Download to read offline




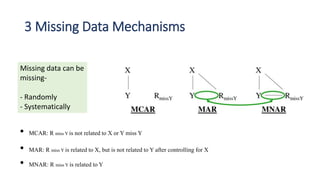










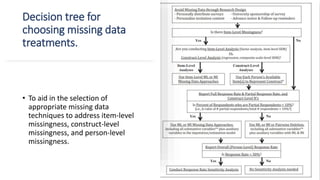


- The document provides 5 guidelines for handling missing data at different levels: item-level, construct-level, and person-level missingness. It recommends using all available data and avoiding single imputation techniques that can produce biased results. For item-level missingness, it suggests using the mean of available items rather than listwise deletion. For construct-level missingness above 10%, it recommends multiple imputation or maximum likelihood. For low response rates below 30%, it advises reporting systematic nonresponse and conducting sensitivity analyses. The document offers a decision tree to help select appropriate missing data techniques.















































