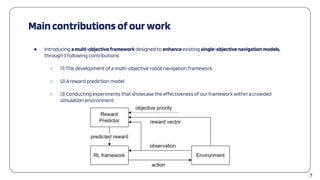
The document presents a multi-objective deep reinforcement learning framework designed for socially aware mobile robot navigation, addressing the challenges of navigating crowded environments while adhering to social rules. Key contributions include the development of a reward prediction model and experiments demonstrating improved navigation performance in simulations. The framework aims to enhance traditional navigation models by integrating user-defined priorities and eliminating the need for manually crafted reward functions.






![10
UserPreferences Modeling
● We proposed Object Order: o = [𝑜1, … , 𝑜𝑑] ∊ 𝑂, which defines the priority of each objective. The first
objective in o (𝑜1) has the highest priority and vice versa.
● The 𝑟𝑖
is preferable to 𝑟𝑗
following order o : 𝑟𝑖
≻𝑜 𝑟𝑗
if
∃ 𝑟𝑥
𝑖
> 𝑟𝑥
𝑗
|𝑜𝑥 ∈ 𝑜
∄ 𝑟𝑦
𝑖
< 𝑟𝑦
𝑗
|𝑜𝑦 ∈ 𝑜 & 𝑜𝑦 ℎ𝑎𝑠 ℎ𝑖𝑔ℎ𝑒𝑟 𝑝𝑟𝑖𝑜𝑟𝑖𝑡𝑦 𝑡ℎ𝑎𝑛 𝑜𝑥 (2)](https://image.slidesharecdn.com/iccais2023-240717035714-65d62408/85/Multi-Objective-Deep-Reinforcement-Learning-with-Priority-based-Socially-Aware-Mobile-Robot-Navigation-Frameworks-10-320.jpg)



![15
Our proposedMulti-Objective Robot navigation
framework
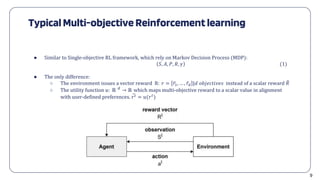
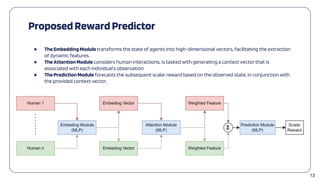
● With Reward Predictor: 𝑅 = 𝐹 𝑆 |𝑂, which predicts scalar rewards from observed states satisfying
predefined Objective Order.
● We can convert a multi-objective RL framework to a single-objective one.
[𝑠𝑡
, 𝑟𝑡
, 𝑠𝑡+1
] → [𝑠𝑡
, 𝑟𝑡
= 𝐹(𝑠𝑡+1
) | o, 𝑠𝑡+1
]](https://image.slidesharecdn.com/iccais2023-240717035714-65d62408/85/Multi-Objective-Deep-Reinforcement-Learning-with-Priority-based-Socially-Aware-Mobile-Robot-Navigation-Frameworks-15-320.jpg)


![18
Experiment Setup
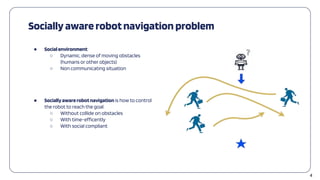
● Simulation environment (adopt from SARL):
○ Invisible robot
○ Holonomic
○ Number of humans: 5, 10, 15, 20
● Baseline: SARL [1]
● SARLwithin our framework: SARL_f
○ Predefined Objective Order:
○ Reward predictor: f
○ RL Framework: SARL
● Trainingepisodes: 20.000
[1] C. Chen, Y. Liu, S. Kreiss, and A. Alahi, “Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning,” in 2019
International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 6015–6022.](https://image.slidesharecdn.com/iccais2023-240717035714-65d62408/85/Multi-Objective-Deep-Reinforcement-Learning-with-Priority-based-Socially-Aware-Mobile-Robot-Navigation-Frameworks-18-320.jpg)