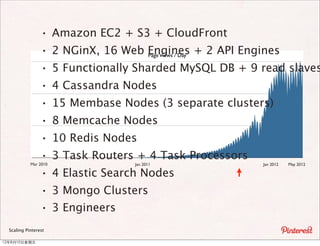
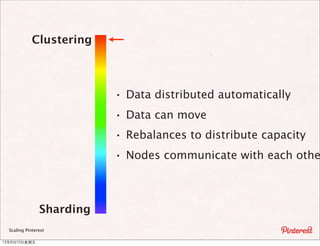
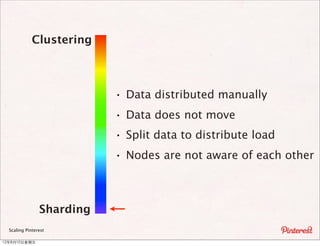
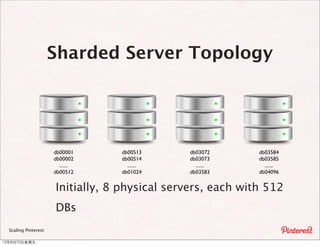
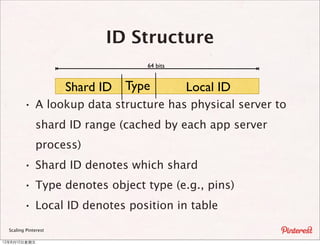
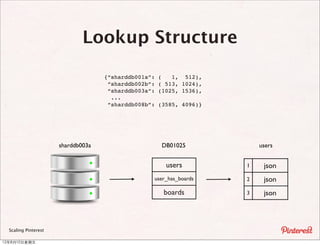
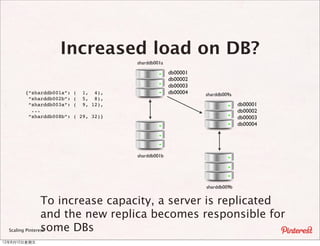
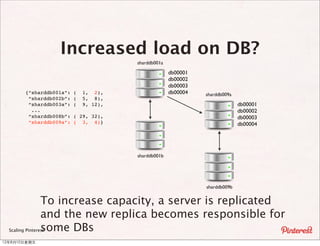
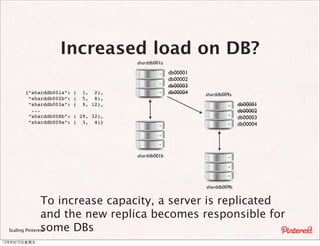
The document summarizes a presentation about scaling Pinterest's architecture. It discusses how Pinterest uses sharding across multiple MySQL databases to scale its infrastructure. Key points include how Pinterest generates IDs across shards, loads data, handles caching, and has transitioned its database structure over time to support increased load.













































































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)






