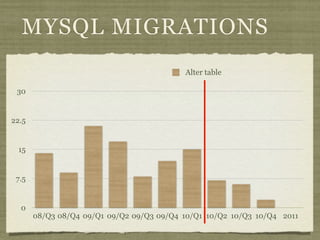
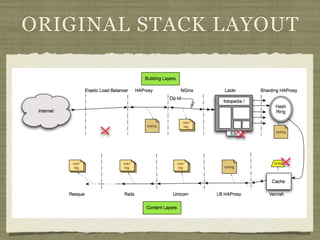
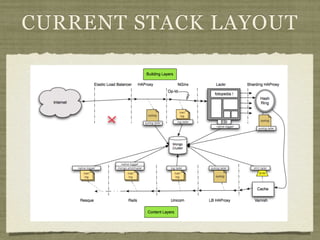
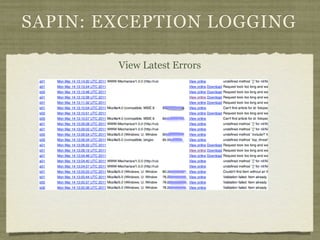
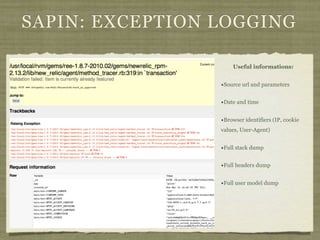
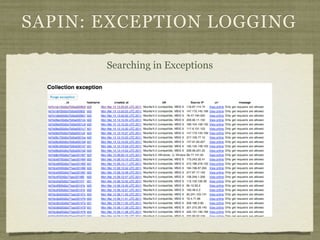
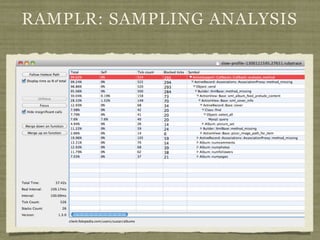
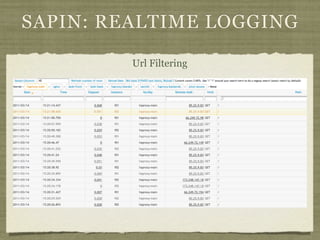
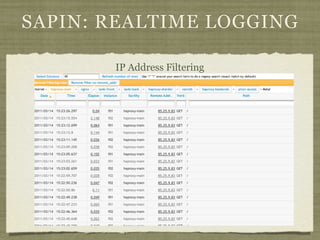
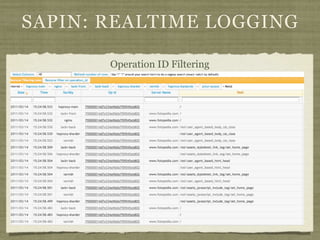
Fotopedia, a company founded in 2006, has been utilizing MongoDB for its logging infrastructure, allowing them to handle significant amounts of data efficiently. They maintain a comprehensive log collection system that utilizes various technologies and aims to improve real-time issue analysis and debugging. Future work includes optimizing their logging interface and extending the retention of log data while transitioning away from capped collections.



















































![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)









![[C5]deview 2012 nodejs](https://cdn.slidesharecdn.com/ss_thumbnails/c5deview2012nodejs-120920013859-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








![[110730/아꿈사발표자료] mongo db 완벽 가이드 : 7장 '고급기능'](https://cdn.slidesharecdn.com/ss_thumbnails/110730mongodb7-110729214130-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)












































