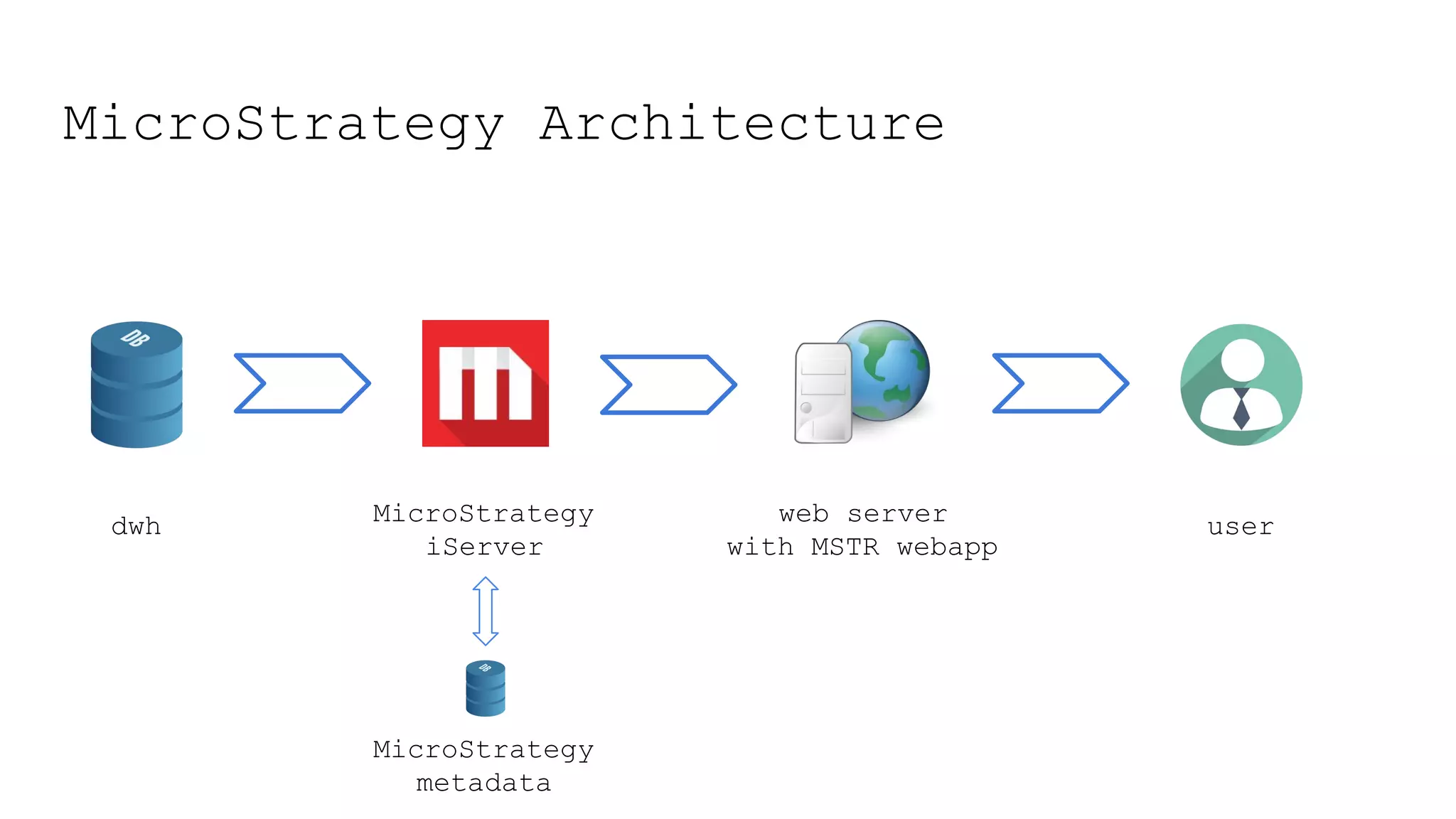
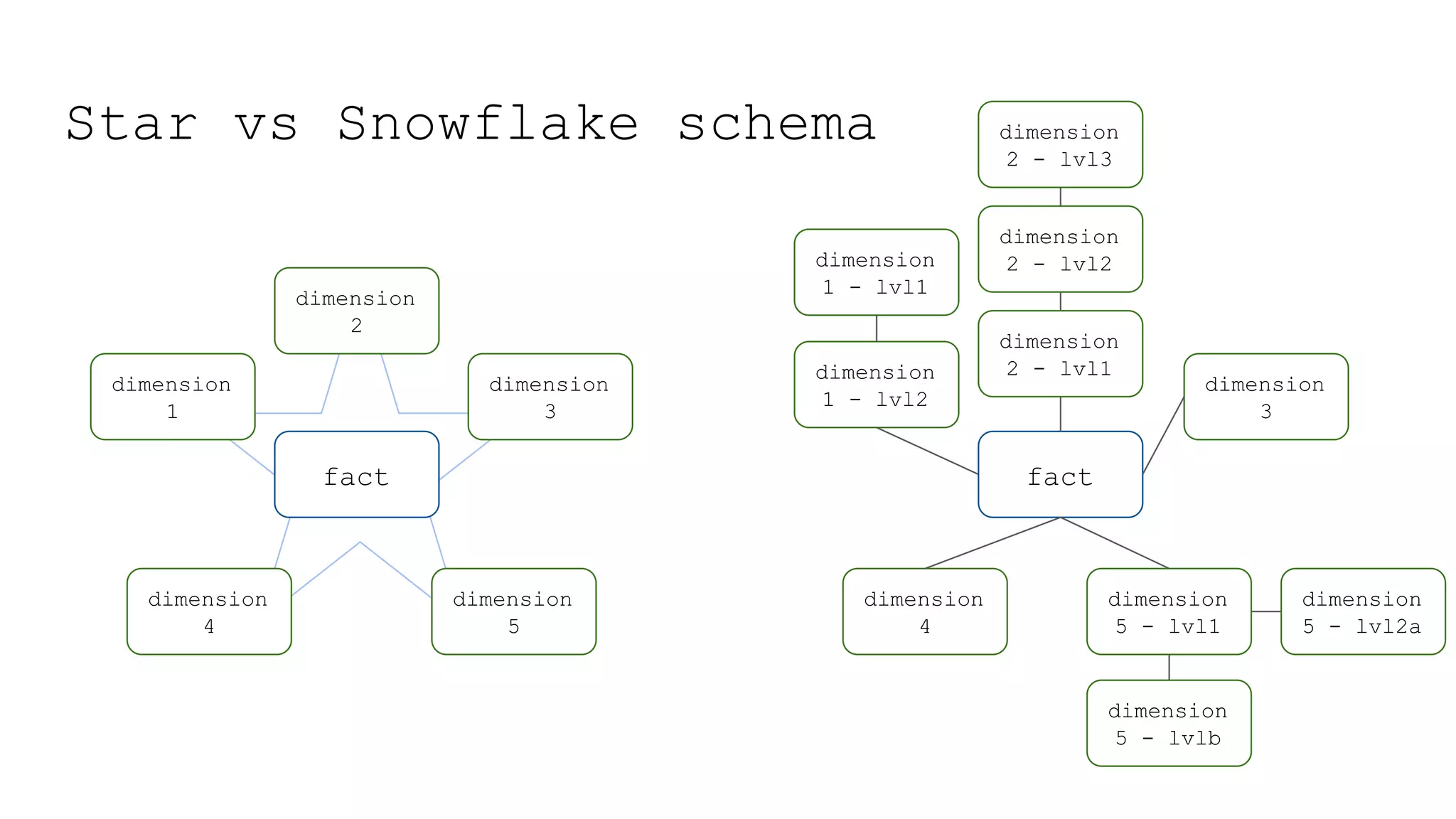
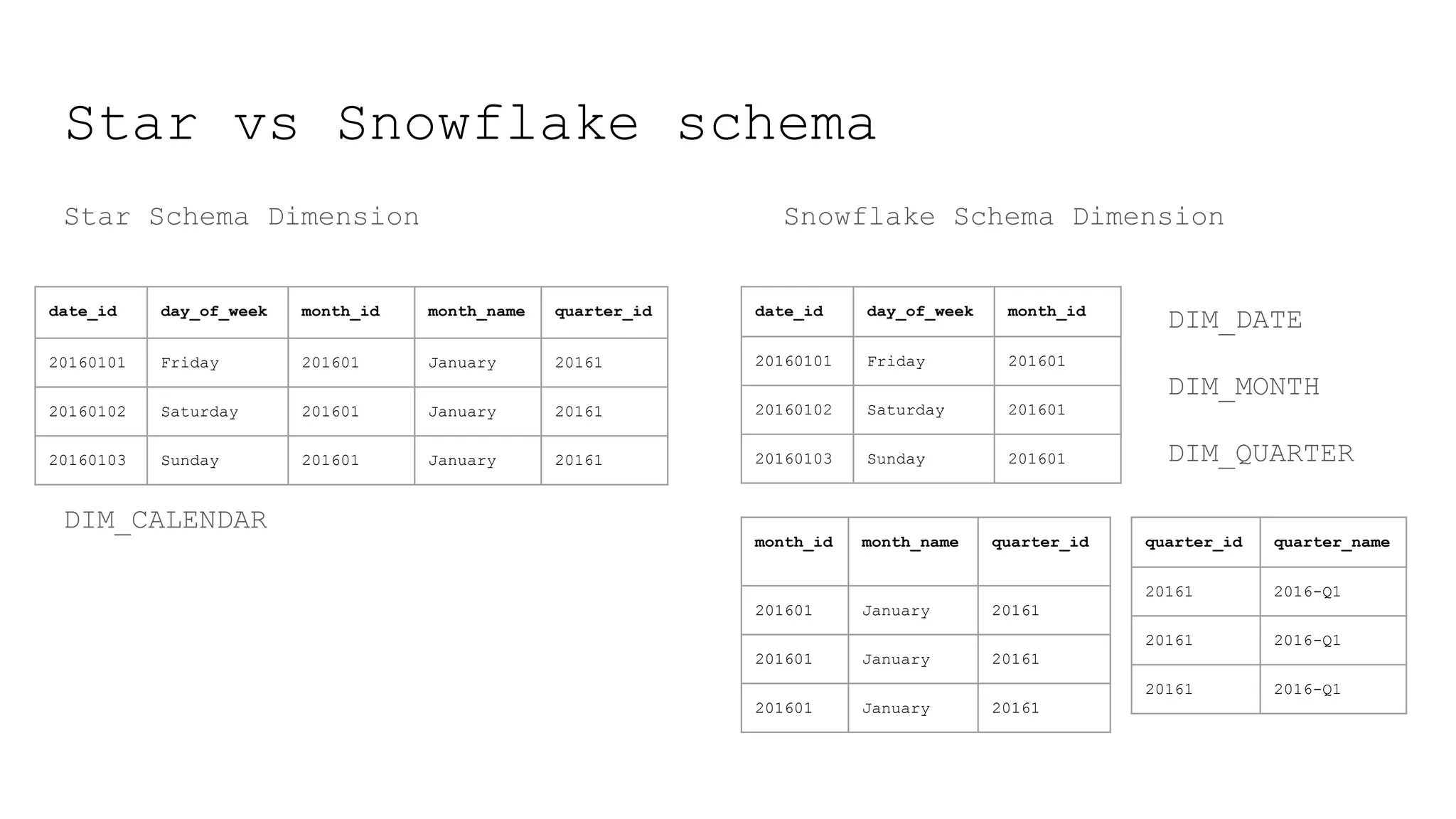
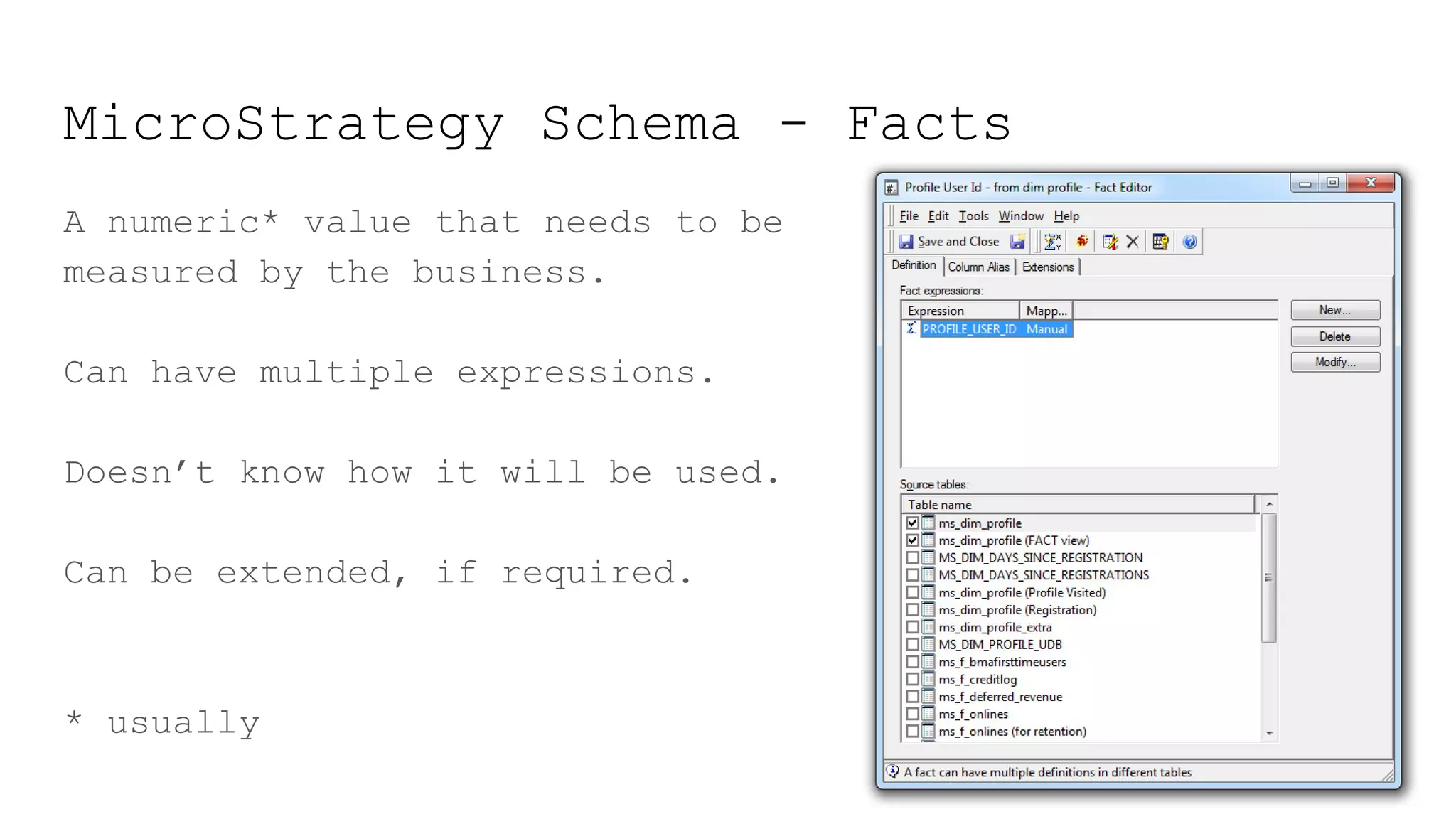
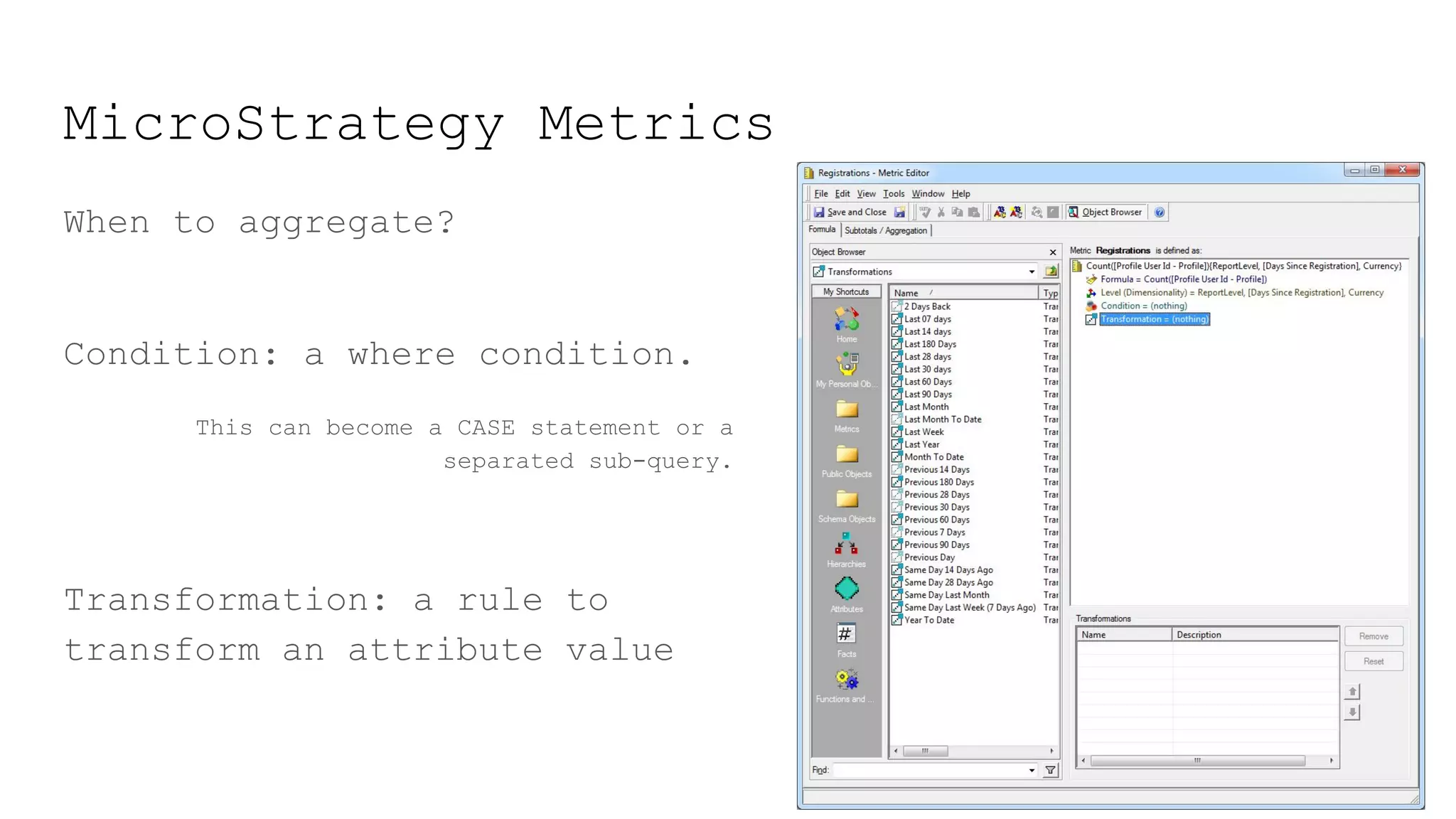
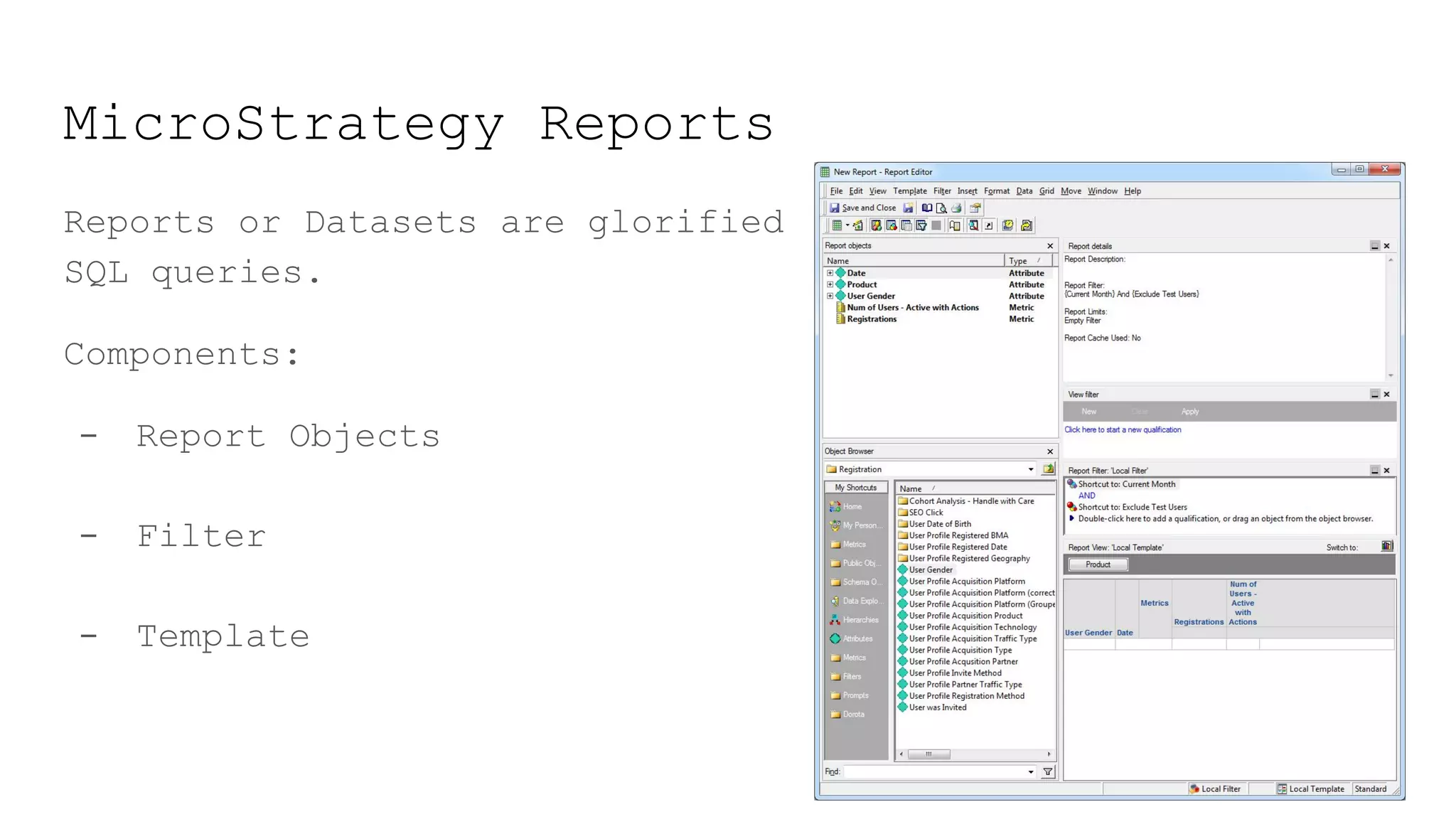
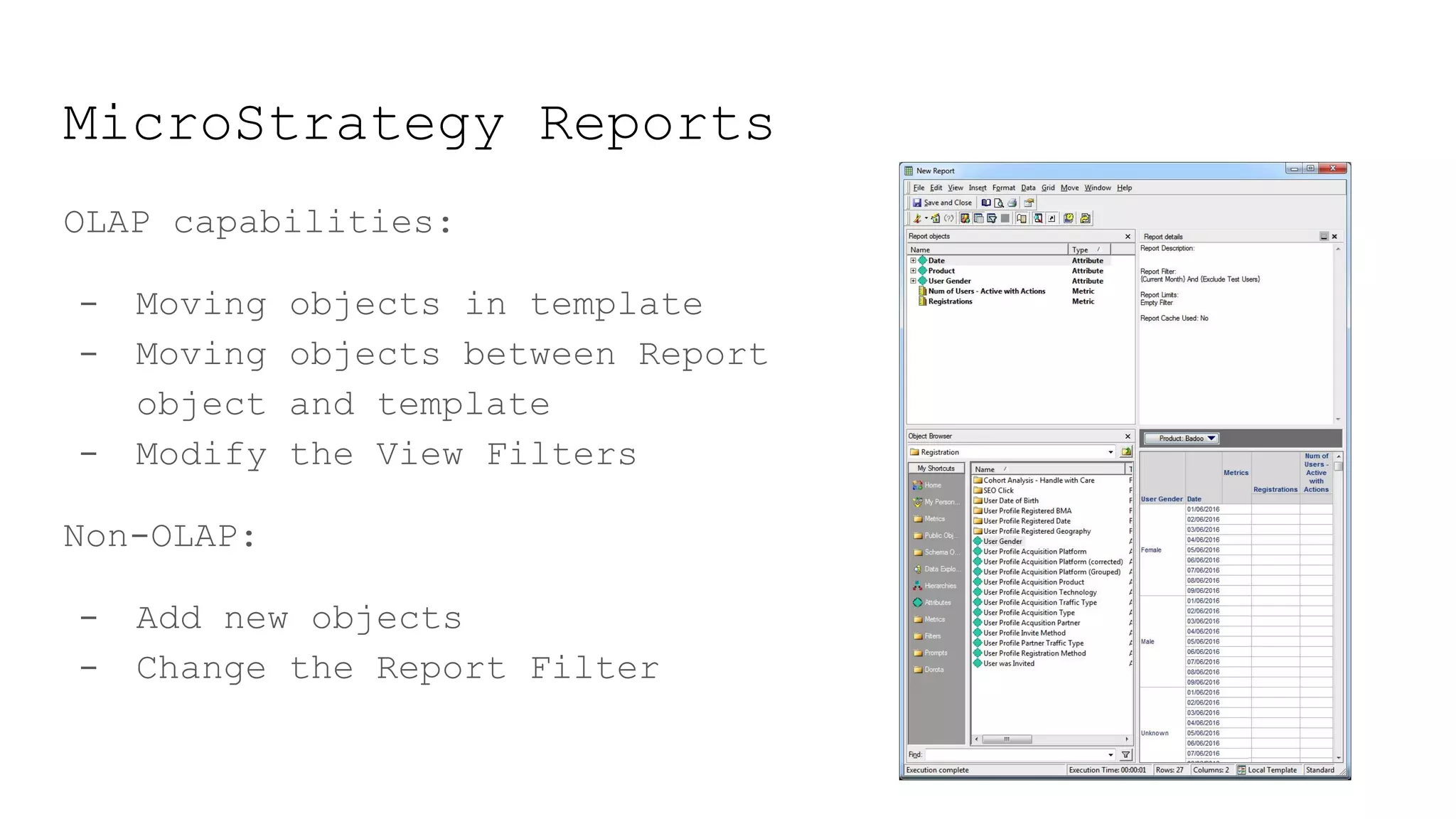
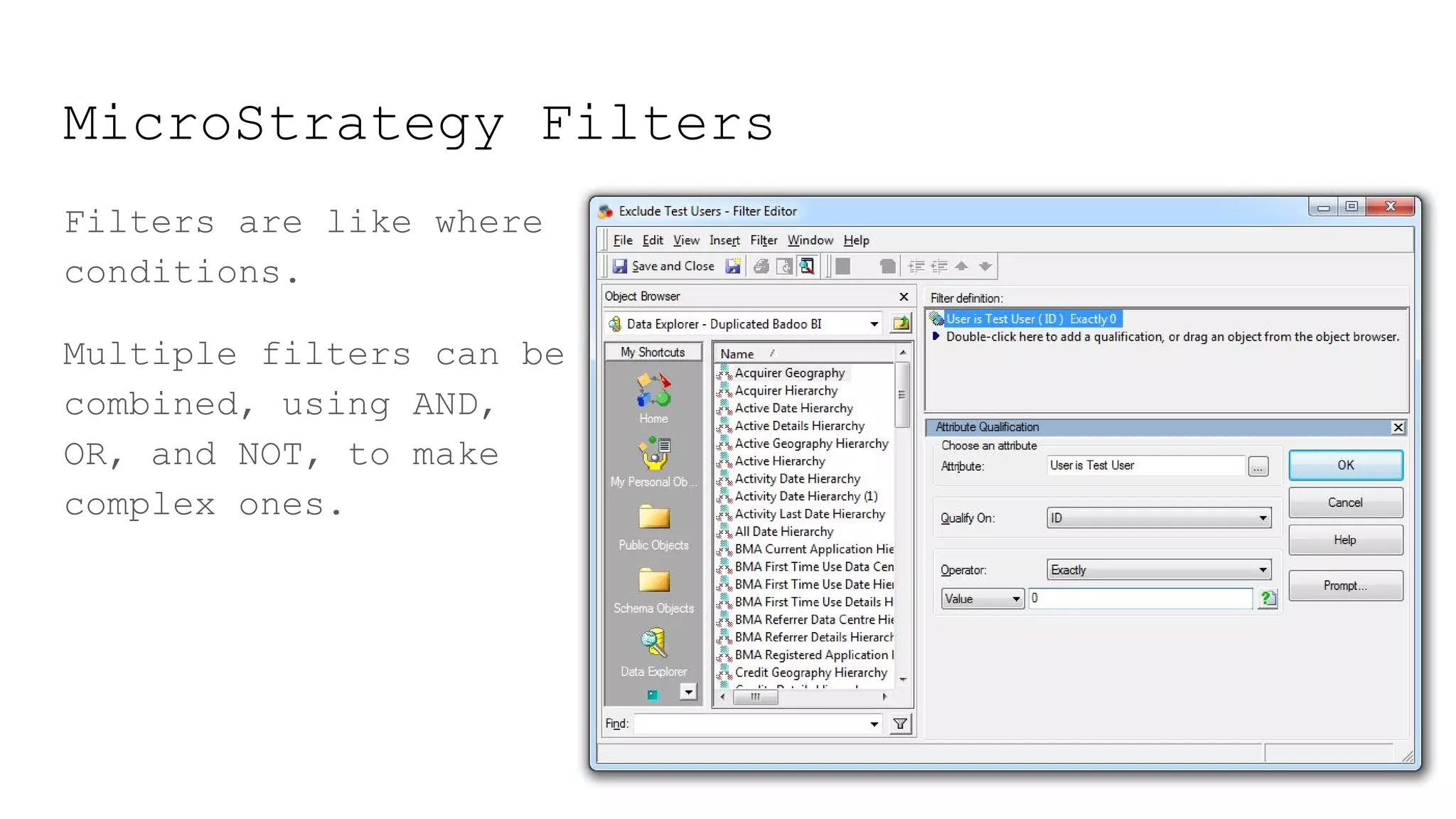
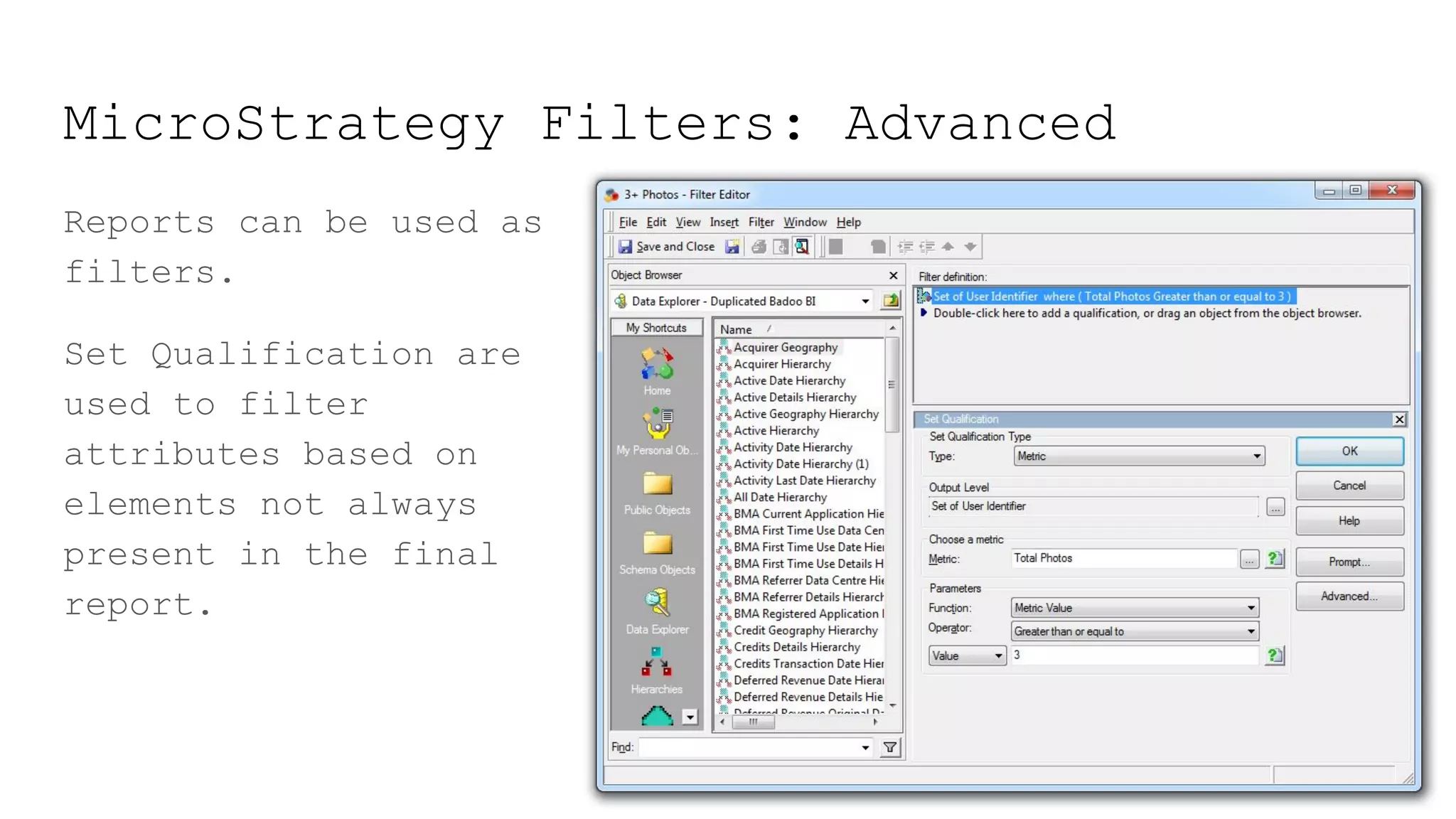
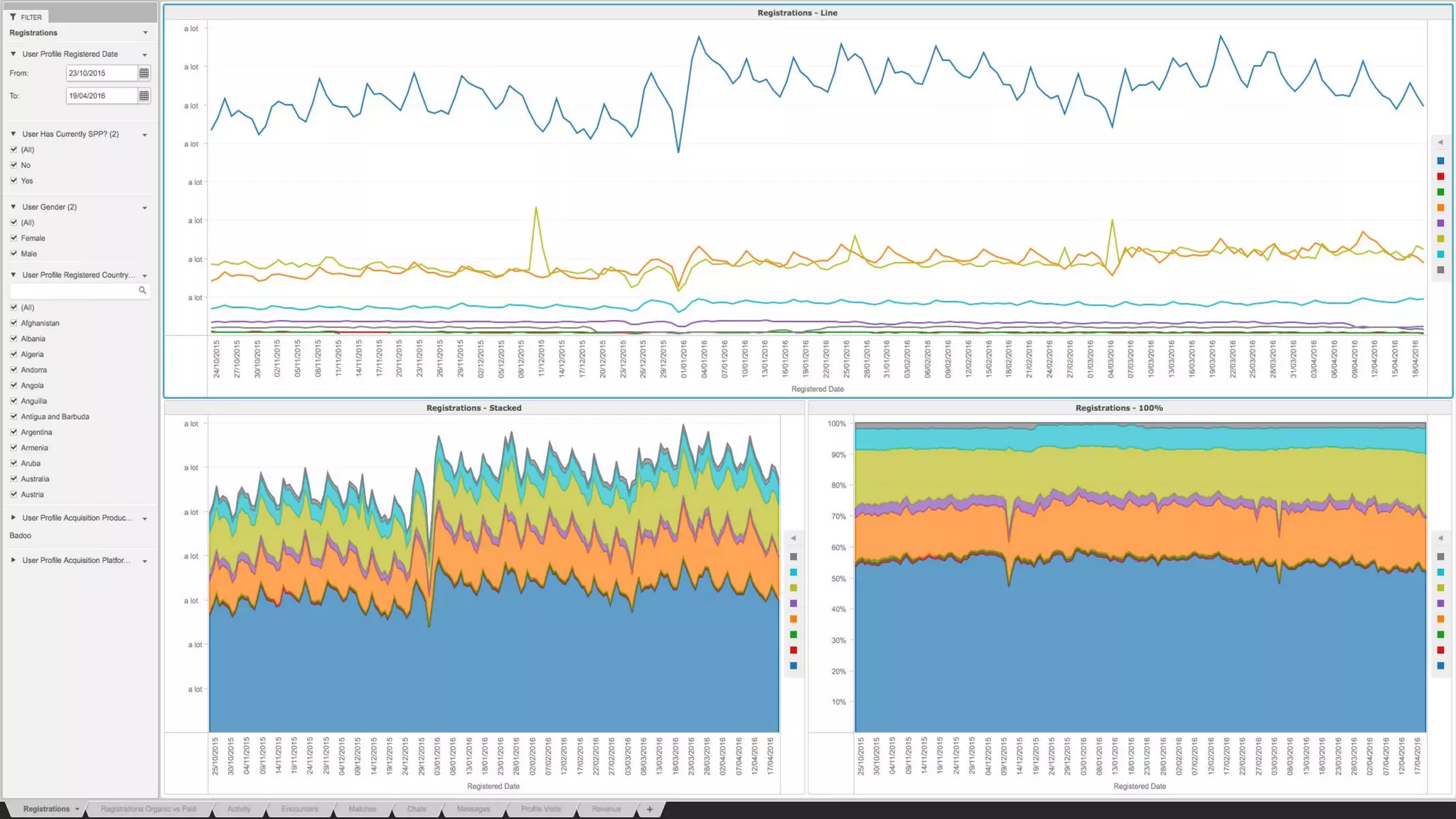
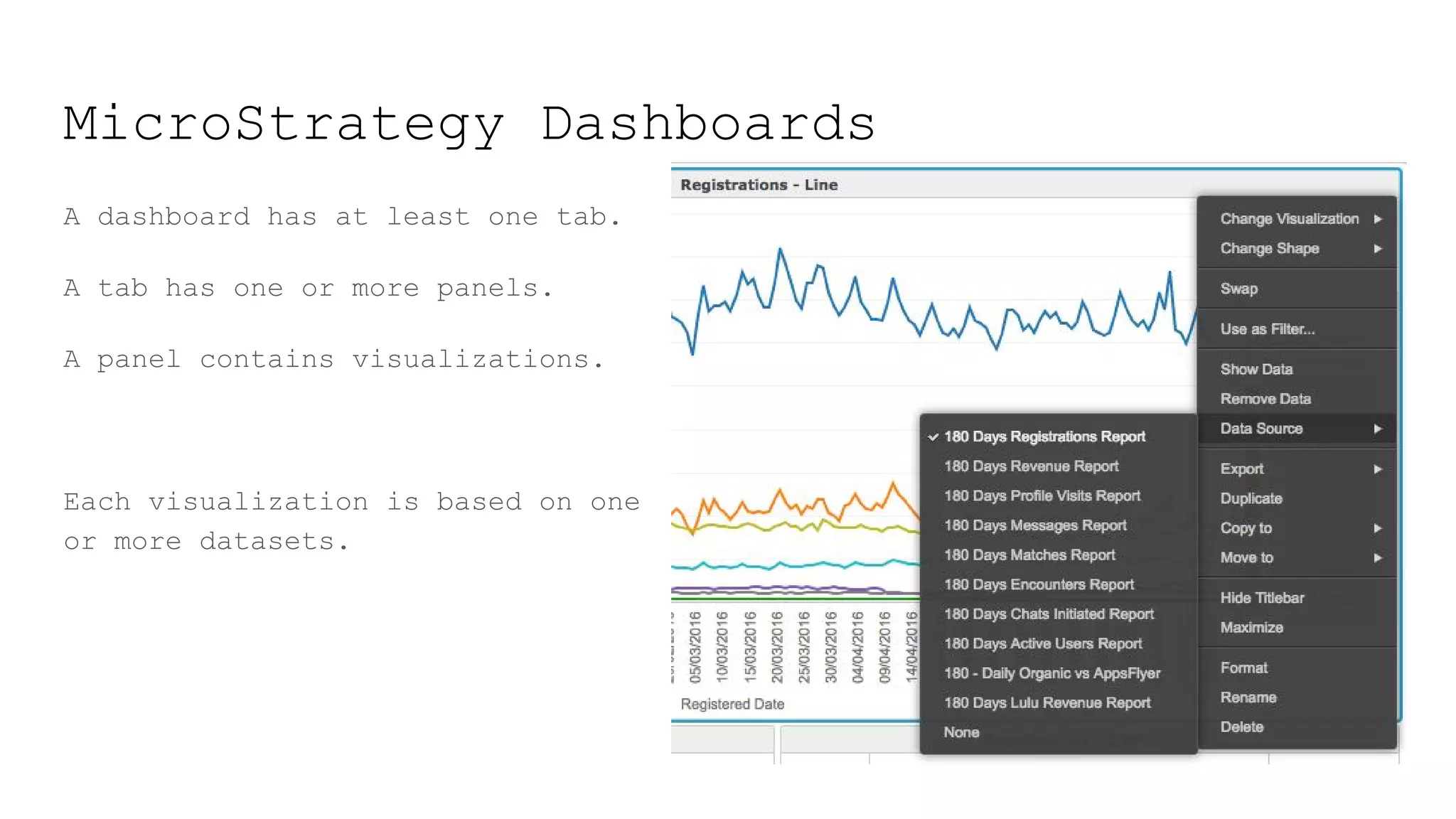
This document provides a summary of MicroStrategy, a business intelligence reporting tool. It discusses MicroStrategy's architecture, including its use of a dimensional data model and common table expressions in generated SQL. It also summarizes MicroStrategy objects like tables, attributes, metrics, reports, filters, intelligent cubes, and dashboards. Debugging tips are provided for interpreting MicroStrategy's generated SQL.















![MicroStrategy Debugging
A simple report sql .
[originally here there was a link to a SQL report were I was discussing the
different sections, results and how to interpreter the SQL, with common
table expressions, generated by MicroStrategy]](https://image.slidesharecdn.com/a28f4068-8a13-4088-aca4-25e3af2cc8b2-160616120538/75/Microstrategy-for-Data-Engineers-31-2048.jpg)















































