Download as PDF, PPTX































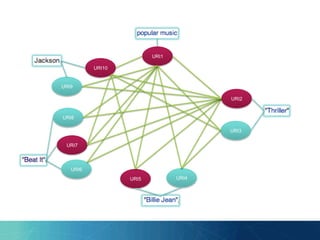

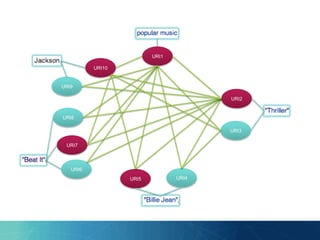
![“The number of contexts [entities] is
overwhelming and had to be reduced to
a manageable size.”
- Cucerzan 2007](https://image.slidesharecdn.com/presentation-140812113218-phpapp01/85/PhD-Day-Entity-Linking-using-Ontology-Modularization-43-320.jpg)
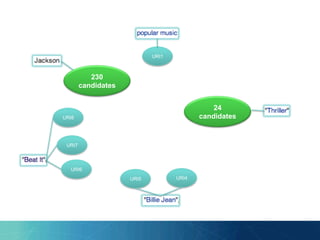
![“Much speed is gained by imposing a
threshold below which all senses
[candidates] are discarded”
- Milne and Witten 2008](https://image.slidesharecdn.com/presentation-140812113218-phpapp01/85/PhD-Day-Entity-Linking-using-Ontology-Modularization-44-320.jpg)


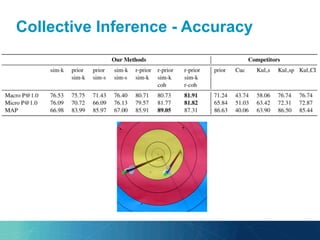










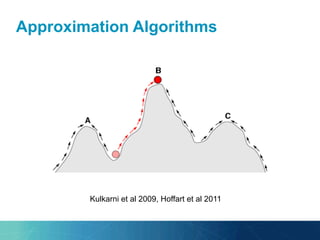



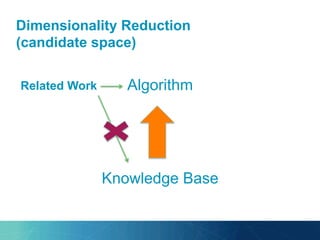













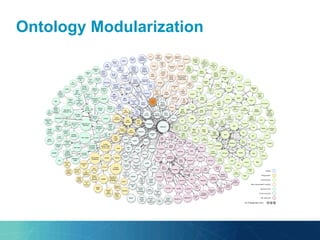
















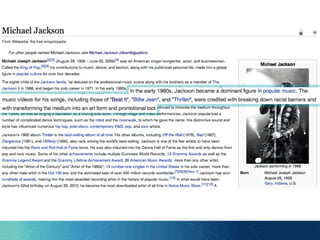
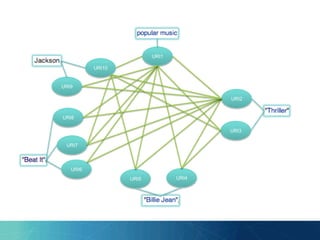
The document outlines the PhD research of Bianca Pereira, focusing on entity linking, which involves grounding entity mentions in documents to knowledge base entries. It discusses the challenges of disambiguation in large knowledge bases and proposes solutions like approximation algorithms and dimensionality reduction to improve accuracy and efficiency. The research questions and hypotheses aim to explore the potential for manageable disambiguation times regardless of knowledge base size, as well as the effectiveness of exact algorithms in this context.































































