NIPS2013読み会: More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server
NIPS2013読み会の発表資料です。
Qirong Ho et al, "More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server ", NIPS2013.
http://media.nips.cc/nipsbooks/nipspapers/paper_files/nips26/631.pdf
NIPS2013読み会: More Effective Distributed ML via a Stale Synchronous Parallel Parameter Server
1.
NIPS読み会
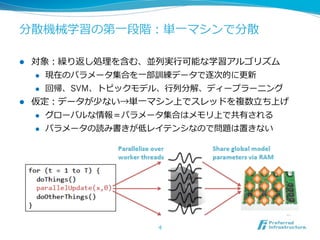
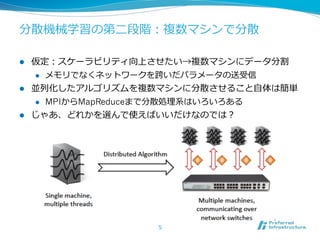
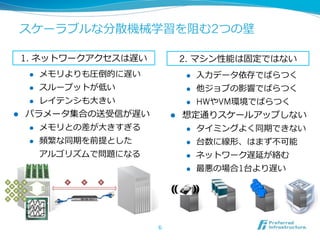
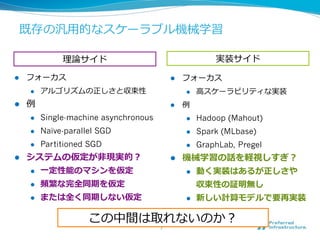
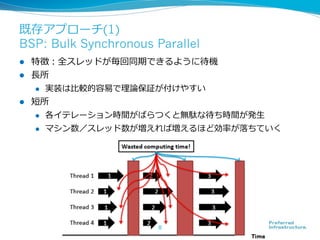
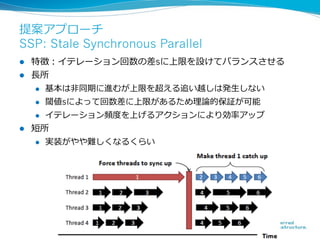
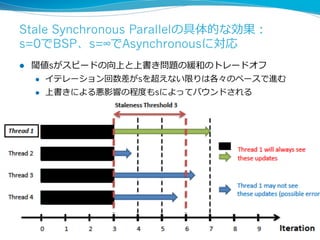
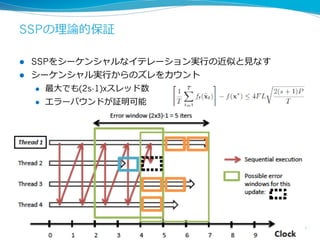
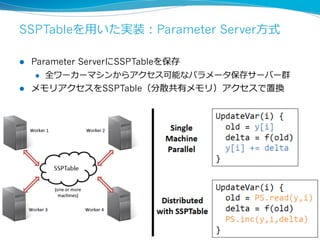
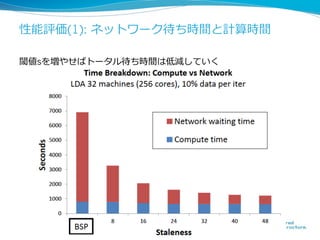
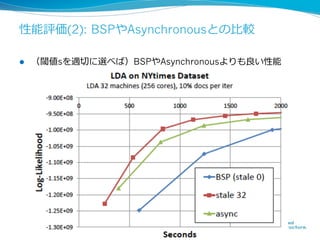
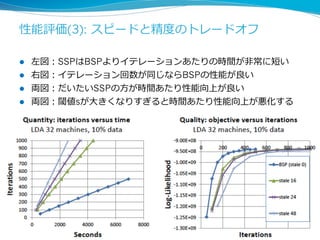
More Effective DistributedML
via a Stale Synchronous
Parallel Parameter Server
Qirong
Ho
et.
al.
CMU
&
Intel
Labs
詠み⼈人
株式会社Preferred Infrastructure
⽐比⼾戸 将平
参考⽂文献
l
"More Effective DistributedML via a Stale Synchronous Parallel Parameter
Server", Qirong Ho, James Cipar, Henggang Cui, Jin Kyu Kim, Seunghak Lee,
Phillip. B. Gibbons, Garth A. Gibson, Greg R. Ganger, Eric P Xing. Neural
.
Information Processing Systems, 2013 (NIPS 2013)
l
"Structure-Aware Dynamic Scheduler for Parallel Machine Learning", Seunghak
Lee, Jin Kyu Kim, Qirong Ho, Garth A. Gibson, Eric P Xing. arXiv:1312.5766
.
(2013)
l
"Petuum: A Framework for Iterative-Convergent Distributed ML", Wei Dai,
Jinliang Wei, Xun Zheng, Jin Kyu Kim, Seunghak Lee, Junming Yin, Qirong Ho,
Eric P Xing. arXiv:1312.7651 (2013)
.
l
"Consistency Models for Distributed ML with Theoretical Guarantees", Jinliang
Wei, Wei Dai, Abhimanu Kumar, Xun Zheng, Qirong Ho, Eric P Xing. arXiv:
.
1312.7869 (2013)
18