Downloaded 83 times




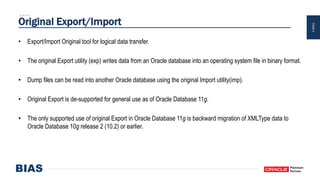
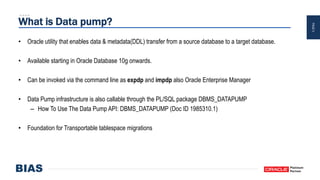



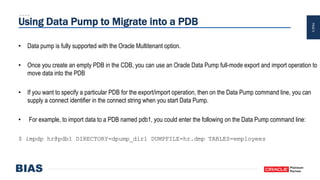

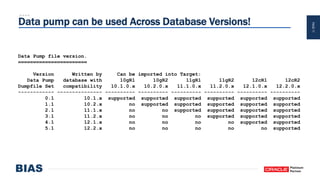
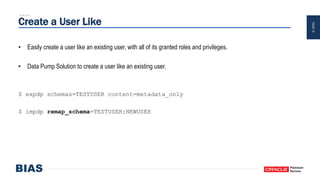


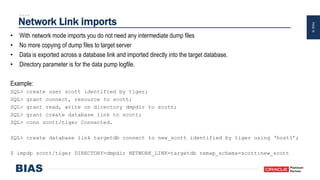

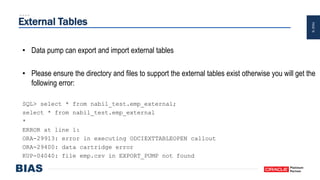

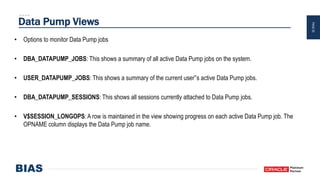




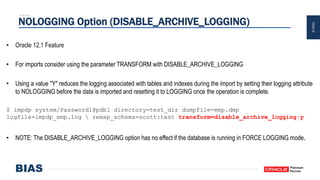






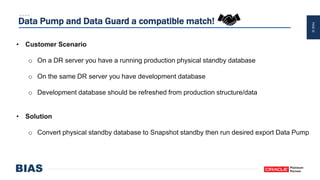
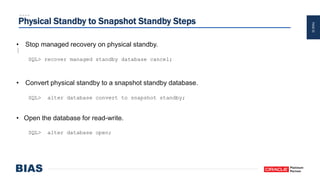
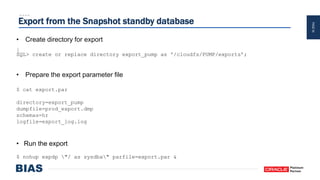






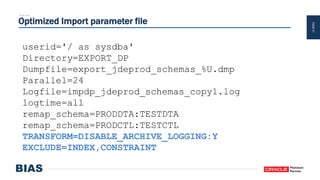
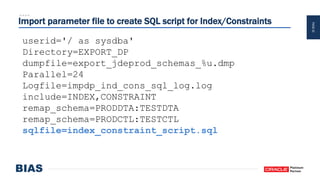
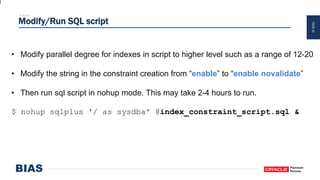








The document provides an overview of optimizing Oracle database imports using the Data Pump utility, highlighting its features, benefits, and various scenarios for effective data migration. It includes technical insights from Nabil Nawaz, detailing command line operations, parallel processing, and optimizations for import operations, alongside case studies that demonstrate best practices. Key discussions cover migration to Oracle Cloud, handling external tables, and managing schema remapping during imports.



































































