Downloaded 11 times




















![Analyzing Coupling I
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Email Component
[Component: C#]
Sends emails](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-23-320.jpg)
![Analyzing Coupling I
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Email Component
[Component: C#]
Sends emails
Operational: Strong. SMTP is synchronous, connection-oriented, conversational](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-24-320.jpg)
![Analyzing Coupling I
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Email Component
[Component: C#]
Sends emails
Operational: Strong. SMTP is synchronous, connection-oriented, conversational
Development: Weak. SMTP is well-defined standard with history of interoperability](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-25-320.jpg)
![Analyzing Coupling I
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Email Component
[Component: C#]
Sends emails
Operational: Strong. SMTP is synchronous, connection-oriented, conversational
Development: Weak. SMTP is well-defined standard with history of interoperability
Semantic: Very strong. SMTP defines entities, attributes, and allowed values.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-26-320.jpg)
![Analyzing Coupling I
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Email Component
[Component: C#]
Sends emails
Operational: Strong. SMTP is synchronous, connection-oriented, conversational
Development: Weak. SMTP is well-defined standard with history of interoperability
Semantic: Very strong. SMTP defines entities, attributes, and allowed values.
Functional: Very weak. Sender and MTA both use network connections.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-27-320.jpg)

![Analyzing Coupling II-A
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
SQL connection
to RDBMS](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-29-320.jpg)
![Analyzing Coupling II-A
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
SQL connection
to RDBMS
Operational: Very strong. Dependent on availability of server. Must be aware of topology and failover strategy](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-30-320.jpg)
![Analyzing Coupling II-A
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
SQL connection
to RDBMS
Operational: Very strong. Dependent on availability of server. Must be aware of topology and failover strategy
Development: Very strong. Dependent on schema, server version, protocol version.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-31-320.jpg)
![Analyzing Coupling II-A
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
SQL connection
to RDBMS
Operational: Very strong. Dependent on availability of server. Must be aware of topology and failover strategy
Development: Very strong. Dependent on schema, server version, protocol version.
Semantic: Very strong. Tables, columns, and joins must be known to both parties.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-32-320.jpg)
![Analyzing Coupling II-A
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Operational: Very strong. Dependent on availability of server. Must be aware of topology and failover strategy
Development: Very strong. Dependent on schema, server version, protocol version.
Semantic: Very strong. Tables, columns, and joins must be known to both parties.
Functional: Weak. Functions of data maintenance don’t overlap with retrieval into objects.
SQL connection
to RDBMS](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-33-320.jpg)

![Analyzing Coupling II-B
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
HTTPS request
to REST API](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-35-320.jpg)
![Analyzing Coupling II-B
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Operational: Strong, but less than before. Dependent on availability of server.
HTTPS request
to REST API](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-36-320.jpg)
![Analyzing Coupling II-B
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Operational: Strong, but less than before. Dependent on availability of server.
Development: Strong, but less. Insulated from data format changes. Open encoding can further reduce coupling
HTTPS request
to REST API](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-37-320.jpg)
![Analyzing Coupling II-B
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Operational: Strong, but less than before. Dependent on availability of server.
Development: Strong, but less. Insulated from data format changes. Open encoding can further reduce coupling
Semantic: Still very strong. REST resources and C# entities must align. Concepts will still map 1:1
HTTPS request
to REST API](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-38-320.jpg)
![Analyzing Coupling II-B
Reference Data System
[Software System]
Managesreference data for all
counterpartiesthe bank interacts
with
Getscounterparty
datafrom
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Operational: Strong, but less than before. Dependent on availability of server.
Development: Strong, but less. Insulated from data format changes. Open encoding can further reduce coupling
Semantic: Still very strong. REST resources and C# entities must align. Concepts will still map 1:1
Functional: Still weak. Different languages, techniques, design patterns apply.
HTTPS request
to REST API](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-39-320.jpg)

![Analyzing Coupling II-C
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Reference Data Receiver
[Component: C#]
Accepts and caches data from the
reference datasystem
Broadcasts
Message Broker
[Software System]
Pub/sub hub, bub
Broadcasts](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-41-320.jpg)
![Analyzing Coupling II-C
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Reference Data Receiver
[Component: C#]
Accepts and caches data from the
reference datasystem
Broadcasts
Message Broker
[Software System]
Pub/sub hub, bub
Broadcasts
Operational: Very weak. Receiver can run with stale data when either broker or upstream are broken.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-42-320.jpg)
![Analyzing Coupling II-C
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Reference Data Receiver
[Component: C#]
Accepts and caches data from the
reference datasystem
Broadcasts
Message Broker
[Software System]
Pub/sub hub, bub
Broadcasts
Operational: Very weak. Receiver can run with stale data when either broker or upstream are broken.
Development: Weak. Insulated from schema changes.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-43-320.jpg)
![Analyzing Coupling II-C
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Reference Data Receiver
[Component: C#]
Accepts and caches data from the
reference datasystem
Broadcasts
Message Broker
[Software System]
Pub/sub hub, bub
Broadcasts
Operational: Very weak. Receiver can run with stale data when either broker or upstream are broken.
Development: Weak. Insulated from schema changes.
Semantic: Strong, but not as strong. Broker allows for remapping concepts.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-44-320.jpg)
![Analyzing Coupling II-C
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Reference Data Receiver
[Component: C#]
Accepts and caches data from the
reference datasystem
Broadcasts
Message Broker
[Software System]
Pub/sub hub, bub
Broadcasts
Operational: Very weak. Receiver can run with stale data when either broker or upstream are broken.
Development: Weak. Insulated from schema changes.
Semantic: Strong, but not as strong. Broker allows for remapping concepts.
Functional: Moderate. All components must share the same messaging tech.](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-45-320.jpg)



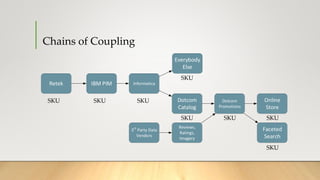
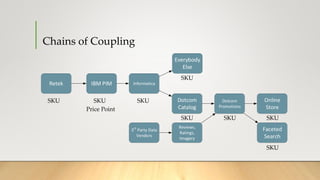
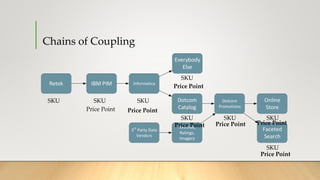
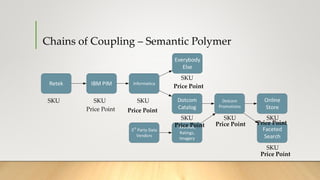














![Batch Process
File System
[Container: Network File Share]
Stores risk reports
Report Distributor
[Component: C#]
Publishes the report for the web
application
Publishesrisk reportsto
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Central Monitoring Service
[Software System]
The bank-wide monitoringand
alertingdashboard
Trade Data System
[Software System]
The system of record for trades of
type X
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Getstrade datafrom
Sendscritical failure alertsto
[SNMP]
Getscounterparty
datafrom
Email Component
[Component: C#]
Sends emails
Trade Data Importer
[Component: C#]
Imports data from the trade data
system
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Report Checker
[Component: C#]
Checks that the report has been
generated by 9 a.m. Singapore
time
Alerter
[Component: C# with SNMP
library]
Sends SNMPalerts
Sendsalerts using
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Sendsemail
using
Importsdata
using
Importsdata
using
Risk Calculator
[Component: C#]
Does math
Report Generator
[Component: C# and
Microsoft.Office.Interop.Excel]
Generates an Excel compatible
risk report
Generatesthe risk
report using
Calculatesrisk
using
Scheduler
[Component: Quartz.net]
Starts the risk calculation process
at 5 p.m. New York time
Starts
Starts
Publishesthe risk
report using](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-70-320.jpg)
![Batch Process
File System
[Container: Network File Share]
Stores risk reports
Report Distributor
[Component: C#]
Publishes the report for the web
application
Publishesrisk reportsto
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Central Monitoring Service
[Software System]
The bank-wide monitoringand
alertingdashboard
Trade Data System
[Software System]
The system of record for trades of
type X
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Getstrade datafrom
Sendscritical failure alertsto
[SNMP]
Getscounterparty
datafrom
Email Component
[Component: C#]
Sends emails
Trade Data Importer
[Component: C#]
Imports data from the trade data
system
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Report Checker
[Component: C#]
Checks that the report has been
generated by 9 a.m. Singapore
time
Alerter
[Component: C# with SNMP
library]
Sends SNMPalerts
Sendsalerts using
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Sendsemail
using
Importsdata
using
Importsdata
using
Risk Calculator
[Component: C#]
Does math
Report Generator
[Component: C# and
Microsoft.Office.Interop.Excel]
Generates an Excel compatible
risk report
Generatesthe risk
report using
Calculatesrisk
using
Scheduler
[Component: Quartz.net]
Starts the risk calculation process
at 5 p.m. New York time
Starts
Starts
Publishesthe risk
report using
Risk calculator produces a data structure that the
report generator must consume.
Example from c4model.com](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-71-320.jpg)
![Batch Process
File System
[Container: Network File Share]
Stores risk reports
Report Distributor
[Component: C#]
Publishes the report for the web
application
Publishesrisk reportsto
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Central Monitoring Service
[Software System]
The bank-wide monitoringand
alertingdashboard
Trade Data System
[Software System]
The system of record for trades of
type X
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Getstrade datafrom
Sendscritical failure alertsto
[SNMP]
Getscounterparty
datafrom
Email Component
[Component: C#]
Sends emails
Trade Data Importer
[Component: C#]
Imports data from the trade data
system
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Report Checker
[Component: C#]
Checks that the report has been
generated by 9 a.m. Singapore
time
Alerter
[Component: C# with SNMP
library]
Sends SNMPalerts
Sendsalerts using
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Sendsemail
using
Importsdata
using
Importsdata
using
Risk Calculator
[Component: C#]
Does math
Report Generator
[Component: C# and
Microsoft.Office.Interop.Excel]
Generates an Excel compatible
risk report
Generatesthe risk
report using
Calculatesrisk
using
Scheduler
[Component: Quartz.net]
Starts the risk calculation process
at 5 p.m. New York time
Starts
Starts
Publishesthe risk
report using
Risk calculator produces a data structure that the
report generator must consume.
Data importers probably have similar
implementation needs
Example from c4model.com](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-72-320.jpg)
![Batch Process
File System
[Container: Network File Share]
Stores risk reports
Report Distributor
[Component: C#]
Publishes the report for the web
application
Publishesrisk reportsto
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Central Monitoring Service
[Software System]
The bank-wide monitoringand
alertingdashboard
Trade Data System
[Software System]
The system of record for trades of
type X
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Getstrade datafrom
Sendscritical failure alertsto
[SNMP]
Getscounterparty
datafrom
Email Component
[Component: C#]
Sends emails
Trade Data Importer
[Component: C#]
Imports data from the trade data
system
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Report Checker
[Component: C#]
Checks that the report has been
generated by 9 a.m. Singapore
time
Alerter
[Component: C# with SNMP
library]
Sends SNMPalerts
Sendsalerts using
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Sendsemail
using
Importsdata
using
Importsdata
using
Risk Calculator
[Component: C#]
Does math
Report Generator
[Component: C# and
Microsoft.Office.Interop.Excel]
Generates an Excel compatible
risk report
Generatesthe risk
report using
Calculatesrisk
using
Scheduler
[Component: Quartz.net]
Starts the risk calculation process
at 5 p.m. New York time
Starts
Starts
Publishesthe risk
report using
Risk calculator produces a data structure that the
report generator must consume.
Data importers probably have similar
implementation needs
Report checker doesn’t appear to connect with
the file system that holds the reports. FS location
is latent coupling that will be a nasty surprise later.
Example from c4model.com](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-73-320.jpg)
![Batch Process
File System
[Container: Network File Share]
Stores risk reports
Report Distributor
[Component: C#]
Publishes the report for the web
application
Publishesrisk reportsto
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Central Monitoring Service
[Software System]
The bank-wide monitoringand
alertingdashboard
Trade Data System
[Software System]
The system of record for trades of
type X
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Getstrade datafrom
Sendscritical failure alertsto
[SNMP]
Getscounterparty
datafrom
Email Component
[Component: C#]
Sends emails
Trade Data Importer
[Component: C#]
Imports data from the trade data
system
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Report Checker
[Component: C#]
Checks that the report has been
generated by 9 a.m. Singapore
time
Alerter
[Component: C# with SNMP
library]
Sends SNMPalerts
Sendsalerts using
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Sendsemail
using
Importsdata
using
Importsdata
using
Risk Calculator
[Component: C#]
Does math
Report Generator
[Component: C# and
Microsoft.Office.Interop.Excel]
Generates an Excel compatible
risk report
Generatesthe risk
report using
Calculatesrisk
using
Scheduler
[Component: Quartz.net]
Starts the risk calculation process
at 5 p.m. New York time
Starts
Starts
Publishesthe risk
report using
Risk calculator produces a data structure that the
report generator must consume.
Data importers probably have similar
implementation needs
Report checker doesn’t appear to connect with
the file system that holds the reports. FS location
is latent coupling that will be a nasty surprise later.
Orchestrator might end need
to do lots of data
transformation to bridge
interfaces.
Example from c4model.com](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-74-320.jpg)
![Batch Process
File System
[Container: Network File Share]
Stores risk reports
Report Distributor
[Component: C#]
Publishes the report for the web
application
Publishesrisk reportsto
Reference Data System
[Software System]
Manages reference data for all
counterparties the bank interacts
with
Central Monitoring Service
[Software System]
The bank-wide monitoringand
alertingdashboard
Trade Data System
[Software System]
The system of record for trades of
type X
E-mail system
[Software System]
Microsoft Exchange
Sendsanotification that
areport isready to
Getstrade datafrom
Sendscritical failure alertsto
[SNMP]
Getscounterparty
datafrom
Email Component
[Component: C#]
Sends emails
Trade Data Importer
[Component: C#]
Imports data from the trade data
system
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Report Checker
[Component: C#]
Checks that the report has been
generated by 9 a.m. Singapore
time
Alerter
[Component: C# with SNMP
library]
Sends SNMPalerts
Sendsalerts using
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Sendsemail
using
Importsdata
using
Importsdata
using
Risk Calculator
[Component: C#]
Does math
Report Generator
[Component: C# and
Microsoft.Office.Interop.Excel]
Generates an Excel compatible
risk report
Generatesthe risk
report using
Calculatesrisk
using
Scheduler
[Component: Quartz.net]
Starts the risk calculation process
at 5 p.m. New York time
Starts
Starts
Publishesthe risk
report using
Risk calculator produces a data structure that the
report generator must consume.
Data importers probably have similar
implementation needs
Report checker doesn’t appear to connect with
the file system that holds the reports. FS location
is latent coupling that will be a nasty surprise later.
Orchestrator might end need
to do lots of data
transformation to bridge
interfaces.
Example from c4model.com](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-75-320.jpg)

![Problem: Risk calculator
produces a data structure
that the report generator
must consume.
Solutions depend on architectural style
Here we’re in a Windows service so we
might use a shared library to define the interface.
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Risk Calculator
[Component: C#]
Does math
Report Generator
[Component: C# and
Microsoft.Office.Interop.Excel]
Generates an Excel compatible
risk report
Generatesthe risk
report using
Calculatesrisk
using](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-77-320.jpg)
![Problem: Redundant implementation details
This would be a good place to use a
shared library for common implementation.
Trade Data Importer
[Component: C#]
Imports data from the trade data
system
Reference Data Importer
[Component: C#]
Imports data from the reference
datasystem
Orchestrator
[Component: C#]
Orchestrates the risk calculation
process
Importsdata
using
Importsdata
using](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-78-320.jpg)
![File System
[Container: Network File Share]
Stores risk reports
Report Distributor
[Component: C#]
Publishes the report for the web
application
Publishesrisk reportsto
Report Checker
[Component: C#]
Checks that the report has been
generated by 9 a.m. Singapore
time
Alerter
[Component: C# with SNMP
library]
Sends SNMPalerts
Sendsalerts using
Scheduler
[Component: Quartz.net]
Starts
Publishesthe risk
Problem: Latent coupling about filesystem
layout.
Solution: A module to hide the decision
about filesystem layout from
both the Report Distributor and the
Report Checker](https://image.slidesharecdn.com/uncoupling-190828220739/85/Michael-Nygard-Uncoupling-79-320.jpg)







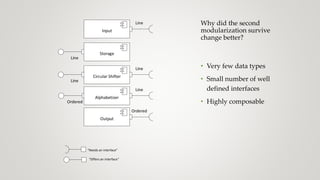
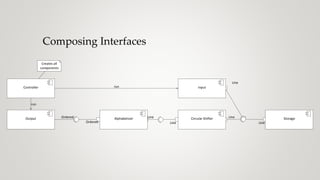
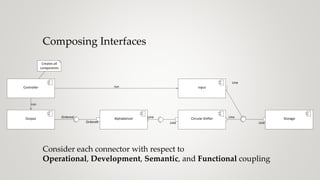
The document discusses the concept of coupling in software systems, exploring how it affects degrees of freedom and the ability to manage changes. It analyzes various examples, including email systems and reference data systems, to illustrate operational, development, semantic, and functional coupling characteristics. The importance of separating concerns and maintaining low coupling while ensuring high cohesion in module design is emphasized for better software architecture.