: A Polynomial Expansion
Perspective of Classification Loss Functions. In ICLR 2022.
[2] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A
large-scale hierarchical image database. In 2009 IEEE conference on computer vision
and pattern recognition, pp. 248–255. Ieee, 2009.
[3] Mingxing Tan and Quoc V Le. Efficientnetv2: Smaller models and faster training.
In International Conference on Machine Learning, 2021.
[4] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva
Ramanan, Piotr Dollar, and C Lawrence Zitnick. Microsoft coco: Common objects in
context. In ´ European conference on computer vision, pp. 740–755. Springer, 2014.
[5] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Girshick. Mask r-cnn. In ´
Proceedings of the IEEE international conference on computer vision, pp. 2961–2969,
2017.
Reference](https://image.slidesharecdn.com/20220513cvplotpolyloss-220606043410-5ac15ab6/85/PolyLoss-A-POLYNOMIAL-EXPANSION-PERSPECTIVE-OF-CLASSIFICATION-LOSS-FUNCTIONS-20-320.jpg)
![21
[6] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai
Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al.
Scalability in perception for autonomous driving: Waymo open dataset. In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pp. 2446–2454, 2020.
[7] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar
Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition, pp. 12697–12705, 2019.
[8] Pei Sun, Weiyue Wang, Yuning Chai, Gamaleldin Elsayed, Alex Bewley, Xiao Zhang,
Christian Sminchisescu, and Dragomir Anguelov. Rsn: Range sparse net for efficient,
accurate lidar 3d object detection. In Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition, 2021.
Reference](https://image.slidesharecdn.com/20220513cvplotpolyloss-220606043410-5ac15ab6/85/PolyLoss-A-POLYNOMIAL-EXPANSION-PERSPECTIVE-OF-CLASSIFICATION-LOSS-FUNCTIONS-21-320.jpg)












![[DL輪読会]Focal Loss for Dense Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/focalloss-180208092846-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)



















