Downloaded 30 times



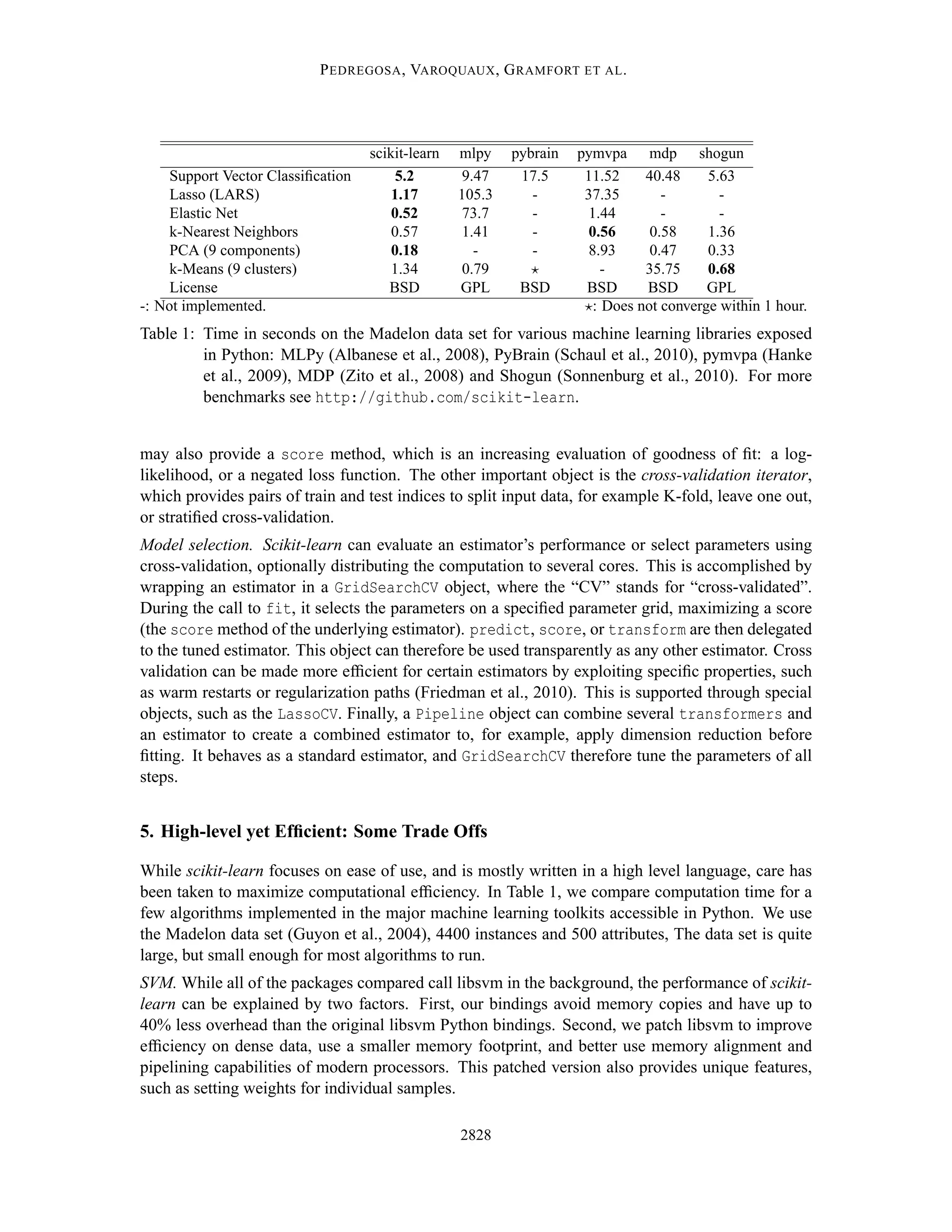



- Scikit-learn is a Python module for machine learning that provides simple and efficient tools for data mining and data analysis. - It incorporates optimized algorithms like support vector machines and linear models while maintaining an easy-to-use interface. - The goal is to make machine learning accessible to non-experts through a consistent API and minimal dependencies.