Downloaded 12 times






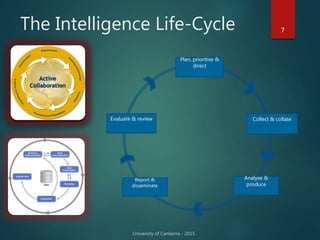


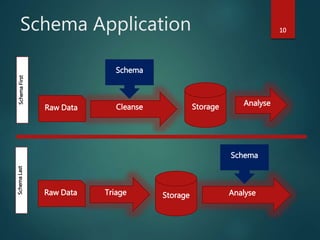
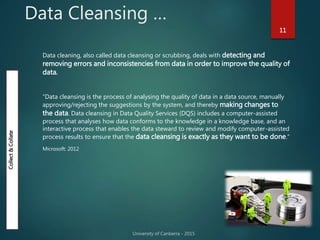
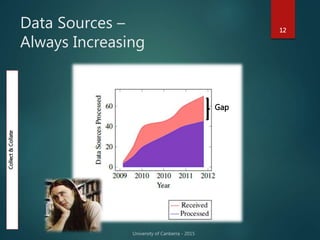






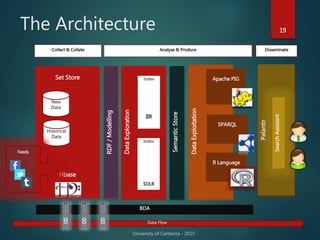
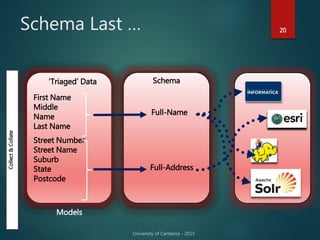

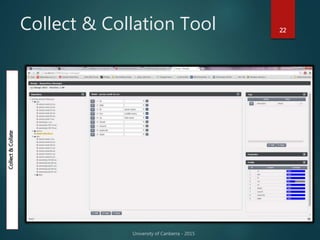
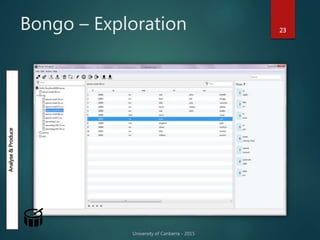
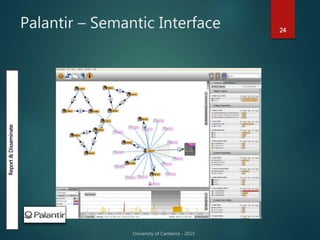

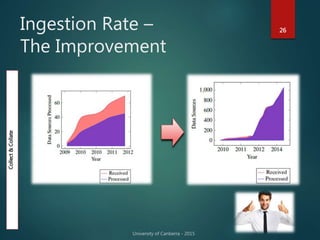



The document outlines Dr. Neil Brittliff's approach to leveraging big data within the context of law enforcement and criminal intelligence, focusing on a schema-last approach to data management. It discusses the challenges of data cleansing and transformation in the intelligence life-cycle and highlights the benefits of improved data integration and analysis through advanced technological solutions. The material emphasizes the need for efficient data ingestion processes and the importance of collaboration among various agencies to enhance crime analysis in Australia.



![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













































































