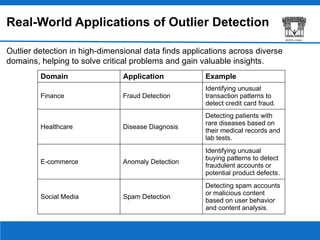
Outliers are significant deviations in data that can arise from errors or represent genuine exceptional cases, affecting statistical measures and the performance of machine learning models. High-dimensional data presents unique challenges for outlier detection, necessitating advanced techniques like dimensionality reduction, distance-based methods, and clustering. These methods are applied in various fields, including finance, healthcare, and e-commerce, but require careful consideration of overfitting, data quality, domain expertise, and ethical implications.