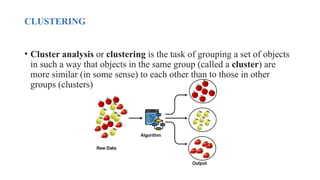
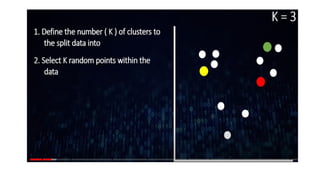
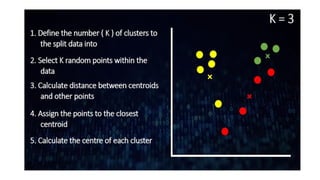
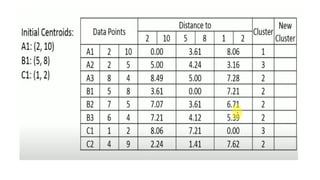
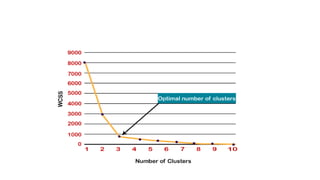
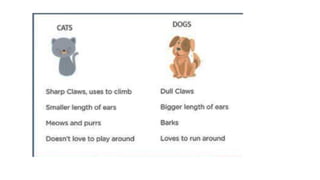
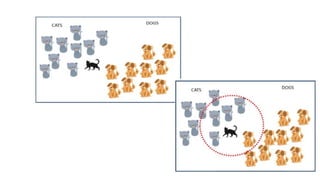
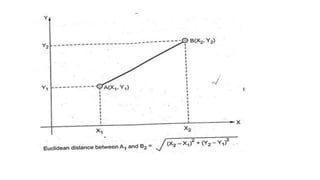
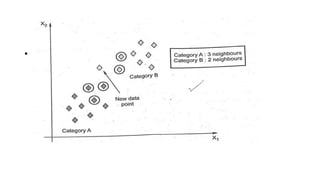
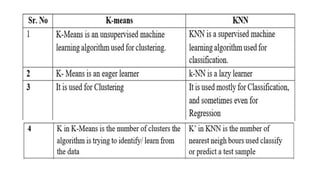
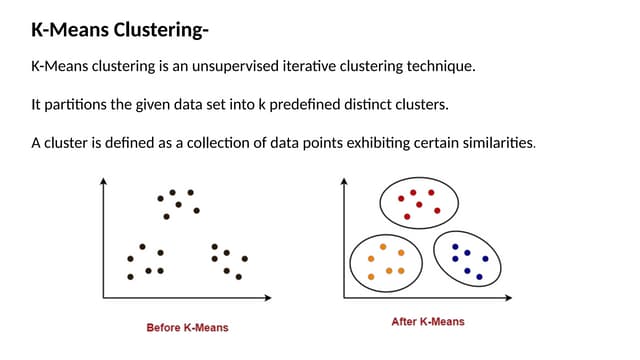
The document discusses k-means clustering, an unsupervised learning algorithm used for grouping similar objects into clusters, and highlights the elbow method for determining the optimal number of clusters. It also describes the k-nearest neighbors (k-NN) algorithm, a supervised learning approach that classifies data based on proximity to known instances. The k-NN process involves several steps, including calculating distances and determining the majority class among nearest neighbors.