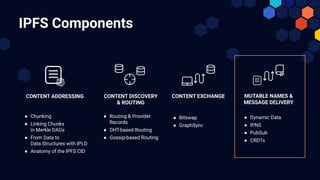
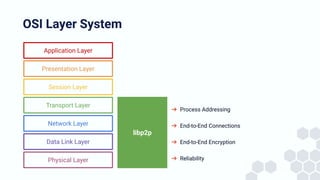
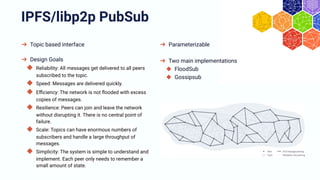
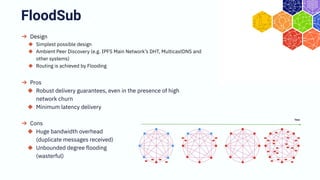
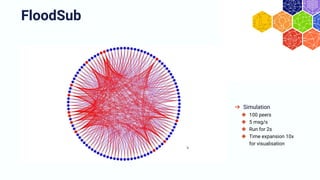
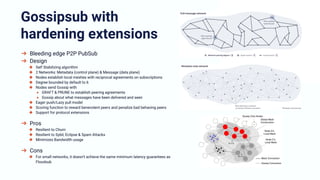
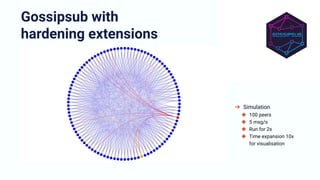
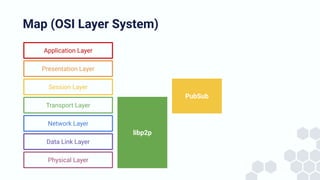
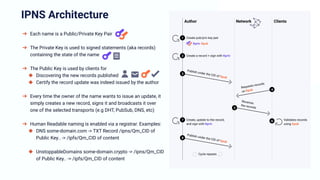
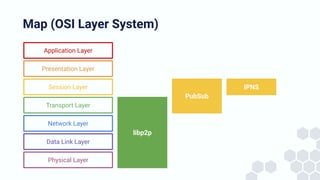
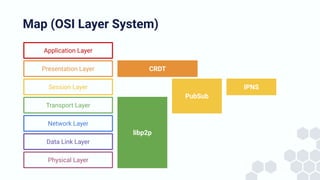
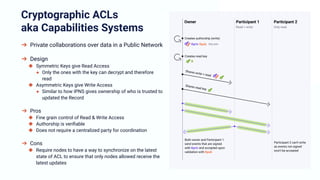
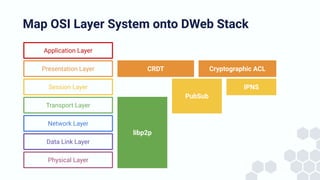
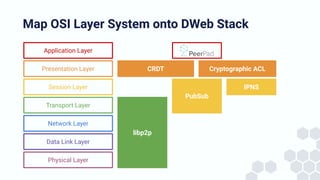
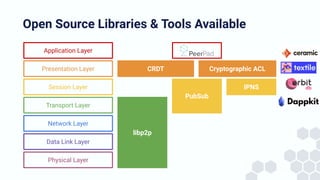
The document discusses the architecture and components of mutable content in decentralized applications, particularly focusing on IPFS and libp2p systems. It covers various aspects such as messaging layers, mutable pointers, access controls, and the role of conflict-free replicated data types (CRDTs) in managing distributed data. Additionally, it highlights challenges related to decentralized updates, network scalability, and the need for a robust system to handle varied interaction patterns and data governance.