Downloaded 27 times






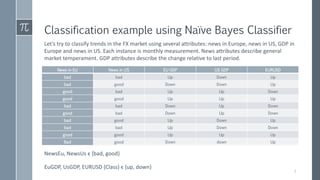


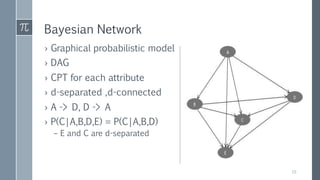

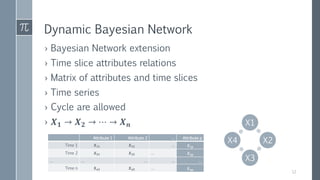



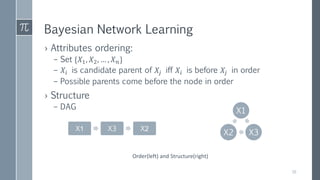



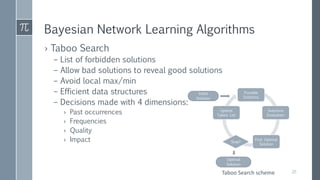
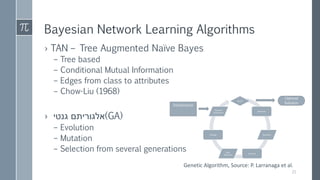

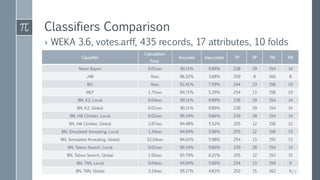
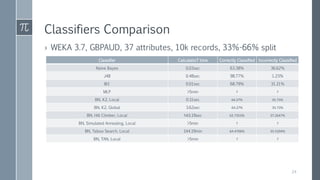




This document discusses optimal Bayesian networks for classification problems. It covers Bayesian network concepts like DAGs, CPTs, and probability inference. Naive Bayes and Bayesian network classifiers are presented with examples. Learning Bayesian networks from data is discussed, including structure and parameter learning algorithms like K2, hill climbing, simulated annealing, and TAN. Computational challenges like combinatorial optimization and feature selection are addressed. Comparisons of classifier performance on real datasets demonstrate Bayesian networks can achieve high accuracy.















































