Download to read offline





![Data Flow
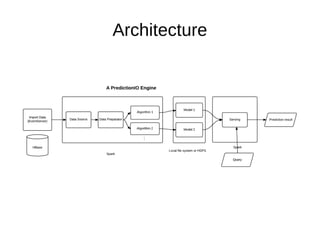
● Hbase is the data store. All the imported events are stored in Hbase.
● Datasource then reads the imported data and converts to the desired format.
● Data preparator preprocesses the data and feed it to algorithm for model
training.
● Algorithm includes ML algorithm that determines how a predictive model is
constructed.
● Serving component accepts the input from user and returns the corresponding
results. Serving combine the results into one if engine have multiple
algorithms. Logic can be added to serving component to customize results.
● PredictionIO splits these archtecture into two, An engine composed of [D]ata,
[A]lgorithm, [S]erving and preparator, second part have only [E]valuation
metrics. PredictionIO mention this as DASE architecture.](https://image.slidesharecdn.com/36922ae6-3723-48cb-94e6-828ae6837686-150705061252-lva1-app6891/85/pio_present-7-320.jpg)

![● Start Prediction Server
Change directory to pio_installation_directory/bin or export pio path to and run
pio-start-all
This will show you status of every task and finally a message like below will be shown
[INFO] [HBLEvents] Removing table pio_event:events_0...
[INFO] [Console$] (sleeping 5 seconds for all messages to show up...)
[INFO] [Console$] Your system is all ready to go.
● Status of server can be checked at any time using
pio status
● Engine templates can be downloaded from predictionIO
website
http://templates.prediction.io/](https://image.slidesharecdn.com/36922ae6-3723-48cb-94e6-828ae6837686-150705061252-lva1-app6891/85/pio_present-9-320.jpg)





![Build, Train and Deploy Engine
● To build engine issue command pio build –verbose.
- verbose flag will display output of each ongoing operation.
- On successfull build predictionIO will display the following line
[INFO] [Console$] Your engine is ready for training.
● To train engine issue command pio train
-On successfull training predictionIO will display the following
[INFO] [CoreWorkflow$] Training completed successfully.
- If low heap size issue is reported then -- --driver-memory 8G can be used to carry on
training with a higher memory. Replace 8G with the desired memory 'G' stands for GB.](https://image.slidesharecdn.com/36922ae6-3723-48cb-94e6-828ae6837686-150705061252-lva1-app6891/85/pio_present-15-320.jpg)

![Sample Response
● Following is a sample response. Note that the number of results returned
can be changed by altering num key of the input query eg:({"user": "1", "num": 2})
{
"itemScores":[
{"item":"22","score":4.072304374729956},
{"item":"62","score":4.058482414005789},
{"item":"75","score":4.046063009943821},
{"item":"68","score":3.8153661512945325}
]
}](https://image.slidesharecdn.com/36922ae6-3723-48cb-94e6-828ae6837686-150705061252-lva1-app6891/85/pio_present-17-320.jpg)


This document provides an overview of PredictionIO, an open source machine learning server. It discusses what PredictionIO is, how it works, and how to set it up and build a movie recommendation engine on it. PredictionIO is built on Apache Spark and MLlib and uses HBase for data storage. It allows importing data, building models, training, evaluating, and deploying machine learning engines. The document demonstrates how to create a movie recommendation engine using PredictionIO's template, import movie rating data, train and deploy the engine, and test it by sending queries.


































![[2C2]PredictionIO](https://cdn.slidesharecdn.com/ss_thumbnails/2c2predictionio-deview-140929192352-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


















