The document discusses various aspects of full-text search (FTS) in MySQL including:
1) FTS query syntax using MATCH() AGAINST() and different search modes.
2) Details on FTS indexing including inverted index structure, caching, and optimization.
3) Explanations of different FTS parsers like delimiter, ngram, and stemming and their effect on tokenization and index size.
4) Factors impacting FTS performance like result set size, ngram token size, and multi-gram indexing.









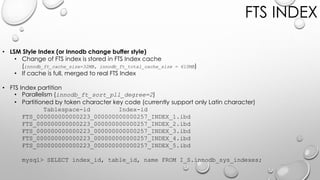


![Token iList
MySQL
Fulltext
FTS INDEX
• INVERTED INDEX
• Index entry = [token - iList] pair
• iList = [document-id, position] list
• iList has position
• Support proximity search
• Index size vs Common(Frequent) token
• Index size vs FTS Index cache
doc-id(1), pos(3) doc-id(4), pos(1) doc-id(7), pos(12)
doc-id(1), pos(8) doc-id(6), pos(21) doc-id(9), pos(3) doc-id(13), pos(9)](https://image.slidesharecdn.com/02-170828223133/85/nGram-full-text-search-by-13-320.jpg)

























![[오픈소스컨설팅]인프라 자동화 도구 Chef](https://cdn.slidesharecdn.com/ss_thumbnails/chef-171123014826-thumbnail.jpg?width=640&height=640&fit=bounds)











































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)














