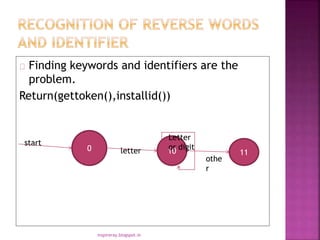
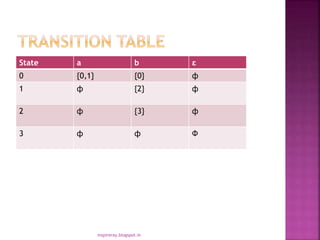
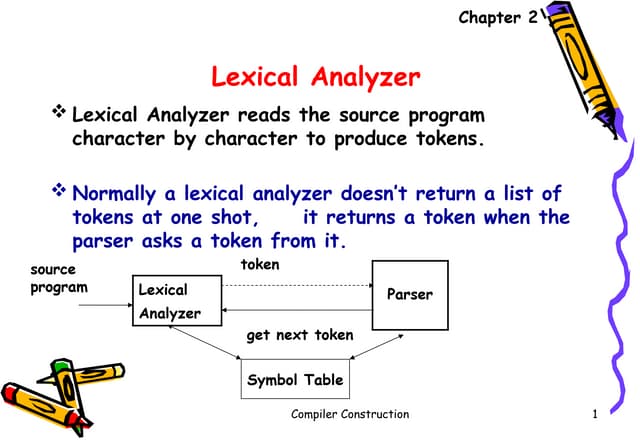
This document provides an introduction to lexical analysis and regular expressions. It discusses topics like input buffering, token specifications, the basic rules of regular expressions, precedence of operators, equivalence of expressions, transition diagrams, and the lex tool for generating lexical analyzers from regular expressions. Key points covered include the definition of regular languages by regular expressions, the use of finite automata to recognize patterns in lexical analysis, and how lex compiles a file written in its language into a C program that acts as a lexical analyzer.