Downloaded 22 times




















































































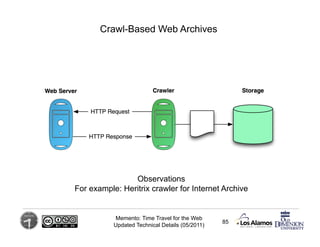























































The Memento framework provides a protocol for integrating past and present web resources, allowing users to access archived versions of web content easily. This framework uses a uniform approach to manage various versions of resources, leveraging existing web infrastructure like archives and content management systems. By introducing HTTP headers like 'accept-datetime' and 'memento-datetime', Memento facilitates time travel for web pages, enabling discovery and retrieval of historical content.





















































