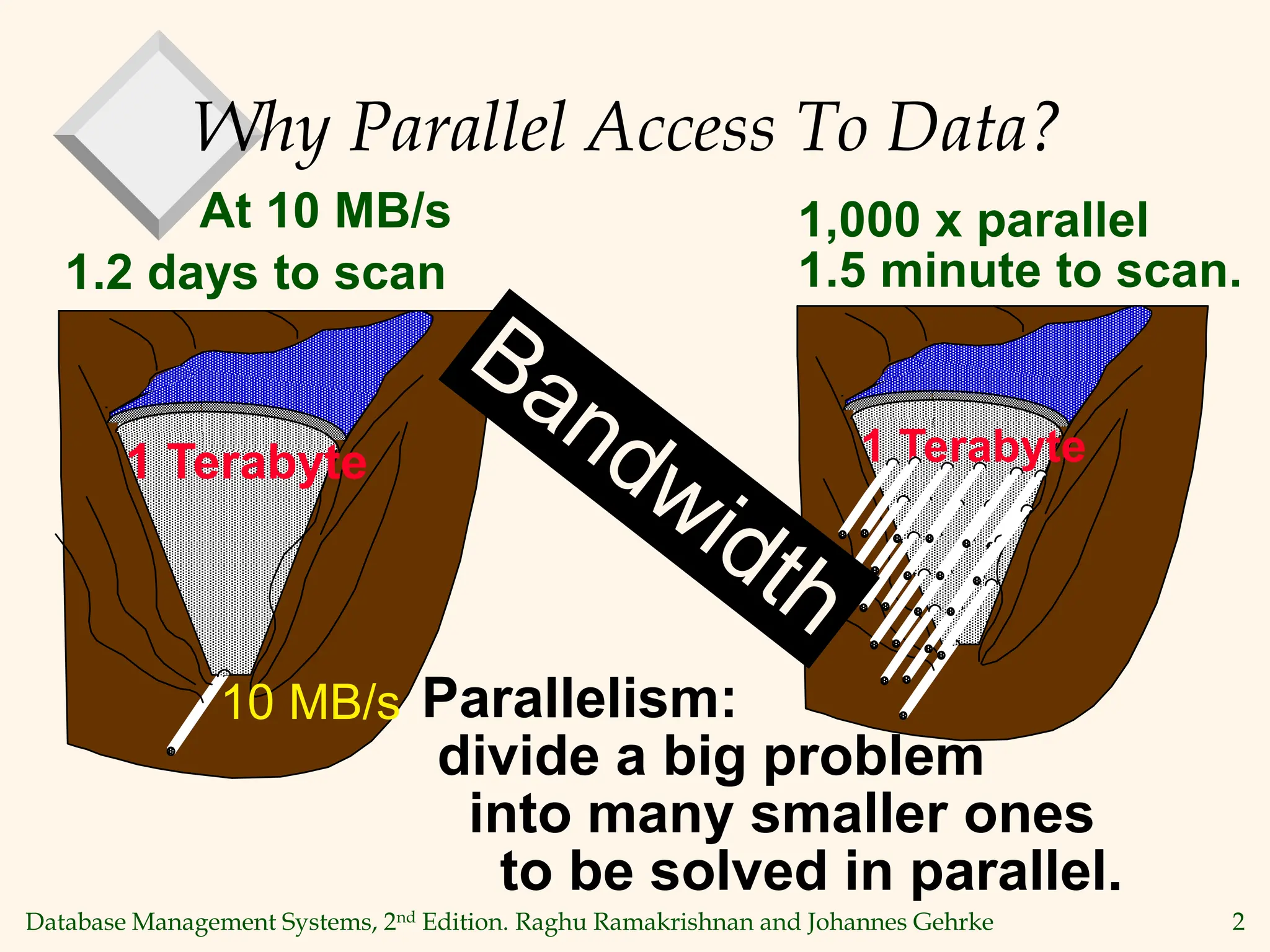
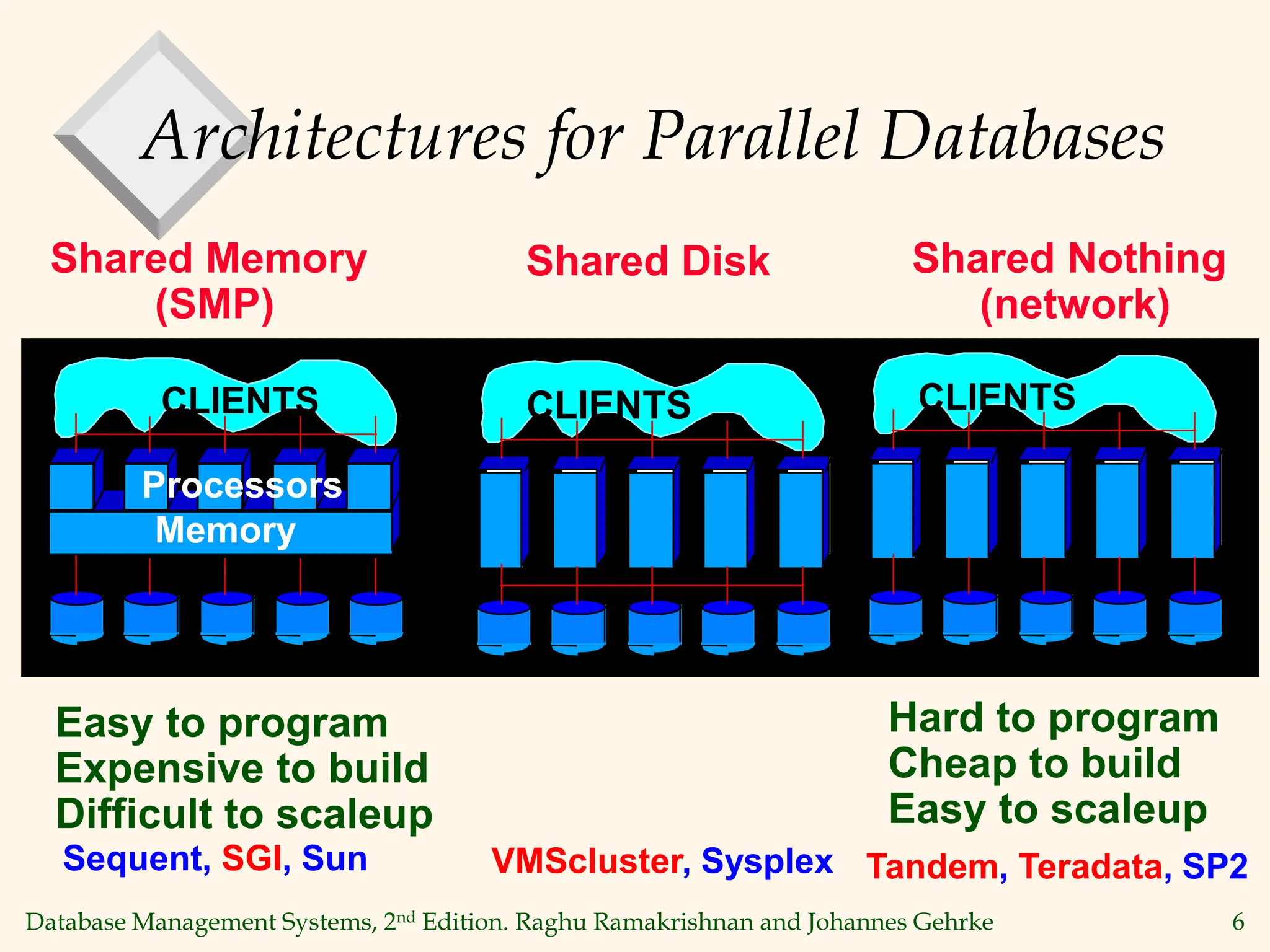
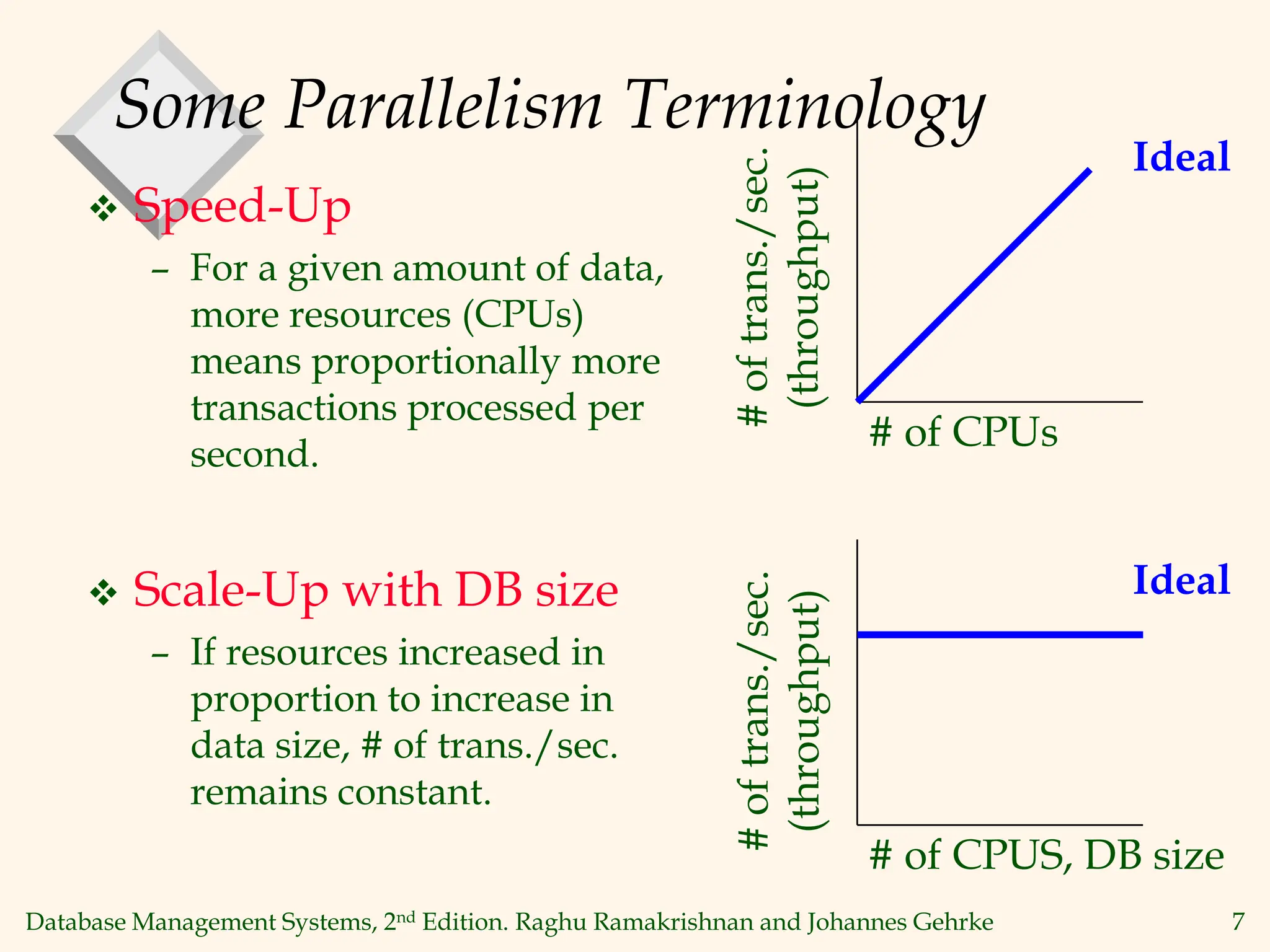
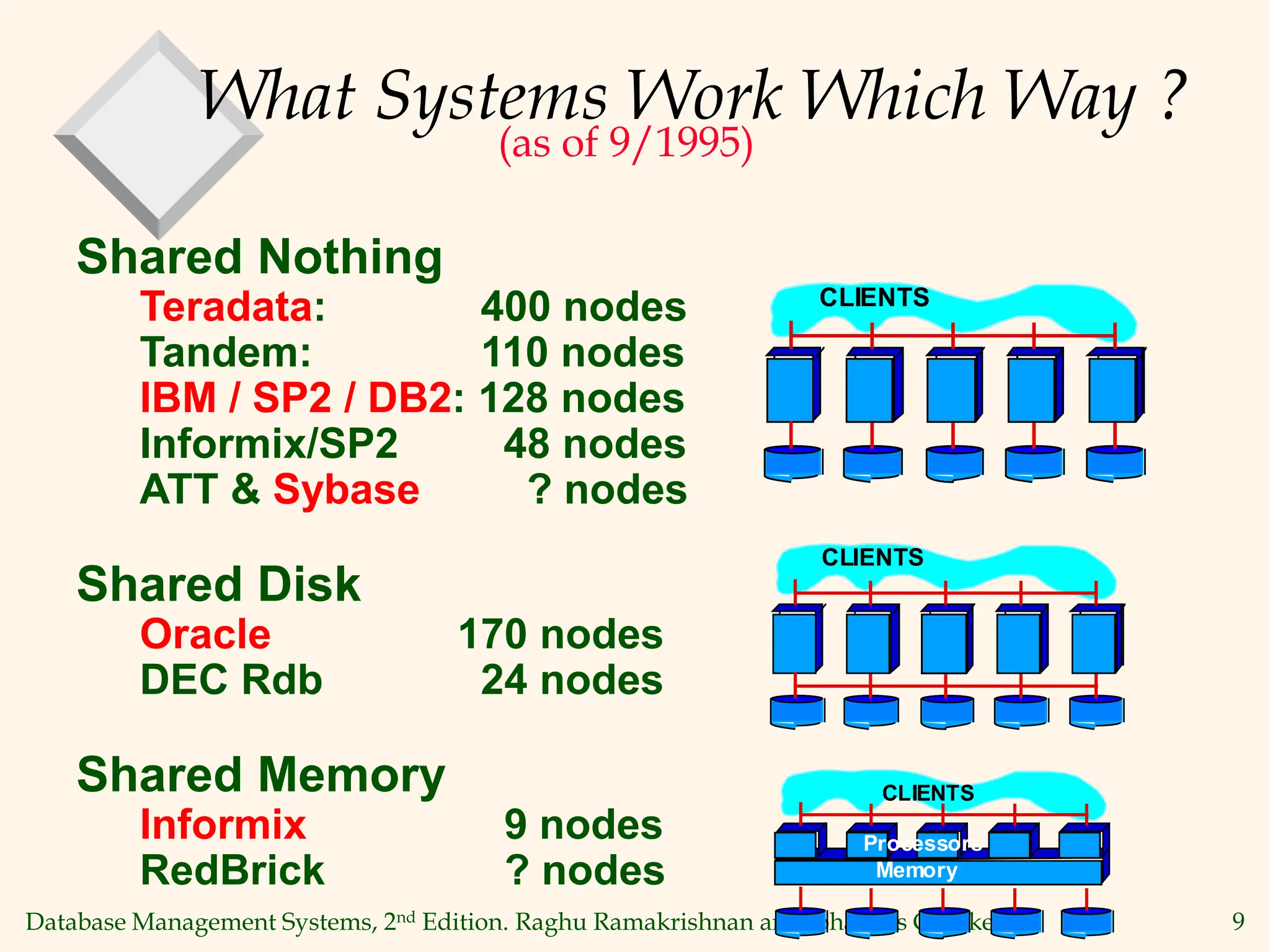
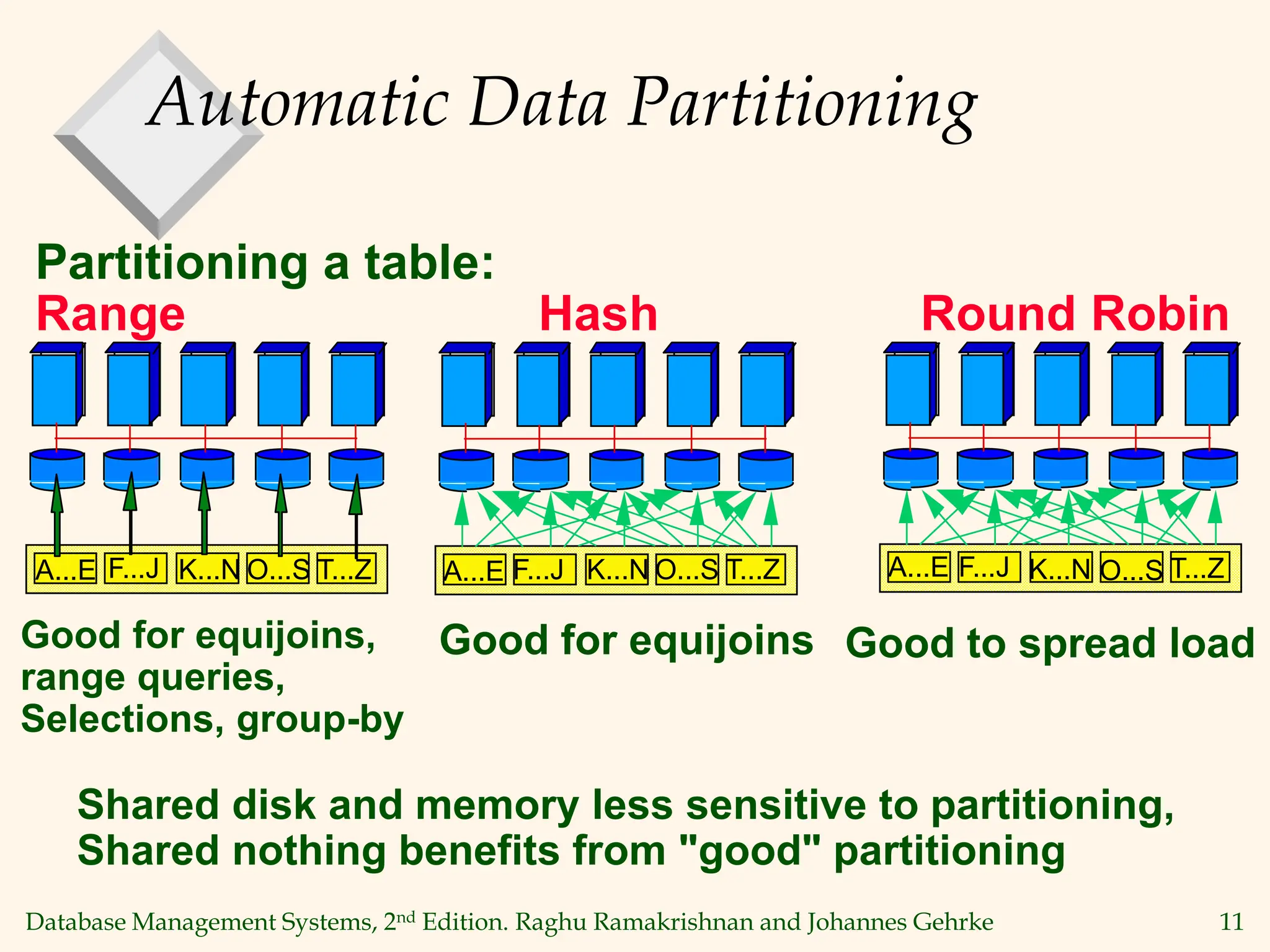
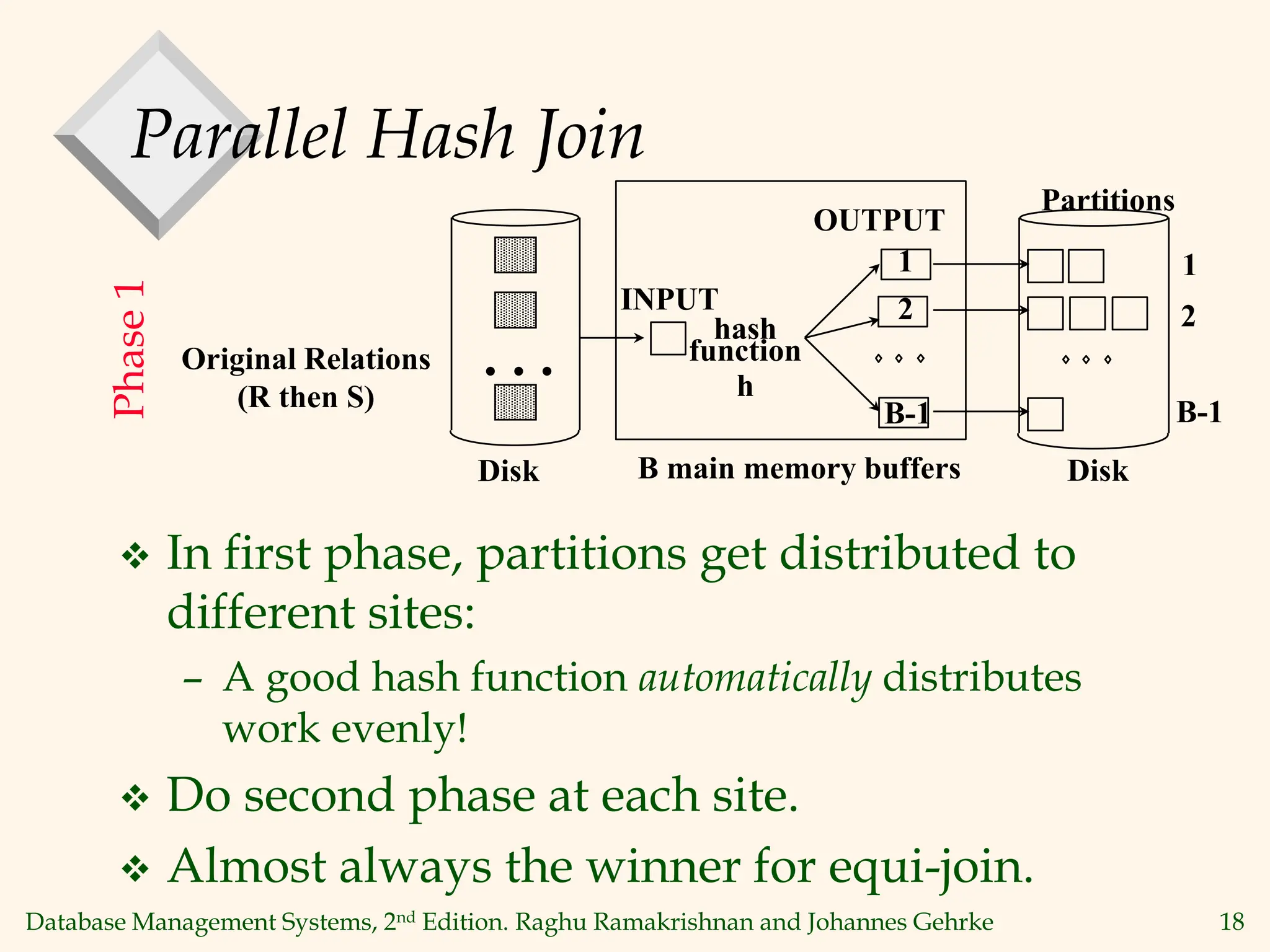
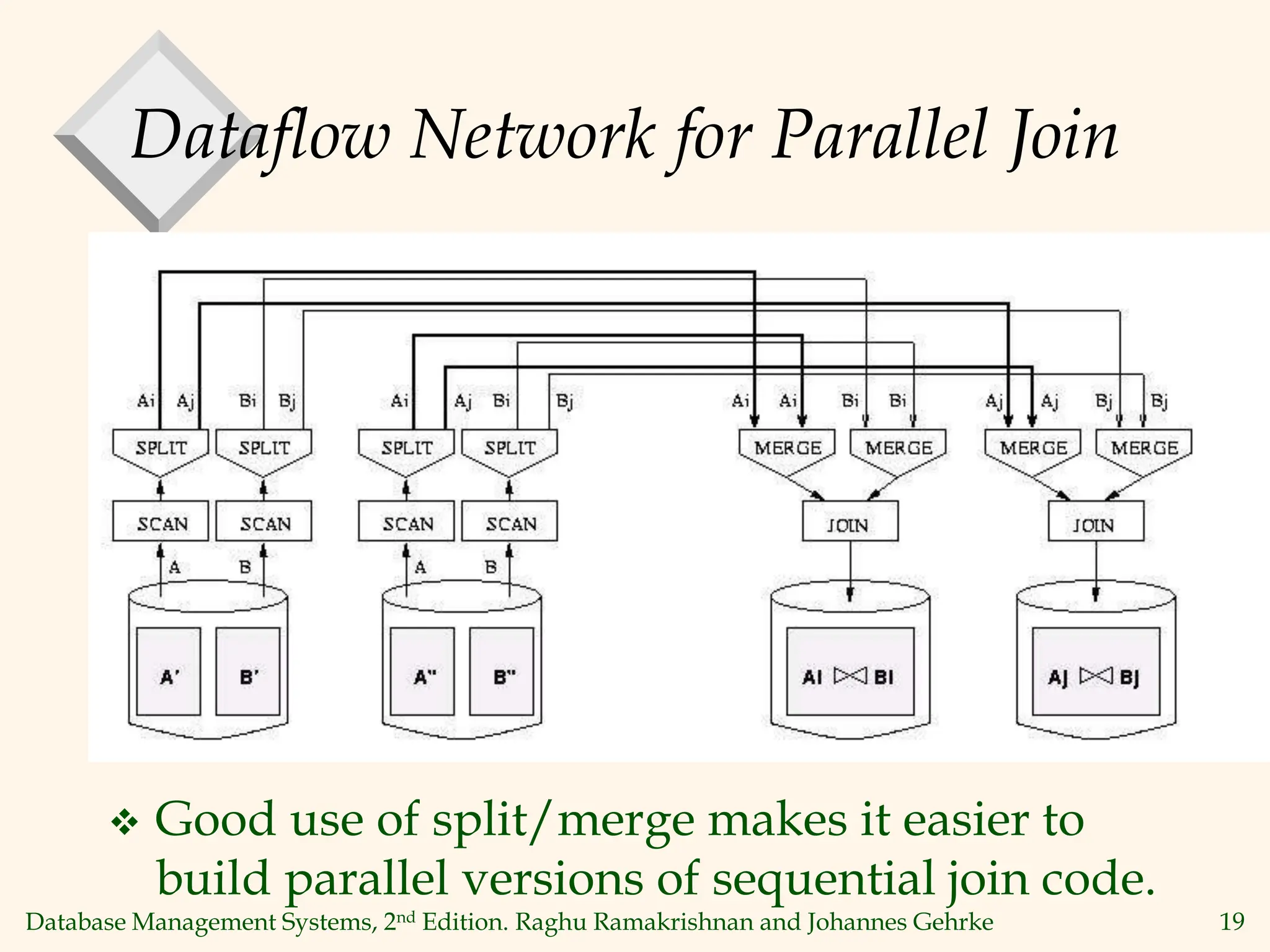
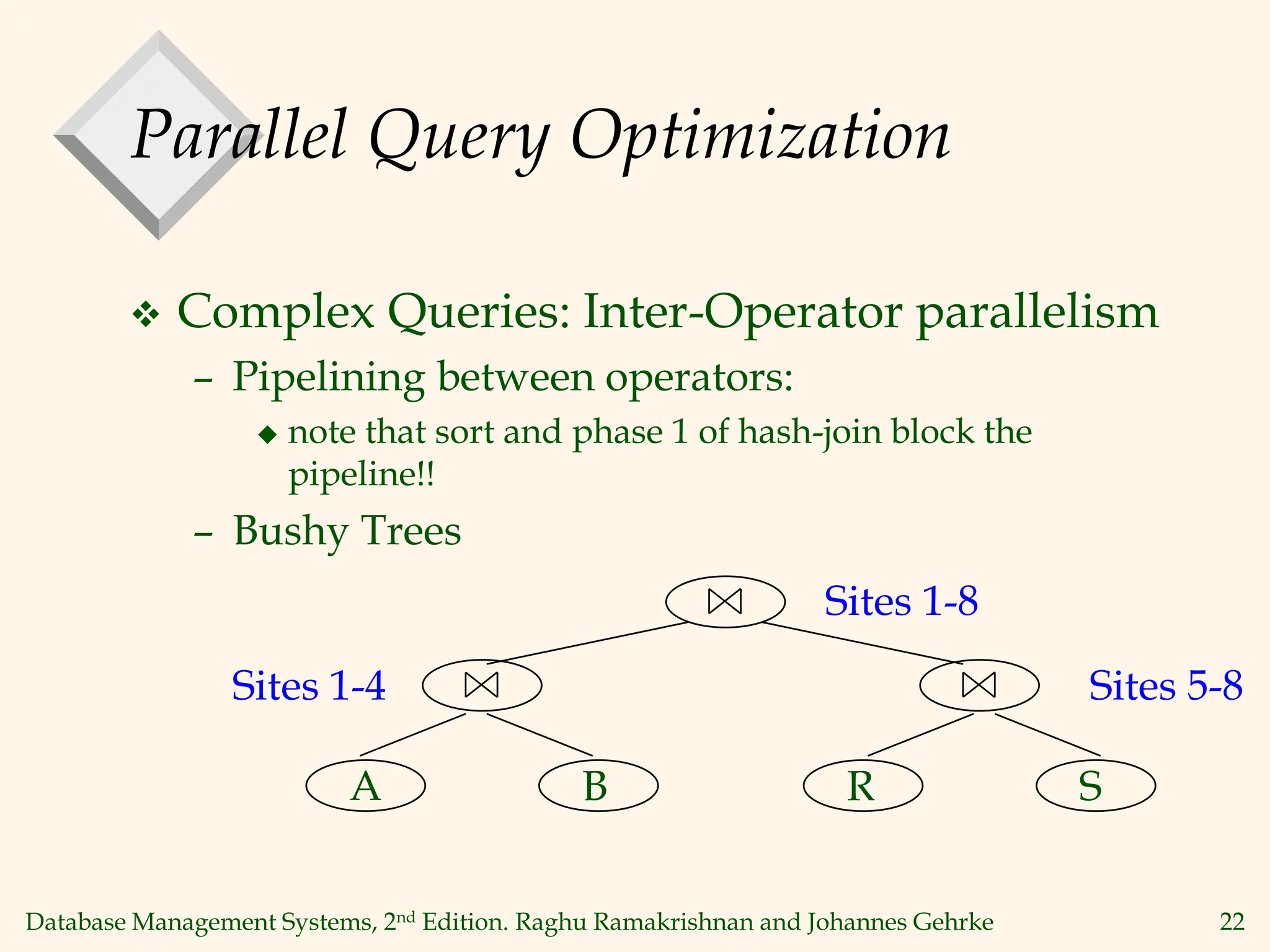
This document discusses parallel database management systems. It covers different architectures for parallel databases including shared memory, shared disk, and shared nothing. It also discusses techniques for parallelizing database operations like scanning, sorting, joining, and querying through techniques like partition parallelism and pipeline parallelism. The key challenges in parallel databases are data partitioning, query optimization, and transaction processing across multiple nodes.





























![[Www.pkbulk.blogspot.com]dbms13](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comdbms13-130615034551-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































