Download to read offline
![@bagder
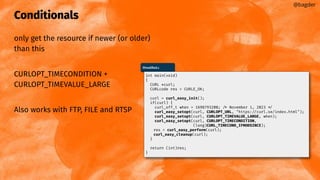
/* set the options (I left out a few, you will get the point anyway) */
curl_easy_setopt(handles[HTTP_HANDLE], CURLOPT_URL, "https://example.com");
curl_easy_setopt(handles[FTP_HANDLE], CURLOPT_URL, "ftp://example.com");
curl_easy_setopt(handles[FTP_HANDLE], CURLOPT_UPLOAD, 1L);
/* init a multi stack */
multi_handle = curl_multi_init();
/* add the individual transfers */
for(i = 0; i<HANDLECOUNT; i++)
curl_multi_add_handle(multi_handle, handles[i]);
while(still_running) {
CURLMcode mc = curl_multi_perform(multi_handle, &still_running);
if(still_running)
/* wait for activity, timeout or "nothing" */
mc = curl_multi_poll(multi_handle, NULL, 0, 1000, NULL);
if(mc)
break;
}
/* See how the transfers went */
while((msg = curl_multi_info_read(multi_handle, &msgs_left))) {
if(msg->msg == CURLMSG_DONE) {
int idx;
/* Find out which handle this message is about */
for(idx = 0; idx<HANDLECOUNT; idx++) {
int found = (msg->easy_handle == handles[idx]);
if(found)
break;
}
switch(idx) {
case HTTP_HANDLE:
printf("HTTP transfer completed with status %dn", msg->data.result);
break;
case FTP_HANDLE:
printf("FTP transfer completed with status %dn", msg->data.result);
break;
}
}
}
/* remove the transfers and cleanup the handles */
for(i = 0; i<HANDLECOUNT; i++) {
curl_multi_remove_handle(multi_handle, handles[i]);
curl_easy_cleanup(handles[i]);
}
#include <stdio.h>
#include <curl/curl.h>
int main(void)
{
CURL *curl;
CURLcode res;
curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "https://example.com");
/* example.com is redirected, so we tell libcurl to follow redirection */
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L);
/* Perform the request, res will get the return code */
res = curl_easy_perform(curl);
/* Check for errors */
if(res != CURLE_OK)
fprintf(stderr, "curl_easy_perform() failed: %sn",
curl_easy_strerror(res));
/* always cleanup */
curl_easy_cleanup(curl);
}
return 0;
}
mastering libcurl
November 20, 2023 Daniel Stenberg
more libcurl source code and details in a single video than you ever saw before
part two](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-1-320.jpg)
![@bagder
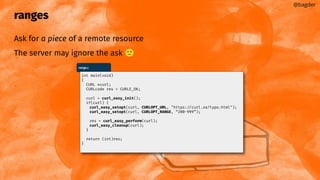
/* set the options (I left out a few, you will get the point anyway) */
curl_easy_setopt(handles[HTTP_HANDLE], CURLOPT_URL, "https://example.com");
curl_easy_setopt(handles[FTP_HANDLE], CURLOPT_URL, "ftp://example.com");
curl_easy_setopt(handles[FTP_HANDLE], CURLOPT_UPLOAD, 1L);
/* init a multi stack */
multi_handle = curl_multi_init();
/* add the individual transfers */
for(i = 0; i<HANDLECOUNT; i++)
curl_multi_add_handle(multi_handle, handles[i]);
while(still_running) {
CURLMcode mc = curl_multi_perform(multi_handle, &still_running);
if(still_running)
/* wait for activity, timeout or "nothing" */
mc = curl_multi_poll(multi_handle, NULL, 0, 1000, NULL);
if(mc)
break;
}
/* See how the transfers went */
while((msg = curl_multi_info_read(multi_handle, &msgs_left))) {
if(msg->msg == CURLMSG_DONE) {
int idx;
/* Find out which handle this message is about */
for(idx = 0; idx<HANDLECOUNT; idx++) {
int found = (msg->easy_handle == handles[idx]);
if(found)
break;
}
switch(idx) {
case HTTP_HANDLE:
printf("HTTP transfer completed with status %dn", msg->data.result);
break;
case FTP_HANDLE:
printf("FTP transfer completed with status %dn", msg->data.result);
break;
}
}
}
/* remove the transfers and cleanup the handles */
for(i = 0; i<HANDLECOUNT; i++) {
curl_multi_remove_handle(multi_handle, handles[i]);
curl_easy_cleanup(handles[i]);
}
#include <stdio.h>
#include <curl/curl.h>
int main(void)
{
CURL *curl;
CURLcode res;
curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "https://example.com");
/* example.com is redirected, so we tell libcurl to follow redirection */
curl_easy_setopt(curl, CURLOPT_FOLLOWLOCATION, 1L);
/* Perform the request, res will get the return code */
res = curl_easy_perform(curl);
/* Check for errors */
if(res != CURLE_OK)
fprintf(stderr, "curl_easy_perform() failed: %sn",
curl_easy_strerror(res));
/* always cleanup */
curl_easy_cleanup(curl);
}
return 0;
}
mastering libcurl
November 20, 2023 Daniel Stenberg
more libcurl source code and details in a single video than you ever saw before
part two](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/75/mastering-libcurl-part-2-1-2048.jpg)







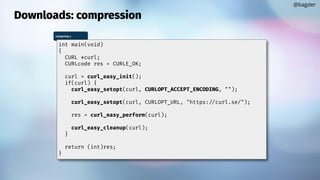
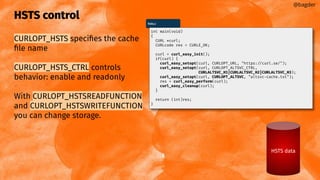
![Downloads: storing
Return a different value than number of
bytes to deal with == error
@bagder
struct memory {
char *ptr;
size_t size;
};
static size_t
write_cb(void *contents, size_t size, size_t nmemb, void *userp)
{
struct memory *mem = userp;
size_t realsize = size * nmemb;
char *ptr = realloc(mem->ptr, mem->size + realsize + 1);
if(!ptr) {
fprintf(stderr, "not enough memoryn");
return 0;
}
mem->ptr = ptr;
memcpy(&mem->ptr[mem->size], contents, realsize);
mem->size += realsize;
mem->ptr[mem->size] = 0;
return realsize;
}
write-callback.c](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-9-320.jpg)



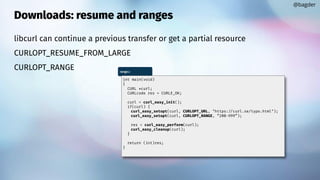

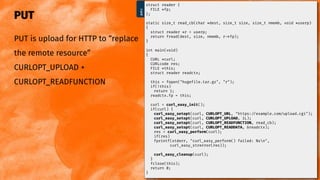
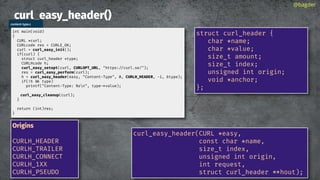
![Uploads: providing data
CURLOPT_READFUNCTION
Returning error stops transfer
@bagder
int main(void)
{
CURL *curl;
CURLcode res;
struct WriteThis wt;
wt.readptr = data;
wt.sizeleft = strlen(data);
curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, "https://curl.se");
curl_easy_setopt(curl, CURLOPT_POST, 1L);
curl_easy_setopt(curl, CURLOPT_READFUNCTION, read_cb);
curl_easy_setopt(curl, CURLOPT_READDATA, &wt);
curl_easy_setopt(curl, CURLOPT_VERBOSE, 1L);
res = curl_easy_perform(curl);
if(res)
fprintf(stderr, "curl_easy_perform() failed: %sn",
curl_easy_strerror(res));
curl_easy_cleanup(curl);
}
return 0;
}
read-callback.c
struct WriteThis {
const char *readptr;
size_t sizeleft;
};
static size_t read_cb(char *dest, size_t size, size_t nmemb,
void *userp)
{
struct WriteThis *wt = (struct WriteThis *)userp;
size_t buffer_size = size*nmemb;
if(wt->sizeleft) {
/* [some code left out] */
memcpy(dest, wt->readptr, copy_this_much);
return copy_this_much; /* we copied this many bytes */
}
return 0; /* no more data left to deliver */
}
read-callback.c](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-16-320.jpg)




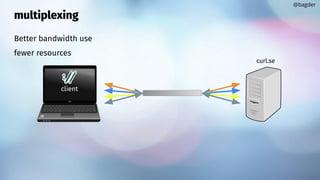
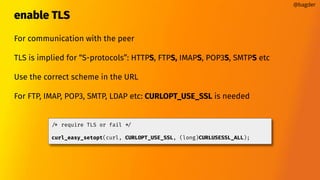
![multiplexing
HTTP/2 or HTTP/3
transfers added to a multi handle
CURLMOPT_PIPELINING
There is a max number of streams
Connections can GOAWAY
Multiplexing (or not) is done transparently
@bagder
same
[ multi handle +
HTTP(S) +
port number +
host name +
HTTP version ]
==
multiplexing possible](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-22-320.jpg)



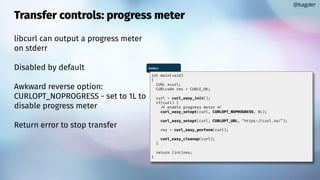
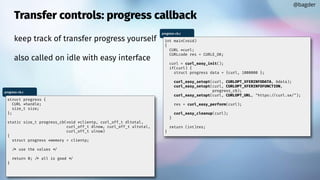
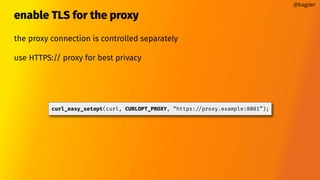
![Timeouts
By default, libcurl typically has no or very liberal timeouts
You might want to narrow things down
CURLOPT_TIMEOUT[_MS]
CURLOPT_CONNECTTIMEOUT[_MS]
Make your own with the progress callback
@bagder](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-28-320.jpg)
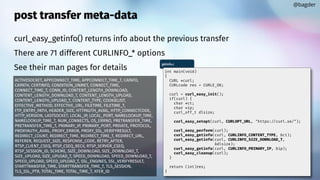


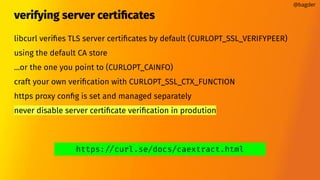
![convert curl command lines to libcurl source code embryos
excellent initial get-started step
--libcurl
@bagder
$ curl -H "foo: bar" https://curl.se/ libcurl dashdash.c
[lots of HTML output]
dashdash.c
int main(int argc, char *argv[])
{
CURLcode ret;
CURL *hnd;
struct curl_slist *slist1;
slist1 = NULL;
slist1 = curl_slist_append(slist1, "foo: bar");
hnd = curl_easy_init();
curl_easy_setopt(hnd, CURLOPT_BUFFERSIZE, 102400L);
curl_easy_setopt(hnd, CURLOPT_URL, "https://curl.se/");
curl_easy_setopt(hnd, CURLOPT_NOPROGRESS, 1L);
curl_easy_setopt(hnd, CURLOPT_HTTPHEADER, slist1);
curl_easy_setopt(hnd, CURLOPT_USERAGENT, "curl/8.4.0");
curl_easy_setopt(hnd, CURLOPT_MAXREDIRS, 50L);
curl_easy_setopt(hnd, CURLOPT_HTTP_VERSION, (long)CURL_HTTP_VERSION_2TLS);
curl_easy_setopt(hnd, CURLOPT_FTP_SKIP_PASV_IP, 1L);
curl_easy_setopt(hnd, CURLOPT_TCP_KEEPALIVE, 1L);
/* Here is a list of options the curl code used that cannot get generated
as source easily. You may choose to either not use them or implement
them yourself.](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-32-320.jpg)


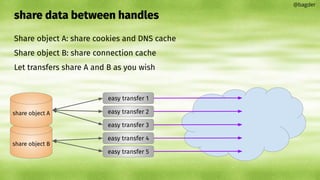
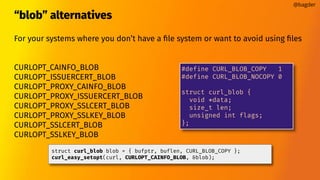
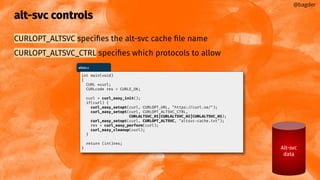
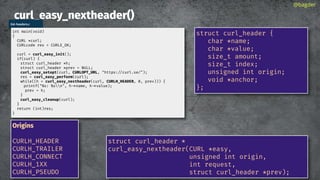
![shareable data
cookie jar
DNS cache
connection pool
TLS session-id cache
PSL
HSTS cache
[future]
@bagder](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-35-320.jpg)
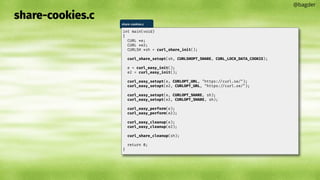











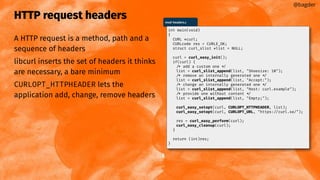
![Response code: 404.c
@bagder
404.c
#include <curl/curl.h>
int main(void)
{
CURL *curl;
CURLcode res = CURLE_OK;
curl = curl_easy_init();
if(curl) {
long code;
curl_easy_setopt(curl, CURLOPT_URL, "https://curl.se/typo.html");
res = curl_easy_perform(curl);
curl_easy_getinfo(curl, CURLINFO_RESPONSE_CODE, &code);
curl_easy_cleanup(curl);
printf("Result: %d Response code: %ldn",
(int)res, code);
}
return (int)res;
}
$ gcc 404.c -lcurl
$ ./a.out
[HTML]
Result: 0 Response code: 404](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-58-320.jpg)
















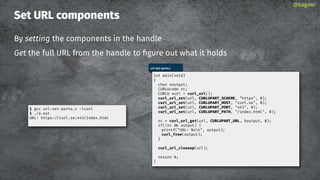
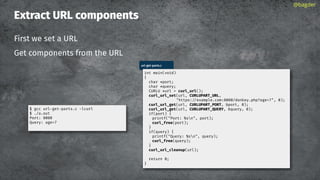
![URL API: parts
CURLUPART_[name]
URL is the entire thing
@bagder
scheme://user:password@host:1234/path?query#fragment
URL
SCHEME
USER
PASSWORD
OPTIONS
HOST
ZONEID
PORT
PATH
QUERY
FRAGMENT](https://image.slidesharecdn.com/masteringlibcurlpart2-231120221748-86c67a0c/85/mastering-libcurl-part-2-85-320.jpg)











This document discusses using libcurl's share API to share data like cookies and DNS caches between multiple easy handles. It explains that some curl state is kept in the easy handle, so transfers using different handles may not be fully independent. The share API allows creating share objects that specify what data to share, such as cookies and DNS caches. Easy handles can then specify which share objects to use to share data between transfers and achieve better performance than using separate handles independently.













































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)









