Download to read offline

















![Introduction
Lucene
MTAS
Tokenizer FoLiA
Search using CQL
Results
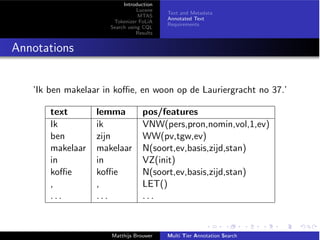
Search using CQL
the big green shiny apple
LID ADJ ADJ ADJ N
Ambiguities illustrated by examples
[pos = ”LID”|word = ”the”] (1)
[word = ”b. ⇤ ”|word = ”. ⇤ g”] (2)
[pos = ”ADJ”]{2} (3)
[pos = ”ADJ”]? [pos = ”N”] (4)
Matthijs Brouwer Multi Tier Annotation Search](https://image.slidesharecdn.com/mtashennybrugman-160208154855/85/MTAS-Henny-Brugman-21-320.jpg)

![Introduction
Lucene
MTAS
Tokenizer FoLiA
Search using CQL
Results
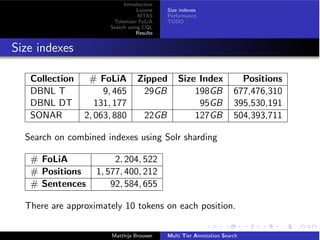
Size indexes
Performance
TODO
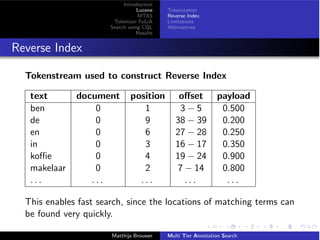
Performance
Virtual Machine, Ubuntu, 8 cores, 48GB (40GB Solr)
Computing stats (sum, mean, median, standarddeviation, etc.) on
full set of 2, 204, 522 documents and 1, 577, 400, 212 positions.
CQL Time Hits Docs
[t = ”de”] 3, 023 ms 57, 531, 353 1, 801, 583
[t = ”de” & pos = ”LID”] 7, 877 ms 56, 704, 921 1, 799, 499
[t = ”de” & !pos = ”LID”] 3, 105 ms 826, 432 132, 722
< s > [t = ”De”] 11, 568 ms 6, 085, 643 1, 090, 127
[pos = ”N”] 6, 200 ms 259, 942, 340 2, 189, 750
[pos = ”ADJ”] [pos = ”N”] 42, 977 ms 45, 366, 603 1, 821, 716
[pos = ”ADJ”]? [pos = ”N”] 207, 795 ms 305, 308, 943 2, 189, 750
Matthijs Brouwer Multi Tier Annotation Search](https://image.slidesharecdn.com/mtashennybrugman-160208154855/85/MTAS-Henny-Brugman-24-320.jpg)

This document describes Multi Tier Annotation Search (MTAS), a system built on Apache Solr that allows searching across text and multiple layers of linguistic annotations. MTAS extends Solr's indexing and querying capabilities to handle annotated text by using prefixes to distinguish annotation types, payloads to encode additional information, and forward indexes to retrieve related tokens. A FoLiA tokenizer maps the annotated text to MTAS' extended index structure, and queries can be written in Corpus Query Language (CQL) through specialized query handlers.


















































































