Download to read offline











![Relational problems: Postgres on Gluster.
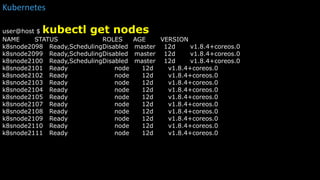
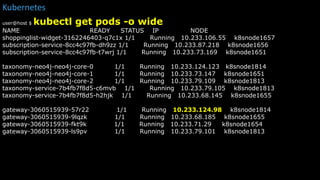
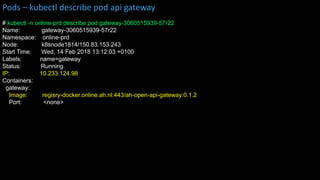
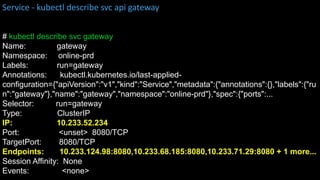
kubectl get
pg_restore: [archiver (db)] Error from TOC entry 53398; 0 16503 TABLE
DATA l1aaux_sci sdmcleod
pg_restore: [archiver (db)] COPY failed for table "l1aaux_sci": ERROR:
unexpected data beyond EOF in block 9391 of relation base/16386/17043
HINT: This has been seen to occur with buggy kernels; consider
updating your system.
CONTEXT: COPY l1aaux_sci, line 319329: "1854661 N
1.05156717906094999 1378796678.44843268 2012-02-01
07:04:39.5+00 2012-02-01 07:04:38.4484..."
pg_restore: [archiver (db)] Error from TOC entry 53399; 0 16528 TABLE
DATA l1afts_dbl sdmcleod
pg_restore: [archiver (db)] COPY failed for table "l1afts_dbl": ERROR:
unexpected data beyond EOF in block 10097 of relation
base/16386/17068
HINT: This has been seen to occur with buggy kernels; consider
updating your system.](https://image.slidesharecdn.com/bol-spaces-summit-kubernetes-2018-180615115047/85/Kubernetes-love-at-first-sight-22-320.jpg)










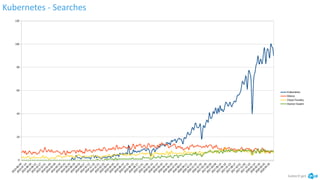
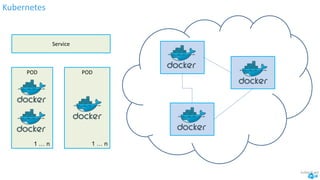
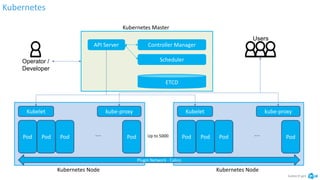
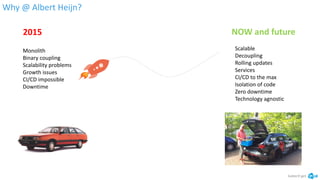
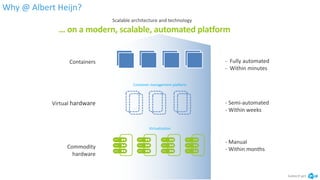
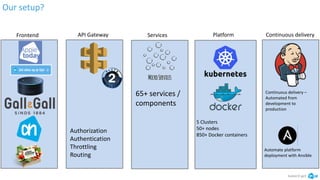
The document discusses the implementation and advantages of Kubernetes at Albert Heijn, focusing on its role in automating application deployment, scaling, and management. It addresses relational problems, both in storage and communication, encountered during this process, and highlights the benefits of using open-source tools to enhance their development and operational efficiency. The presentation concludes with an affirmation of Kubernetes as a stable and supportive environment for developers and DevOps practices.

















![[En] IPVS for Docker Containers](https://cdn.slidesharecdn.com/ss_thumbnails/ipvsdockerconeu2015-fullversion-151119045345-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)





































































