Report
Share
Download to read offline

Recommended
Equalization in digital communication
Equalization
Time domain equalization
Frequency domain equalization
Channel Estimation
C2 discrete time signals and systems in the frequency-domain
Discrete-Time Signals and Systems in the Frequency-Domain
Discrete-Time Fourier Transform
time domain convolution theorem
frequency domain convolution theorem
Z transform
Recommended
Equalization in digital communication
Equalization
Time domain equalization
Frequency domain equalization
Channel Estimation
C2 discrete time signals and systems in the frequency-domain
Discrete-Time Signals and Systems in the Frequency-Domain
Discrete-Time Fourier Transform
time domain convolution theorem
frequency domain convolution theorem
Z transform
L7 er2
The document discusses various concepts in entity-relationship (E-R) modeling including: weak entity sets and how their primary keys are formed; reducing E-R diagrams to relational schemas; extended E-R features like specialization, generalization, and aggregation; and differences between E-R diagrams and UML class diagrams. Key symbols used in E-R notation are also summarized.
L8 design1
This document provides an overview of relational database design and normalization. It discusses the goals of database design as generating schemas without unnecessary redundancy and allowing easy data retrieval. Normalization aims to design schemas in a desirable normal form, such as Boyce-Codd normal form (BCNF) or third normal form (3NF). The document introduces key concepts like functional dependencies, normal forms, decomposition, and closure of functional dependencies, which are used to determine if a schema is properly normalized and how to decompose schemas if necessary.
L9 design2
This document provides an overview of relational database design concepts including normal forms and decomposition. It begins with an outline of topics to be covered such as algorithms for functional dependencies, decomposition using multi-valued dependencies, normal forms, and modeling temporal data. The document then reviews Boyce-Codd normal form and provides examples of testing for and decomposing relations into BCNF. It also introduces third normal form and covers testing for and decomposing relations into 3NF. Finally, it briefly discusses multi-valued dependencies and compares BCNF and 3NF.
14 pro resolution
This document provides an overview of resolution in propositional logic. It introduces resolution as a new rule of inference that allows inferring a resolvent clause from two clauses. It describes how to convert arbitrary well-formed formulas into conjunctions of clauses to use with resolution. Resolution refutations are discussed as a way to decide logical entailments by attempting to derive the empty clause. Various strategies for conducting resolution refutation searches more efficiently are also covered, including ordering strategies and refinement strategies. Finally, the document defines Horn clauses and their special properties that allow for linear-time deduction algorithms.
13 propositional calculus
This document provides an overview of the Propositional Calculus. It discusses:
- The language of propositional calculus using atoms, connectives, and well-formed formulas
- Rules of inference like modus ponens, conjunction introduction, and disjunction introduction
- Defining proofs and theorems based on applying rules of inference
- Semantics by associating logical elements with truth values under interpretations
- Important concepts like validity, equivalence, entailment, and the soundness and completeness of rules of inference.
- The propositional satisfiability (PSAT) problem and solving techniques like exhaustive search and GSAT.
12 adversal search
This document discusses adversarial search techniques for two-agent games with perfect information. It introduces the minimax procedure and how it recursively assigns values to nodes in a game tree by maximizing the value for the maximizing agent and minimizing for the minimizing agent. The alpha-beta pruning technique is described which improves search efficiency by pruning subtrees that cannot alter the minimax value of the root. Examples of applying minimax and alpha-beta to tic-tac-toe are provided. The document also discusses handling games of chance using expectimax search and learning effective evaluation functions from self-play.
11 alternative search
This document discusses different approaches to solving constraint satisfaction problems including assignment problems. It provides examples of the eight queens problem and constraint propagation techniques. Constructive methods start with no assignments and add values satisfying constraints, while heuristic repair starts with a proposed solution and changes it to violate fewer constraints. Function optimization techniques like hill climbing and simulated annealing are also discussed.
10 2 sum
The document discusses different methods for reinforcement learning, including learning heuristic functions from experiences, learning in explicit and implicit graphs, using rewards instead of goals for tasks, and different algorithms like temporal difference learning and value iteration that help agents learn optimal policies by assigning credit to relevant state-action pairs.
22 planning
The document describes planning techniques in artificial intelligence, including STRIPS planning systems, forward and backward search methods, and partial-order planning. It discusses how STRIPS uses operators to describe state changes and searches for a sequence of actions to reach a goal state. Backward search methods work by regressing goals through operators to produce subgoals. Partial-order planning searches a plan space by transforming incomplete plans into more articulated plans until finding an executable plan.
21 situation calculus
This document provides an overview of the Situation Calculus, a formal logic framework for representing states, actions, and how actions transform states. It describes key components of the Situation Calculus including: (1) representing states as constants and using predicates to describe state properties, (2) representing actions and how they change state properties using effect axioms, (3) using frame axioms to represent properties that don't change with actions, and (4) generating plans by proving the existence of goal states and extracting the actions. Challenges with the approach include dealing with ramifications of actions and specifying all relevant preconditions and qualifications.
20 bayes learning
The document provides an overview of learning Bayes networks from data. It discusses learning the structure and conditional probability tables (CPTs) of a Bayes network given training data. When the network structure is known, the CPTs can be directly estimated from sample statistics in the training data, handling both cases of complete and missing data using techniques like expectation-maximization. When the structure is unknown, scoring metrics like minimum description length are used to search the space of possible structures to find the best fitting network. Dynamic decision networks extend this framework to model sequential decision making problems.
19 uncertain evidence
This document outlines probabilistic inference in Bayes networks. It begins with a review of probability theory concepts like joint probability, marginal probability, conditional probability, and Bayes' rule. It then discusses probabilistic inference in Bayes networks, including causal/top-down inference using evidence to determine probabilities, diagnostic/bottom-up inference using effects to determine causes, and "explaining away" where additional evidence makes other probabilities less certain. The document also covers uncertain evidence, D-separation to determine conditional independence, and inference techniques in polytrees.
18 common knowledge
This document discusses representing commonsense knowledge. It describes commonsense knowledge as everyday facts that most people understand, like objects falling when dropped or fish needing water. Representing all commonsense knowledge is difficult as there are no defined boundaries and some concepts cannot be described with sentences alone. The document outlines research areas in representing objects, materials, space, time, and physical processes. It also discusses knowledge representation using semantic networks and frames to organize taxonomic hierarchies and relationships between objects, properties, and categories in a graph structure. Nonmonotonic reasoning is also discussed for handling exceptions to default inferences.
17 2 expert systems
Rule-based expert systems use facts and rules to achieve expert-level competence in solving problems. They consist of a knowledge base containing facts and rules, an inference engine that manipulates the knowledge base to deduce information, and an explanation subsystem. Rule-based systems apply logical rules to the known facts to determine unknown information. Inductive logic programming learns rules by generalizing from examples to cover positive instances while avoiding negative ones.
17 1 knowledge-based system
The document discusses knowledge-based systems and their ability to reason over extensive knowledge bases. It addresses the theoretical problems of soundness, completeness, and tractability when using logical reasoning systems. Horn clauses and PROLOG are introduced as more efficient ways to perform inference compared to full predicate calculus. Different methods for reasoning including forward chaining and truth and assumption-based maintenance are also summarized.
16 2 predicate resolution
This document discusses resolution in predicate calculus. It covers topics like unification, predicate calculus resolution, converting well-formed formulas to clause form, using resolution to prove theorems, and answer extraction. It also discusses the equality predicate and paramodulation inference rule. The document provides examples to illustrate various concepts and techniques in resolution-based automated theorem proving in first-order logic.
16 1 predicate resolution
This document provides an outline and overview of key concepts in resolution in predicate calculus, including:
- Unification, which allows resolving clauses that have matching but complementary literals
- Converting formulas to clause form by eliminating quantifiers and connectives
- Using resolution to prove theorems by deriving the empty clause
- The equality predicate and paramodulation, an inference rule used with resolution when equality is present
The document describes these concepts over multiple sections and provides examples to illustrate predicate calculus resolution.
15 predicate
The document discusses the predicate calculus and its use for representing knowledge. It introduces the motivation and basic components of the predicate calculus language, including terms, well-formed formulas, and quantifiers. It explains the semantics of the language including interpretations, models, and the semantics of quantifiers. Finally, it provides examples of how predicate calculus can be used to conceptualize and represent knowledge about the world.
09 heuristic search
This document discusses various heuristic search algorithms including A*, iterative-deepening A*, and recursive best-first search. It begins by introducing the concept of using evaluation functions to guide best-first search and preferentially expand nodes with lower heuristic values. It then presents the general graph search algorithm and describes how A* specifically reorders nodes using an evaluation function that considers path cost and estimated cost to the goal. Consistency conditions for the heuristic function are discussed which guarantee A* finds optimal solutions.
08 uninformed search
This document discusses uninformed search algorithms. It outlines breadth-first search, depth-first search, and iterative deepening search. Breadth-first search finds the shortest path but uses exponential memory. Depth-first search uses linear memory but may explore large parts of the search space without finding the goal. Iterative deepening search combines the benefits of depth-first search and guarantees of finding the shortest solution like breadth-first search.
More Related Content
More from Tianlu Wang
L7 er2
The document discusses various concepts in entity-relationship (E-R) modeling including: weak entity sets and how their primary keys are formed; reducing E-R diagrams to relational schemas; extended E-R features like specialization, generalization, and aggregation; and differences between E-R diagrams and UML class diagrams. Key symbols used in E-R notation are also summarized.
L8 design1
This document provides an overview of relational database design and normalization. It discusses the goals of database design as generating schemas without unnecessary redundancy and allowing easy data retrieval. Normalization aims to design schemas in a desirable normal form, such as Boyce-Codd normal form (BCNF) or third normal form (3NF). The document introduces key concepts like functional dependencies, normal forms, decomposition, and closure of functional dependencies, which are used to determine if a schema is properly normalized and how to decompose schemas if necessary.
L9 design2
This document provides an overview of relational database design concepts including normal forms and decomposition. It begins with an outline of topics to be covered such as algorithms for functional dependencies, decomposition using multi-valued dependencies, normal forms, and modeling temporal data. The document then reviews Boyce-Codd normal form and provides examples of testing for and decomposing relations into BCNF. It also introduces third normal form and covers testing for and decomposing relations into 3NF. Finally, it briefly discusses multi-valued dependencies and compares BCNF and 3NF.
14 pro resolution
This document provides an overview of resolution in propositional logic. It introduces resolution as a new rule of inference that allows inferring a resolvent clause from two clauses. It describes how to convert arbitrary well-formed formulas into conjunctions of clauses to use with resolution. Resolution refutations are discussed as a way to decide logical entailments by attempting to derive the empty clause. Various strategies for conducting resolution refutation searches more efficiently are also covered, including ordering strategies and refinement strategies. Finally, the document defines Horn clauses and their special properties that allow for linear-time deduction algorithms.
13 propositional calculus
This document provides an overview of the Propositional Calculus. It discusses:
- The language of propositional calculus using atoms, connectives, and well-formed formulas
- Rules of inference like modus ponens, conjunction introduction, and disjunction introduction
- Defining proofs and theorems based on applying rules of inference
- Semantics by associating logical elements with truth values under interpretations
- Important concepts like validity, equivalence, entailment, and the soundness and completeness of rules of inference.
- The propositional satisfiability (PSAT) problem and solving techniques like exhaustive search and GSAT.
12 adversal search
This document discusses adversarial search techniques for two-agent games with perfect information. It introduces the minimax procedure and how it recursively assigns values to nodes in a game tree by maximizing the value for the maximizing agent and minimizing for the minimizing agent. The alpha-beta pruning technique is described which improves search efficiency by pruning subtrees that cannot alter the minimax value of the root. Examples of applying minimax and alpha-beta to tic-tac-toe are provided. The document also discusses handling games of chance using expectimax search and learning effective evaluation functions from self-play.
11 alternative search
This document discusses different approaches to solving constraint satisfaction problems including assignment problems. It provides examples of the eight queens problem and constraint propagation techniques. Constructive methods start with no assignments and add values satisfying constraints, while heuristic repair starts with a proposed solution and changes it to violate fewer constraints. Function optimization techniques like hill climbing and simulated annealing are also discussed.
10 2 sum
The document discusses different methods for reinforcement learning, including learning heuristic functions from experiences, learning in explicit and implicit graphs, using rewards instead of goals for tasks, and different algorithms like temporal difference learning and value iteration that help agents learn optimal policies by assigning credit to relevant state-action pairs.
22 planning
The document describes planning techniques in artificial intelligence, including STRIPS planning systems, forward and backward search methods, and partial-order planning. It discusses how STRIPS uses operators to describe state changes and searches for a sequence of actions to reach a goal state. Backward search methods work by regressing goals through operators to produce subgoals. Partial-order planning searches a plan space by transforming incomplete plans into more articulated plans until finding an executable plan.
21 situation calculus
This document provides an overview of the Situation Calculus, a formal logic framework for representing states, actions, and how actions transform states. It describes key components of the Situation Calculus including: (1) representing states as constants and using predicates to describe state properties, (2) representing actions and how they change state properties using effect axioms, (3) using frame axioms to represent properties that don't change with actions, and (4) generating plans by proving the existence of goal states and extracting the actions. Challenges with the approach include dealing with ramifications of actions and specifying all relevant preconditions and qualifications.
20 bayes learning
The document provides an overview of learning Bayes networks from data. It discusses learning the structure and conditional probability tables (CPTs) of a Bayes network given training data. When the network structure is known, the CPTs can be directly estimated from sample statistics in the training data, handling both cases of complete and missing data using techniques like expectation-maximization. When the structure is unknown, scoring metrics like minimum description length are used to search the space of possible structures to find the best fitting network. Dynamic decision networks extend this framework to model sequential decision making problems.
19 uncertain evidence
This document outlines probabilistic inference in Bayes networks. It begins with a review of probability theory concepts like joint probability, marginal probability, conditional probability, and Bayes' rule. It then discusses probabilistic inference in Bayes networks, including causal/top-down inference using evidence to determine probabilities, diagnostic/bottom-up inference using effects to determine causes, and "explaining away" where additional evidence makes other probabilities less certain. The document also covers uncertain evidence, D-separation to determine conditional independence, and inference techniques in polytrees.
18 common knowledge
This document discusses representing commonsense knowledge. It describes commonsense knowledge as everyday facts that most people understand, like objects falling when dropped or fish needing water. Representing all commonsense knowledge is difficult as there are no defined boundaries and some concepts cannot be described with sentences alone. The document outlines research areas in representing objects, materials, space, time, and physical processes. It also discusses knowledge representation using semantic networks and frames to organize taxonomic hierarchies and relationships between objects, properties, and categories in a graph structure. Nonmonotonic reasoning is also discussed for handling exceptions to default inferences.
17 2 expert systems
Rule-based expert systems use facts and rules to achieve expert-level competence in solving problems. They consist of a knowledge base containing facts and rules, an inference engine that manipulates the knowledge base to deduce information, and an explanation subsystem. Rule-based systems apply logical rules to the known facts to determine unknown information. Inductive logic programming learns rules by generalizing from examples to cover positive instances while avoiding negative ones.
17 1 knowledge-based system
The document discusses knowledge-based systems and their ability to reason over extensive knowledge bases. It addresses the theoretical problems of soundness, completeness, and tractability when using logical reasoning systems. Horn clauses and PROLOG are introduced as more efficient ways to perform inference compared to full predicate calculus. Different methods for reasoning including forward chaining and truth and assumption-based maintenance are also summarized.
16 2 predicate resolution
This document discusses resolution in predicate calculus. It covers topics like unification, predicate calculus resolution, converting well-formed formulas to clause form, using resolution to prove theorems, and answer extraction. It also discusses the equality predicate and paramodulation inference rule. The document provides examples to illustrate various concepts and techniques in resolution-based automated theorem proving in first-order logic.
16 1 predicate resolution
This document provides an outline and overview of key concepts in resolution in predicate calculus, including:
- Unification, which allows resolving clauses that have matching but complementary literals
- Converting formulas to clause form by eliminating quantifiers and connectives
- Using resolution to prove theorems by deriving the empty clause
- The equality predicate and paramodulation, an inference rule used with resolution when equality is present
The document describes these concepts over multiple sections and provides examples to illustrate predicate calculus resolution.
15 predicate
The document discusses the predicate calculus and its use for representing knowledge. It introduces the motivation and basic components of the predicate calculus language, including terms, well-formed formulas, and quantifiers. It explains the semantics of the language including interpretations, models, and the semantics of quantifiers. Finally, it provides examples of how predicate calculus can be used to conceptualize and represent knowledge about the world.
09 heuristic search
This document discusses various heuristic search algorithms including A*, iterative-deepening A*, and recursive best-first search. It begins by introducing the concept of using evaluation functions to guide best-first search and preferentially expand nodes with lower heuristic values. It then presents the general graph search algorithm and describes how A* specifically reorders nodes using an evaluation function that considers path cost and estimated cost to the goal. Consistency conditions for the heuristic function are discussed which guarantee A* finds optimal solutions.
08 uninformed search
This document discusses uninformed search algorithms. It outlines breadth-first search, depth-first search, and iterative deepening search. Breadth-first search finds the shortest path but uses exponential memory. Depth-first search uses linear memory but may explore large parts of the search space without finding the goal. Iterative deepening search combines the benefits of depth-first search and guarantees of finding the shortest solution like breadth-first search.
More from Tianlu Wang (20)
Phy b9 1-2
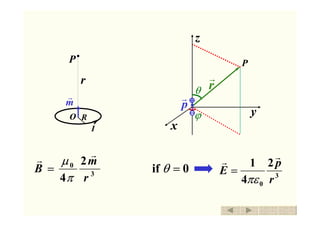
- 1. 3 0 2 4 r m B rr π µ = 3 0 2 4 1 r p E rr πε =0if =θ I P r O R m r P r r ϕ θ p r x y z 返回 退出
- 2. 3 0 2 4 1 r cosp Er θ πε = 3 04 1 r sinp E θ πεθ = 0=ϕE 3 0 2 4 r cosm Br θ π µ = 3 0 4 r sinm B θ π µ θ = 0=ϕB P r r ϕ θ p r x y z P r r ϕ θ m r x y z 返回 退出
- 3. 1x 2x l P R x x dx n 2 3 22 2 0 )(2 xR IndxR dB p + = µ ∫ + = 2 1 2 3 22 2 0 )(2 x xp xR IndxR B µ 3. Magnetic Field at any point along the center axis of a Solenoid )( 2 2 1 2 1 2 2 2 20 xR x xR xnI + + + = µ )cos(cos 2 12 0 ββ µ −= nI Bp 1β 2β Many turns of insulated wire coiled in the shape of a cylinder 载流螺线管内的磁场(轴线上) CAI 返回 退出 场点P 为坐标原点
- 4. 02 →→>> βπβRl 1 nIB 0µ= 0 2 21 →= β π β nIB 0 2 1 µ= )cos(cos 2 12 0 ββ µ −= nI Bp 2. semi-infinite 1. infinite solenoidtheofendleft : CAI 返回 退出 1β 2β P R x l
- 5. 磁通量 SBΦm rr dd ⋅= ∫∫ ⋅= sm SBΦ rr d wbmT 2 =⋅ B r S S r d ⊥== SBSθBΦm ddcosd Magnetic flux SI unit CAI 返回 退出 Sd Gauss theorem for electricity ∫∫ ε=⋅ s /qSE 0d rr ∫∫ =⋅ s ?SB rr d
- 6. 2S 1S ∫∫ ⋅= sm SdB rr Φ The Magnetic flux through a closed curve L ↔ The Magnetic flux through any open surface which has a common boundary in the 返回 退出 The Magnetic flux through a closed curve L S L B r closed curve L
- 7. ∫∫ =⋅ s SdB 0 rr 返回 退出
- 8. 3 0 4 r rlId Bd rr r × = π µ L rrr 321 、、、 lIdlIdlId L rrr 321 、、、 BdBdBd L321 、、、 ΦΦΦ ddd 0321 =+++= LΦΦΦΦ dddm ∫∫ =⋅= sm SdB 0 rr Φ lId r θ r r 任一电流总是由许多电流元组成 返回 退出 Gauss Theorem for Magnetism 磁高斯定理
- 9. ∫∫ =⋅ s qSdE 0/ε rr ∫∫ =⋅ s SdB 0 rr 有源场 无源场 发散状 涡旋状 Gauss Theorem for Magnetism 返回 退出 原因:自然界不存在磁单极 (magnetic monopole) 我们所讨论的磁场都不是单个磁极所产生的 ∫∫ ∫∫∫ =⋅∇=⋅ S V dVBSdB 0 rrr 0=⋅∇ B r 利用高斯公式 ( Gauss formula ) 0ε ρe E =⋅∇ r 磁高斯定理
- 10. 1931年 狄拉克(P. A. M. Dirac) 从理论上证明,如果存在磁单极,就可对电荷的量子 化提供一种解释。 磁单极概念提出后的几十年中,与磁单极有关的理论 有很大的发展。 电磁场理论、量子力学理论、规范场、基本粒子理论、… 拓扑学、李群、纤维丛、 … 迄今为止,没有充分的依据可以证明磁单极确实存在。 返回 退出 2 n qqm = …= ,,,,n 3210
- 11. 20世纪60年代 美国阿波罗计划 登月飞行 先后从月球运回许多月球岩石 1975年 加州大学 装有探测宇宙射线仪器的气球 距地面 40km 的高空 记录到一条电离性很强粒子留下的径迹 斯坦福大学 超导磁单极探测器 1982年2月14日 磁通量突然有很大变化 与一个磁单极引起的变化相当 返回 退出 Cobrera Price 216 cGeV10 /