Downloaded 38 times






![LEGAL, SALES & TECH
[ ] I have read and agree to the EULA](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-8-2048.jpg)
![LEGAL, SALES & TECH
[ ] I have read and agree to the EULA](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-9-2048.jpg)
![LEGAL, SALES & TECH
[x] I have read and agree to the EULA](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-10-2048.jpg)
![LEGAL, SALES & TECH
[x] I have read and agree to the EULA](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-11-2048.jpg)
![LEGAL, SALES & TECH
[x] I have read and agree to the EULA
identity (KYC)](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-12-2048.jpg)
![LEGAL, SALES & TECH
[x] I have read and agree to the EULA
identity (KYC)](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-13-2048.jpg)
![LEGAL, SALES & TECH
[x] I have read and agree to the EULA
identity (KYC)
cashflow (accounts / txns)](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-14-2048.jpg)
![LEGAL, SALES & TECH
[x] I have read and agree to the EULA
identity (KYC)
cashflow (accounts / txns)
budget tool](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-17-2048.jpg)
![LEGAL, SALES & TECH
[x] I have read and agree to the EULA
identity (KYC)
cashflow (accounts / txns)
budget tool](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-18-2048.jpg)






![2010 – PO(S)T OF GOLD
<div class='main'><div class="naslov">
<div class="title">Prometi</div>
<div class='podnaslov'>
<div class='title'>Prometi po računu <span style='font-weight:normal;'>HR602360000</span>1234567890 (tekući
račun) za razdoblje od 05.10.2013. do 05.10.2014.</div>
</div>
<div id='prometiDospijeli'/><noscript language='JavaScript'>
<!--
var prometiDospijeli=new Array();prometiDospijeli[0]=new Array('07/01/2013','1234567890123456','Pasivna
kamata',0.01,null,78.82,'HRK');
prometiDospijeli[1]=new Array('08/14/2013','1234567890123451','Uplata redovitog primanja',2677.83,null,4756.65,'HRK');
prometiDospijeli[2]=new Array('08/19/2013','1234567890123452','Isplata',null,4750.00,6.65,'HRK');
prometiDospijeli[3]=new Array('08/19/2013','1234567890123453','Uplata',20.00,null,26.65,'HRK');
prometiDospijeli[4]=new Array('09/06/2013','1234567890123454','Naknada za korištenje - p.a. moderan',null,20.00,6.65,'HRK');
prometiDospijeli[44]=new Array('04/01/2014','1234567890123455','Zatezna kamata po nedopuštenom
prekoračenju',null,0.10,9.31,'HRK');
prometiDospijeli[46]=new Array('04/14/2014','1234567890123456','Osobno primanje isplaćeno u
cijelosti',2672.59,null,2661.90,'HRK');
prometiDospijeli[57]=new Array('05/26/2014','1234567890123457','E-zaba prijenos - super sport - uplata na
račun',null,2.20,0.12,'HRK');
createDataTablePrometi('prometiDospijeli',prometiDospijeli);
// -->
</noscript></div><noscript src='./JavaScript/InitPrometiValidation.js?v=1.18.00' language='JavaScript'></noscript>
<br /><br />
</div></div>
</div>](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-32-2048.jpg)
![2010 – PO(S)T OF GOLD
<div class='main'><div class="naslov">
<div class="title">Prometi</div>
<div class='podnaslov'>
<div class='title'>Prometi po računu <span style='font-weight:normal;'>HR602360000</span>1234567890 (tekući
račun) za razdoblje od 05.10.2013. do 05.10.2014.</div>
</div>
<div id='prometiDospijeli'/><noscript language='JavaScript'>
<!--
var prometiDospijeli=new Array();prometiDospijeli[0]=new Array('07/01/2013','1234567890123456','Pasivna
kamata',0.01,null,78.82,'HRK');
prometiDospijeli[1]=new Array('08/14/2013','1234567890123451','Uplata redovitog primanja',2677.83,null,4756.65,'HRK');
prometiDospijeli[2]=new Array('08/19/2013','1234567890123452','Isplata',null,4750.00,6.65,'HRK');
prometiDospijeli[3]=new Array('08/19/2013','1234567890123453','Uplata',20.00,null,26.65,'HRK');
prometiDospijeli[4]=new Array('09/06/2013','1234567890123454','Naknada za korištenje - p.a. moderan',null,20.00,6.65,'HRK');
prometiDospijeli[44]=new Array('04/01/2014','1234567890123455','Zatezna kamata po nedopuštenom
prekoračenju',null,0.10,9.31,'HRK');
prometiDospijeli[46]=new Array('04/14/2014','1234567890123456','Osobno primanje isplaćeno u
cijelosti',2672.59,null,2661.90,'HRK');
prometiDospijeli[57]=new Array('05/26/2014','1234567890123457','E-zaba prijenos - super sport - uplata na
račun',null,2.20,0.12,'HRK');
createDataTablePrometi('prometiDospijeli',prometiDospijeli);
// -->
</noscript></div><noscript src='./JavaScript/InitPrometiValidation.js?v=1.18.00' language='JavaScript'></noscript>
<br /><br />
</div></div>
</div>](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-33-2048.jpg)
![2010 – PO(S)T OF GOLD
<div class='main'><div class="naslov">
<div class="title">Prometi</div>
<div class='podnaslov'>
<div class='title'>Prometi po računu <span style='font-weight:normal;'>HR602360000</span>1234567890 (tekući
račun) za razdoblje od 05.10.2013. do 05.10.2014.</div>
</div>
<div id='prometiDospijeli'/><noscript language='JavaScript'>
<!--
var prometiDospijeli=new Array();prometiDospijeli[0]=new Array('07/01/2013','1234567890123456','Pasivna
kamata',0.01,null,78.82,'HRK');
prometiDospijeli[1]=new Array('08/14/2013','1234567890123451','Uplata redovitog primanja',2677.83,null,4756.65,'HRK');
prometiDospijeli[2]=new Array('08/19/2013','1234567890123452','Isplata',null,4750.00,6.65,'HRK');
prometiDospijeli[3]=new Array('08/19/2013','1234567890123453','Uplata',20.00,null,26.65,'HRK');
prometiDospijeli[4]=new Array('09/06/2013','1234567890123454','Naknada za korištenje - p.a. moderan',null,20.00,6.65,'HRK');
prometiDospijeli[44]=new Array('04/01/2014','1234567890123455','Zatezna kamata po nedopuštenom
prekoračenju',null,0.10,9.31,'HRK');
prometiDospijeli[46]=new Array('04/14/2014','1234567890123456','Osobno primanje isplaćeno u
cijelosti',2672.59,null,2661.90,'HRK');
prometiDospijeli[57]=new Array('05/26/2014','1234567890123457','E-zaba prijenos - super sport - uplata na
račun',null,2.20,0.12,'HRK');
createDataTablePrometi('prometiDospijeli',prometiDospijeli);
// -->
</noscript></div><noscript src='./JavaScript/InitPrometiValidation.js?v=1.18.00' language='JavaScript'></noscript>
<br /><br />
</div></div>
</div>](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-34-2048.jpg)




![2011 – SELENIUM
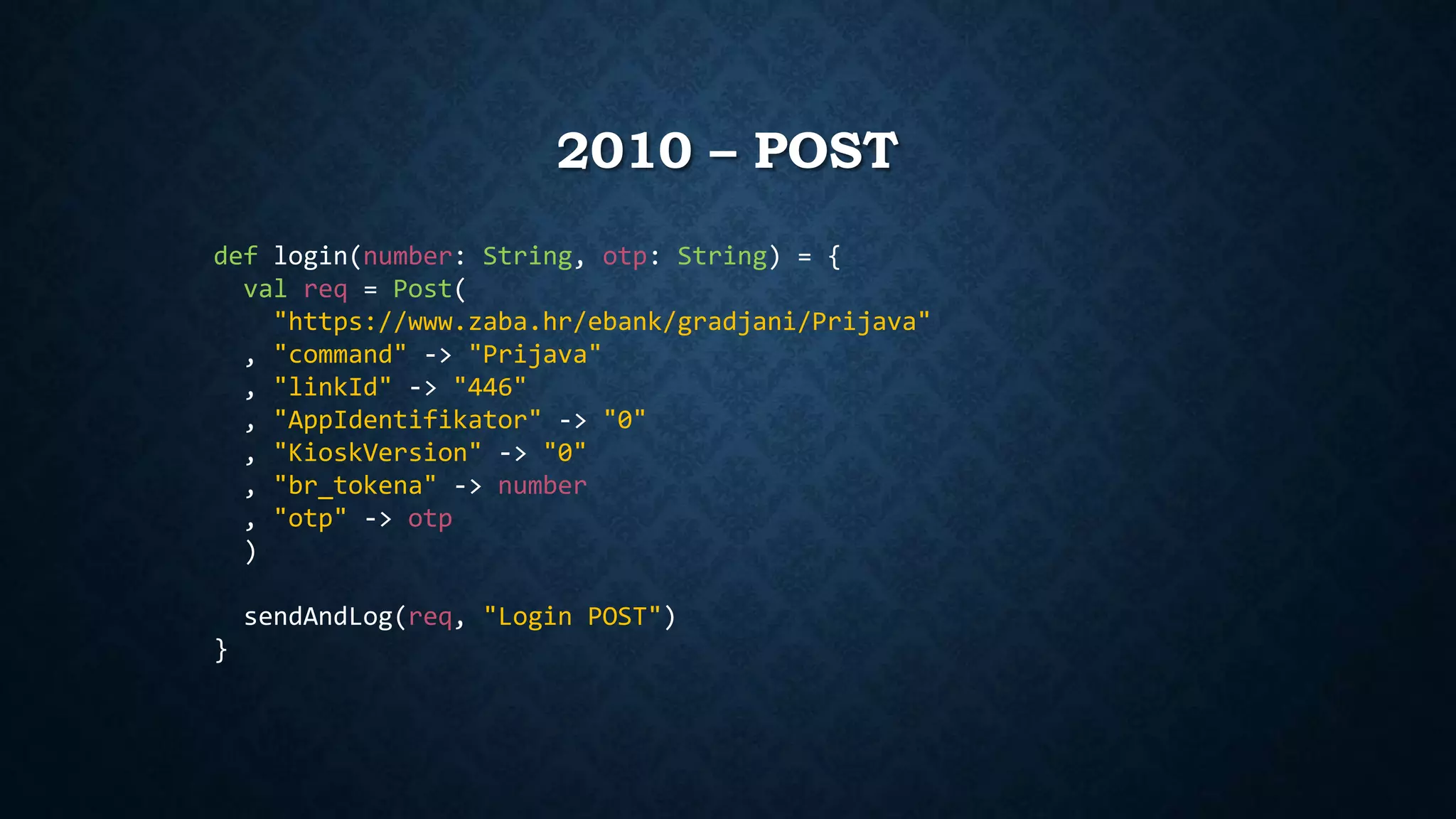
def doLogin(userCode: String, password: String) = {
val UserCode = By.xpath("//input[@id and @name='username']")
val Password = By.xpath("//input[@name='password']")
val ButtonOk = By.xpath("//button[@name='loginButton']")
findElement(UserCode).sendKeys(userCode)
findElement(Password).sendKeys(password)
findElement(ButtonOk).click()
}](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-39-2048.jpg)













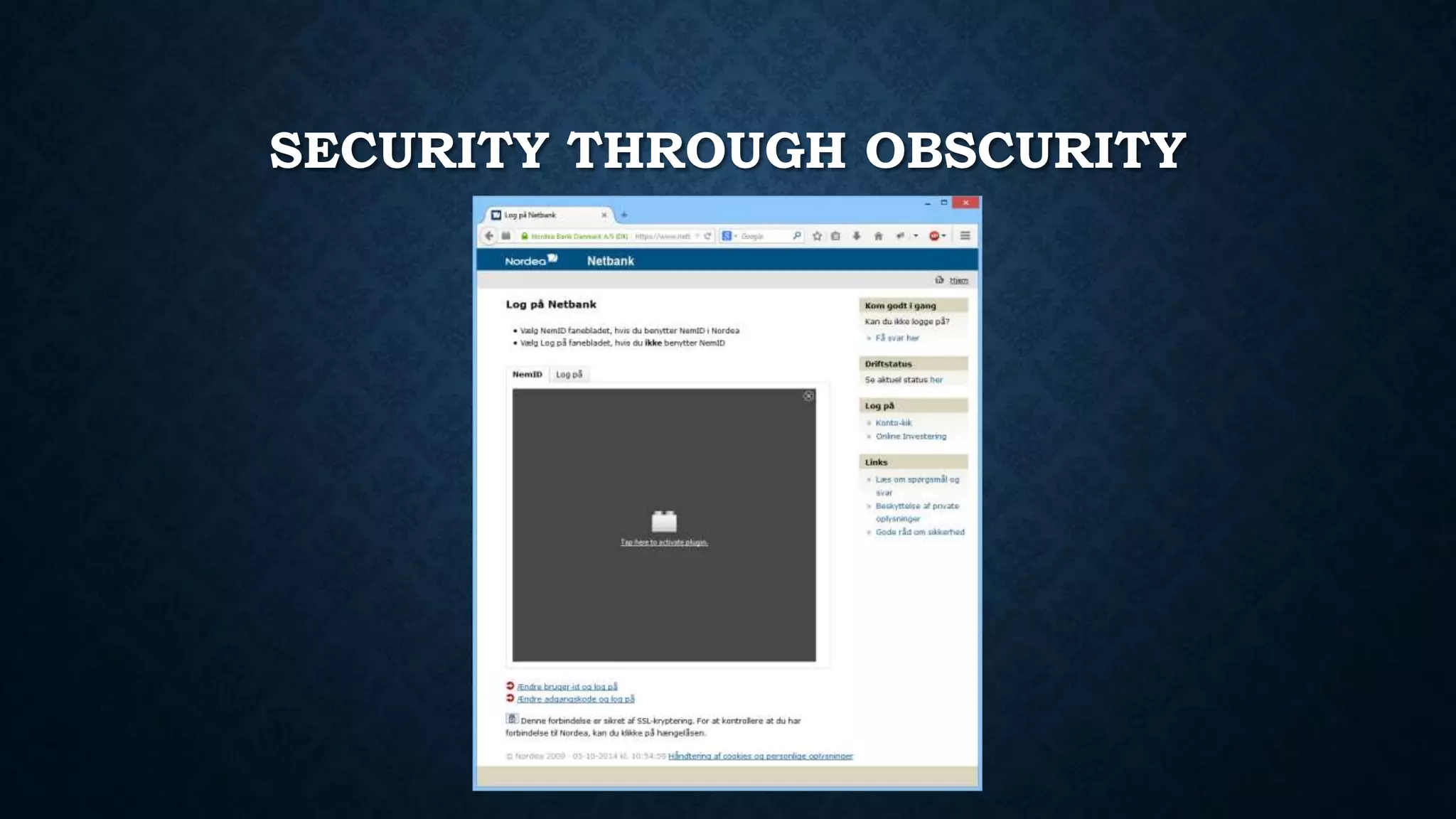
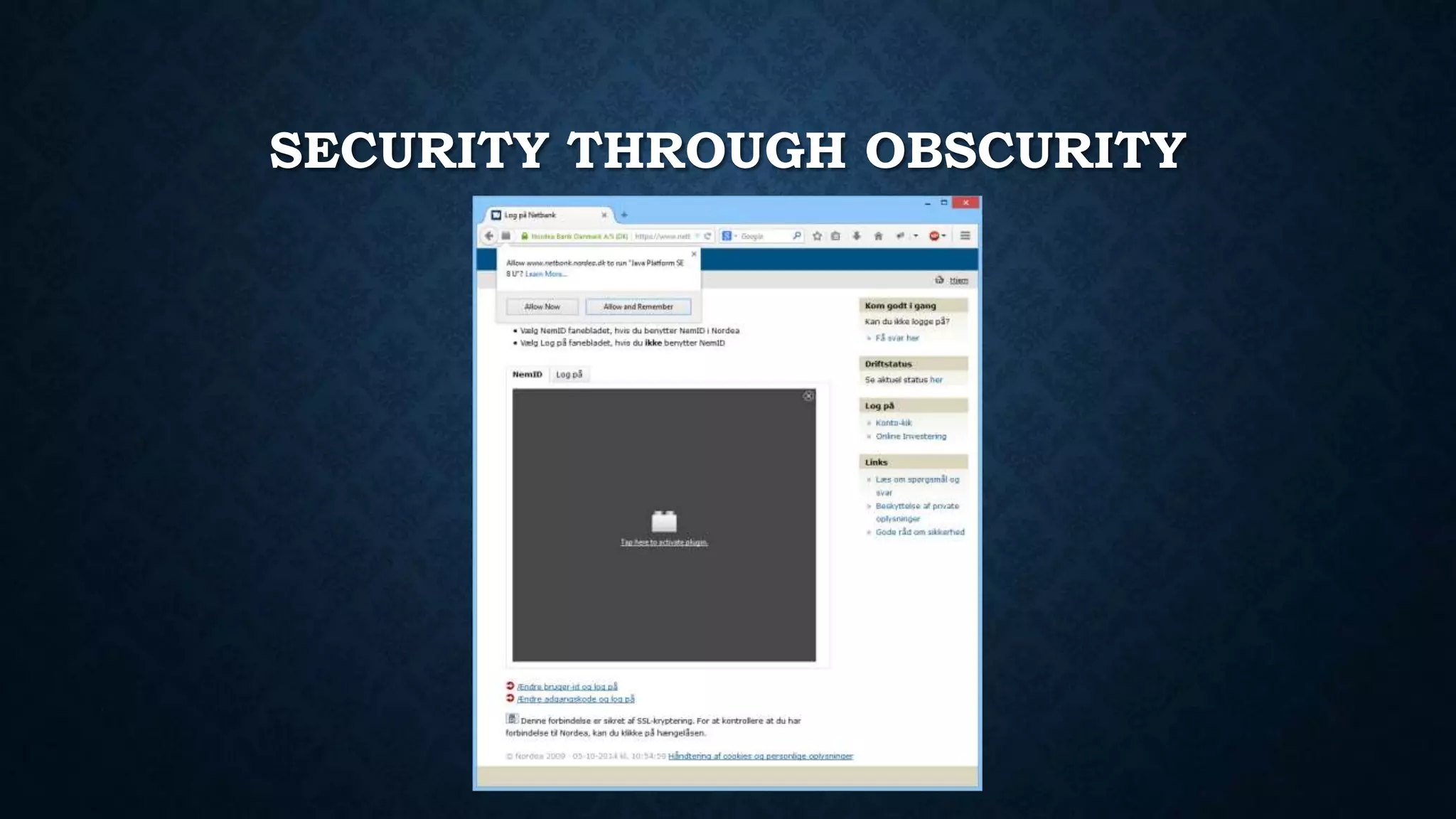
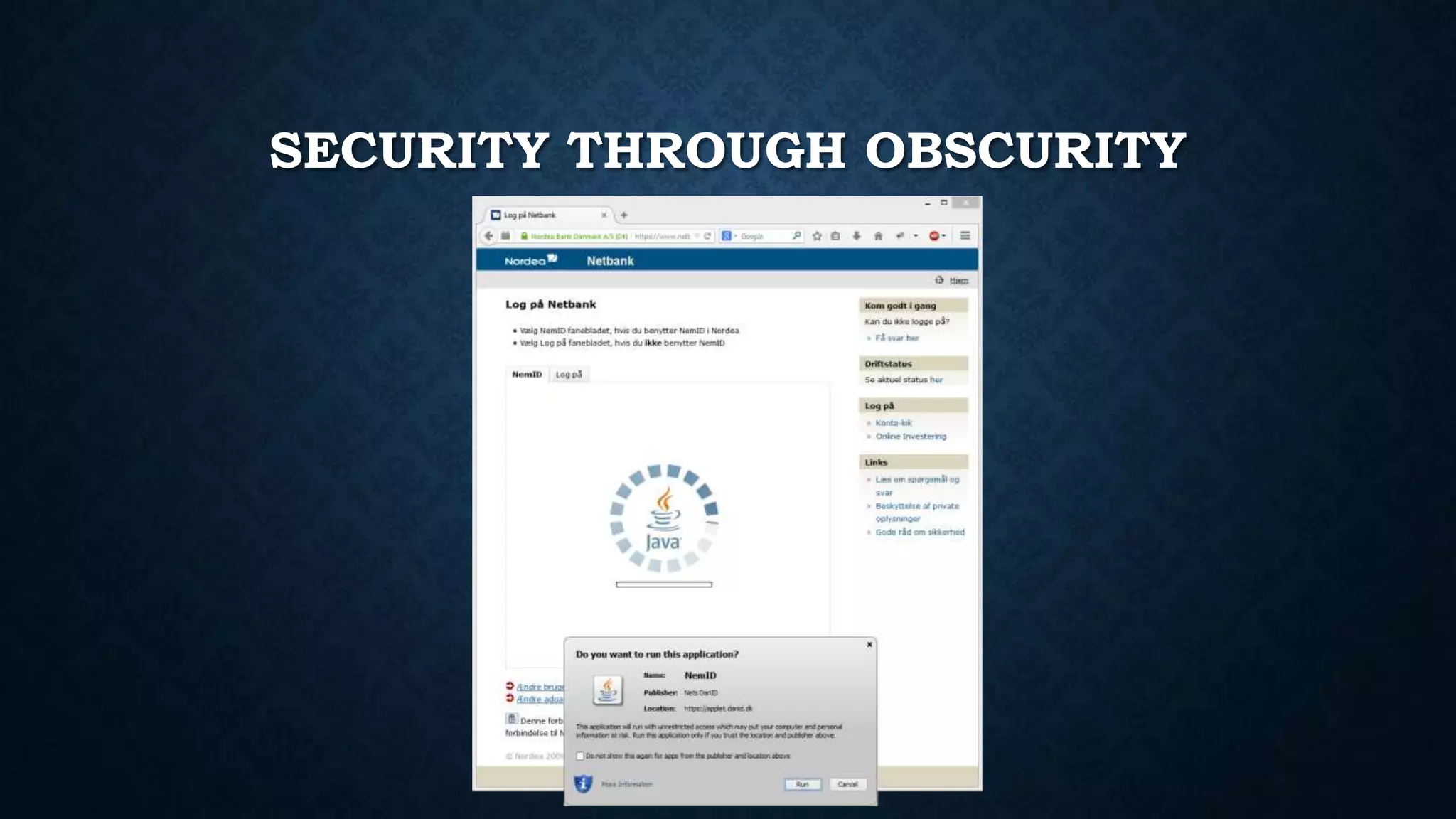
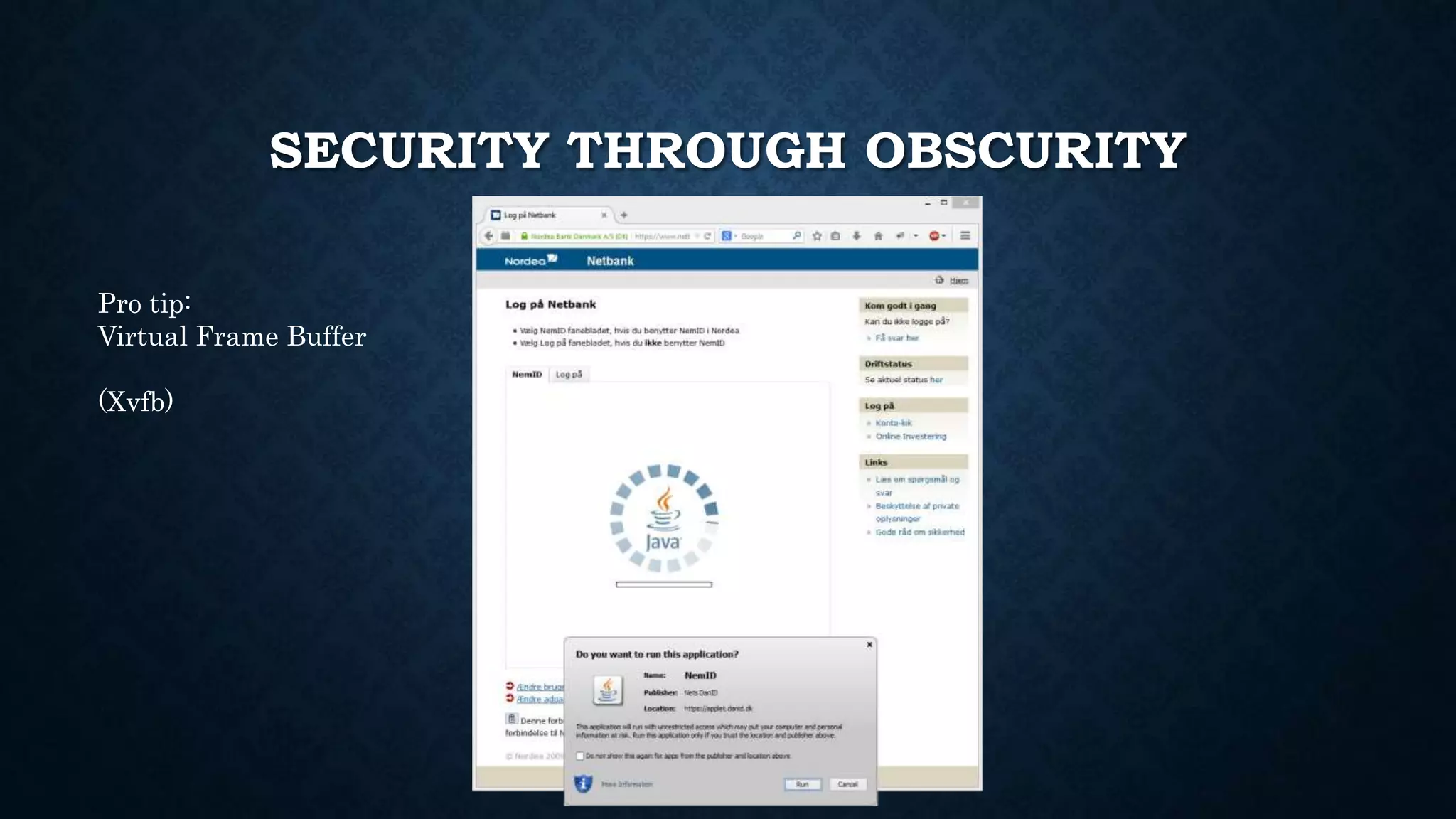













![F.Q.A.
(Faked Questions from the Audience)
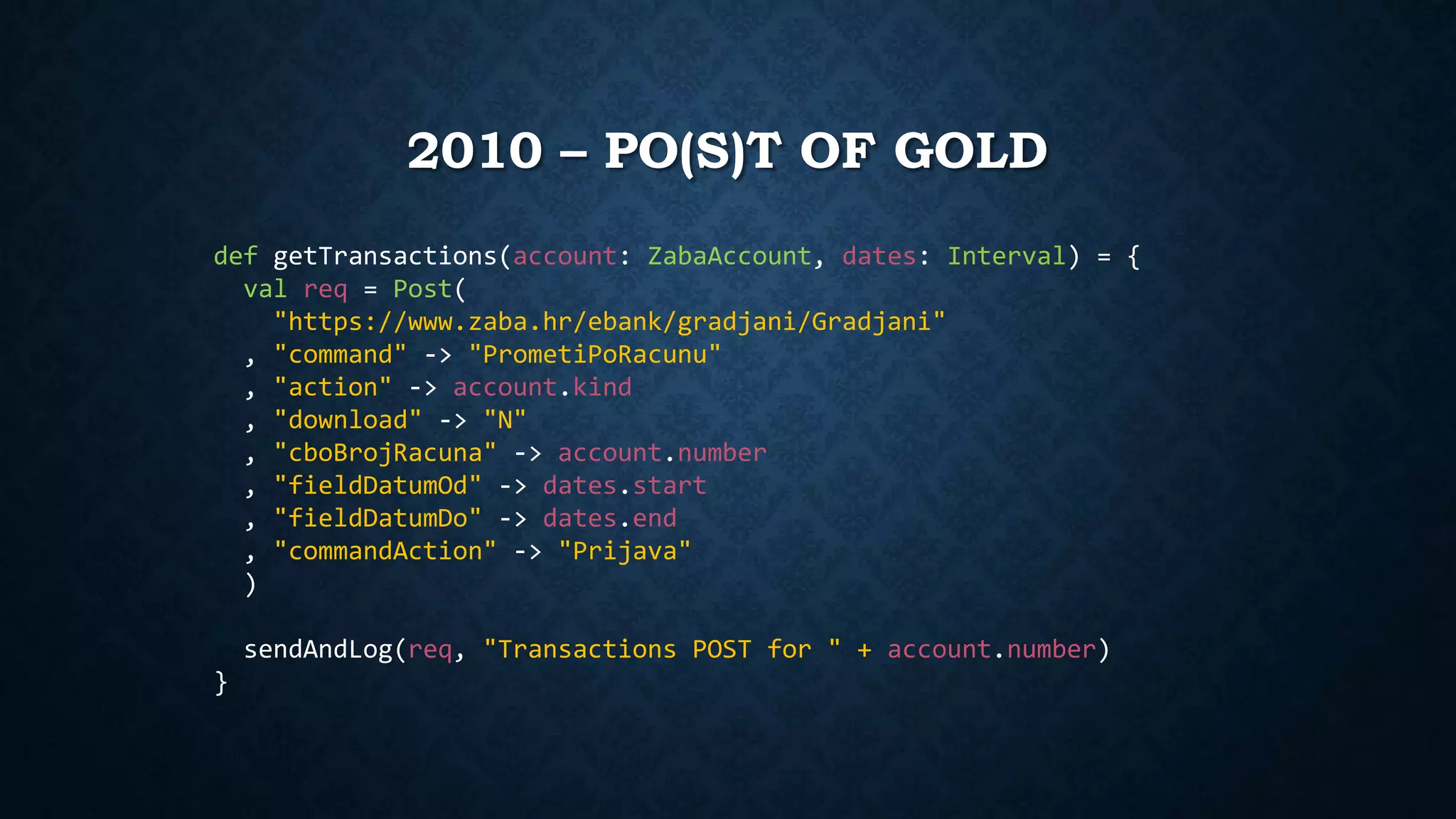
def doLogin(userCode: String, password: String) = {
val UserCode = By.xpath("//input[@id and @name='username']")
val Password = By.xpath("//input[@name='password']")
val ButtonOk = By.xpath("//button[@name='loginButton']")
findElement(UserCode).sendKeys(userCode)
findElement(Password).sendKeys(password)
findElement(ButtonOk).click()
}](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-77-2048.jpg)
![F.Q.A.
(Faked Questions from the Audience)
def doLogin(userCode: String, password: String) = {
val UserCode = By.xpath("//input[@id and @name='username']")
val Password = By.xpath("//input[@name='password']")
val ButtonOk = By.xpath("//button[@name='loginButton']")
findElement(UserCode).sendKeys(userCode)
findElement(Password).sendKeys(password)
findElement(ButtonOk).click()
}](https://image.slidesharecdn.com/mitmaob-141006034638-conversion-gate01/75/Man-in-the-Middle-Attack-on-Banks-78-2048.jpg)



The document discusses scraping banking websites using Selenium to access transaction and account information. It describes how the scraping was done in the past using direct POST requests, but has evolved to use Selenium due to changing security measures on banking sites. The author also discusses techniques for dealing with changing page structures, such as using multiple element locators and pattern matching.
























![[2.1] Web application Security Trends - Omar Ganiev](https://cdn.slidesharecdn.com/ss_thumbnails/2-150301070554-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)






























![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

