L'approccio esaminato in questo documento propone l'apprendimento automatico di grafi concettuali da testi, affrontando la complessità intrinseca del linguaggio naturale. Utilizzando tecniche di analisi sintattica e ragionamento probabilistico per collegare concetti, il metodo evita risorse esterne e mira a migliorare la rappresentazione della conoscenza. I risultati preliminari suggeriscono che l'approccio è promettente, sebbene richieda ulteriori sviluppi e sperimentazioni.



![Our framework*
4/23
1. Capable to build a conceptual network
Syntactic analysis by Stanford Parser [1] and Stanford
Dependencies [2]
Handles positive/negative and active/passive form of sentence
Relationships between subject and (direct/indirect) object
2. Performs generalizations to tackle data poorness and thus to enrich
the graph
3. Performs reasoning ‘by association' to look for relationships
between concepts
(*) F. Leuzzi, S. Ferilli, F. Rotella, “Improving Robustness and Flexibility of Concept Taxonomy Learning from Text”, New Frontiers in
Mining Complex Patterns, pg. 170-184, 2013, ISBN 978-3-642-37381-7](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-4-2048.jpg)
![Limits
● Anaphoras not handled
● Concepts Clustering using flat/vectorial-representations
● Concepts Generalization based on external resources
(eg. Wordnet [3])
● Focused mainly to the definitial portion of the network
5/23
Our framework](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-5-2048.jpg)

![Conceptual Graph Construction
The final output is a typed syntactic structure of each sentence.
Stanford
Parser
Stanford
Dependencies
JavaRAP[4]
STEP 1: Pre-processing
STEP 2: Sentences elaboration
input texts
w/o anaphoras
7/23](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-7-2048.jpg)


![Relational Concept Description
1. Weak Components of the graph extracted by JUNG [5]
A maximal sub-graph in which at least a path exists between
each pair of vertices
2. For each concept k-neighborhood around it has been extracted
a sub-graph induced by the set of concepts that are k or fewer
hops away from it
3. Conceptual Graph translated into a set of Horn clauses:
● <subj, verb_{pos,neg}, compl> → {pos, neg}_verb(subj, compl)
● eg. dog eats bone → pos_eat(dog, bone)
● concept(X):-rela(X,Y), relb(Z,X), relc(Y,T)
● eg. concept(dog):-
pos_eat(dog,bone),pos_spit(cat,bone),neg_eat(dog,mouse)
11/23](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-10-2048.jpg)
![Relational Pairwise clustering
Exploits the relational representation of concepts
The similarity measure formulae similutudo [6] provides a relational
similarity evaluation between them.
12/23
concept(X):-
rela(X,Y),
relb(Z,X),
relc(Y,T).
concept(K):-
relb(K,Y),
reld(Z,K),
relf(Y,T),
rela(Z,T).
fs( C',C'' )](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-11-2048.jpg)
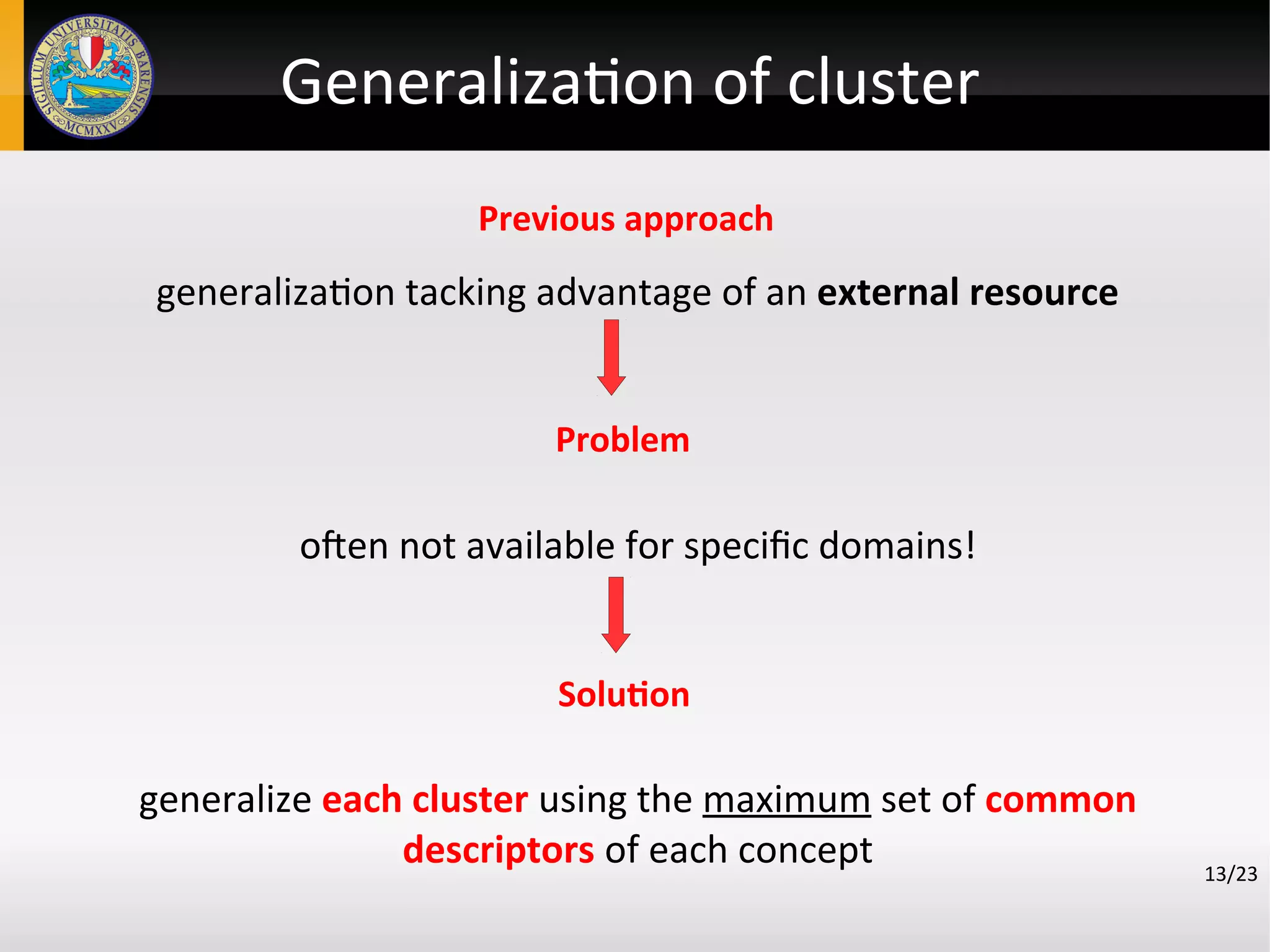
![Generalization of cluster
14/23
1. Performing the logical generalization operator in [7]
• a least general generalization (lgg) under ϴOI − subsumption
of two clauses is a generalization which is not more general
than any other such generalization, that is, it is either more
specifc than or not comparable to any other such
generalization.
2. Exploitable for:
retrieval of documents of interest
Introducing new taxonomical relationships
shifting of the representation when needed (abstraction)](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-13-2048.jpg)
![Probabilistic reasoning ‘by association’
Reasoning ‘by association’ means:
Finding a path of pairwise related concepts that establishes an
indirect interaction between two concepts c′ and c′′
Real Word Data is noisy and uncertain
Logical reasoning is conclusive, need of a probabilistic approach
Exploit sof relationships among concepts
Two strategies (B) and (D):
(B) works in breadth aims at obtaining the minimal path between
concepts together with all involved relations
(D) works in depth and exploits ProbLog [8] in order to allow
probabilistic queries on the conceptual graph
15/23](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-14-2048.jpg)



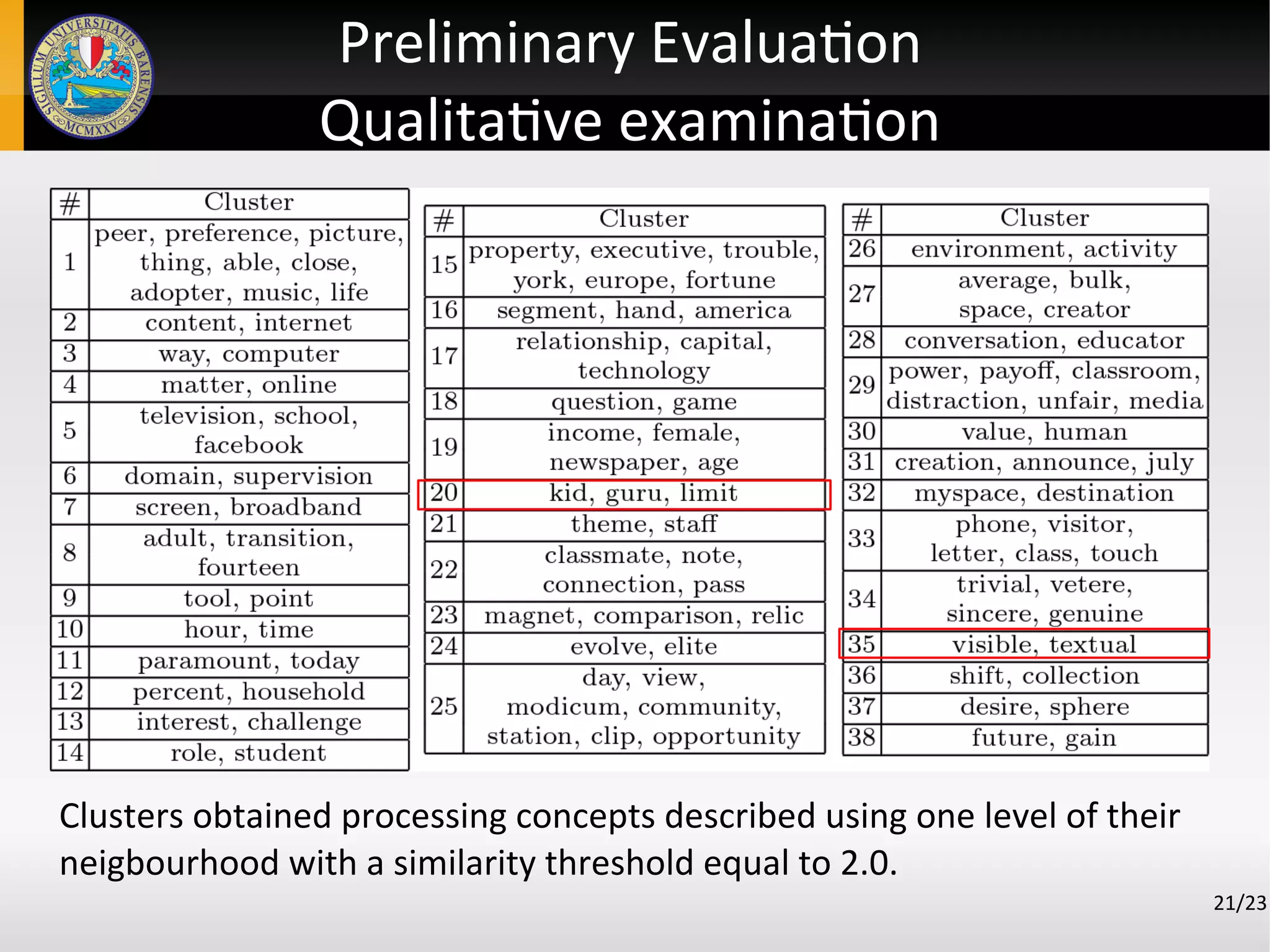
![Preliminary Evaluation
Experimental setting
17/23
Goal: evaluate the qualitative examination of the obtained clusters and
their generalizations.
The dataset regards 18 documents about social networks.
The size of the dataset was deliberately kept small in order to have poor
knowledge.
The similarity function returns value in ]0,4[ .
The similarity function threshold has been in [2.0, 2.3] with hops equal
to 0.5.
The graph built from text included:
● 695 concepts
● 727 relations](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-19-2048.jpg)






![References
[1] Klein and C. D. Manning. Fast exact inference with a factored model for natural
language parsing. In Advances in Neural Information Processing Systems, volume 15.
MIT Press, 2003.
[2] M.C. de Marneffe, B. MacCartney, and C. D. Manning. Generating typed depen-
dency parses from phrase structure trees. In LREC, 2006.
[3] C. Fellbaum, editor. WordNet: An Electronic Lexical Database. MIT Press, Cam-
bridge, MA, 1998.
[4] L Qiu, M.Y. Kan, and T.S. Chua. A public reference implementation of the rap
anaphora resolution algorithm. In Proceedings of LREC 2004, pages 291–294, 2004.
[5] J. O’Madadhain, D. Fisher, S. White, and Y. Boey. The JUNG (Java Universal
Network/Graph) Framework. Technical report, UCI-ICS, October 2003.
[6] S. Ferilli, T. M. A. Basile, M. Biba, N. Di Mauro, and F. Esposito. A general similarity
framework for horn clause logic. Fundam. Inf., 90(1-2):43–66, January 2009.
[7] G.Semeraro,F.Esposito,D.Malerba,N.Fanizzi,andS.Ferilli.Alogicframework for the
incremental inductive synthesis of datalog theories. In Norbert E. Fuchs, editor,
LOPSTR, volume 1463 of LNCS, pages 300–321. Springer, 1997.
[8] L. De Raedt, A. Kimmig, and H. Toivonen. Problog: a probabilistic prolog and its
application in link discovery. In In Proc. of 20th IJCAI, pages 2468–2473. AAAI Press,
2007.](https://image.slidesharecdn.com/ieaaie2013paper123-130624113648-phpapp02/75/An-Approach-to-Automated-Learning-of-Conceptual-Graphs-from-Text-27-2048.jpg)

























































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)











![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
