Download as PDF, PPTX




















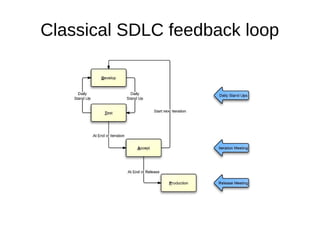
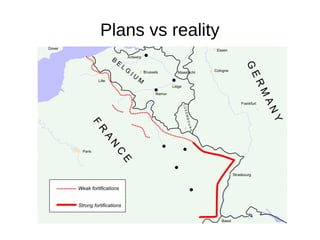


























The document discusses various topics related to software testing and development including testing environments vs reality, risk management approaches, monitoring software usage through event processing and generating alerts. It notes that testing environments often differ significantly from production with unstable conditions, humans and latency. Two approaches to risk management are described: narrowly scoping problems and extensive testing vs rapid iteration, testing changes in real world, and only keeping what works. Event processing and monitoring tools can provide real-time insights into software usage and changes.







































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)







