Downloaded 15 times




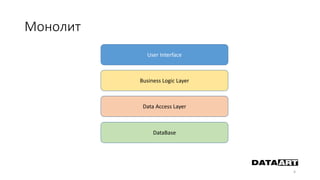
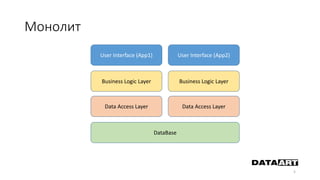





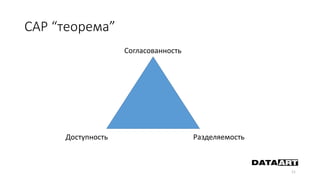






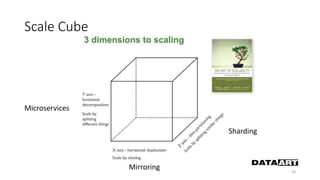

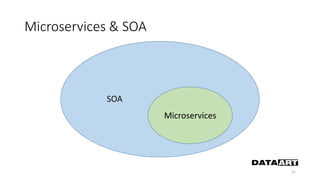







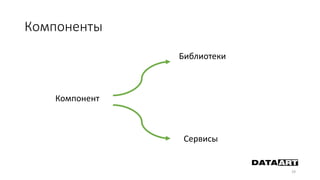
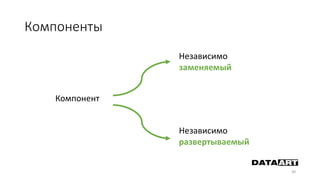

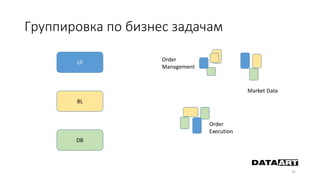

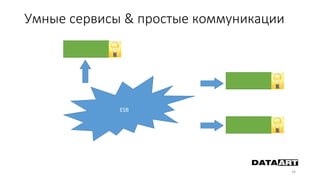
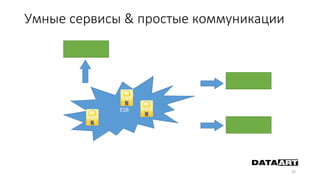

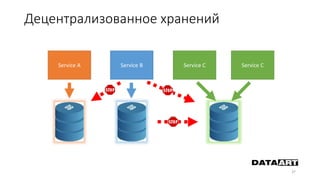
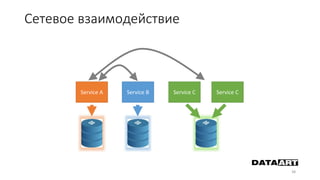



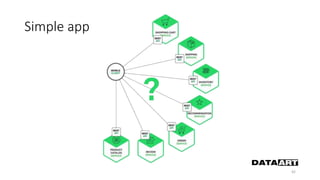
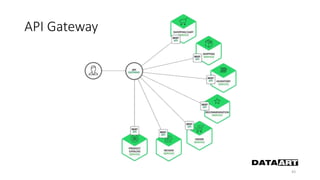

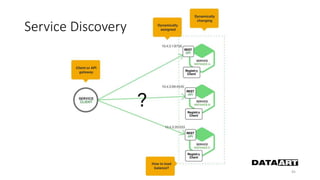
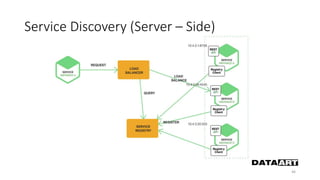
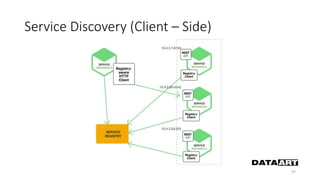


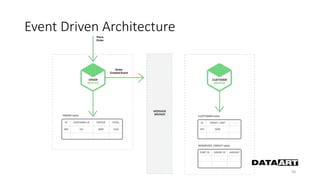
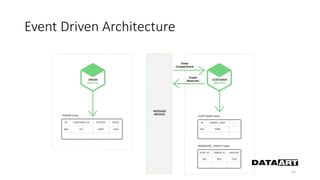
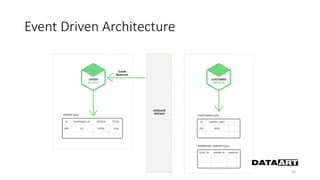



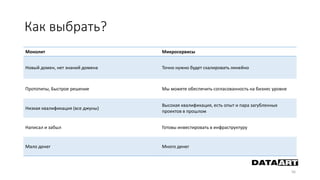





Доклад посвящен микросервисам, их преимуществам и недостаткам, а также сравнению с монолитными архитектурами. Рассматриваются основные характеристики микросервисов, принципы их взаимодействия и архитектурные подходы, такие как SOA и event-driven architecture. Дается рекомендация по выбору между монолитом и микросервисами в зависимости от бизнес-контекста и командной структуры.

































































