Agenda
2
Introductions and WorkshopObjectives
Conceptual Design
Solution Scope
Logical Design
Site Recovery Manager Design Session
Adoption for the Digital Workspace
<Process Type Name>
<Process Type Name>
<Process Type Name>
Next Steps
Consultant:
Before giving this presentation to a
customer, use the Delivery Reference
Guide to obtain the correct
Knowledge Transfer Content for this
engagement based upon the specific
products include in the Solution
Builder engagement file.
3.
3
Participant introductions
• Whatexperience do you have?
• Why are you attending this workshop?
• What do you expect to achieve?
Expectations of the workshop
• Outcomes expected of workshop
Introductions and Workshop Objectives
PS Consultant: Please fill out these bullet points to
provide scope and expectations of this workshop.
4.
4
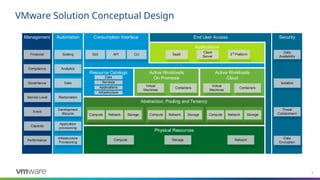
VMware Solution ConceptualDesign
Consumption Interface
Consumption Interface
Physical Resources
Abstraction, Pooling and Tenancy
Resource Catalogs
Management Security
Active Workloads
On Premesis
Automation
Applications
Active Workloads
Cloud
End User Access
Storage
API
GUI CLI
Virtual
Machines
Containers
Financial
Network
Compute
Data
Availability
Isolation
Threat
Containment
Data
Encryption
Event
Capacity
Performance
Service Level Reclamation
Infrastructure
Provisioning
Analytics
Data
SaaS 3rd
Platform
Client
Server
Development
lifecycle
Application
provisioning
Virtual
Machines
Containers
Compute Network Storage
Infrastructure
Applications
Services
Compute Network Storage Compute Network Storage
Scaling
Compliance
Governance
Data
6
These are theIT Capabilities that have been determined as the focus for this engagement
Solution Scope
IT Capabilities in Scope
Recover from data center outages
7.
7
These are theIT Problems that have been determined as the focus for this engagement
Solution Scope
IT Problems in Scope
High CAPEX and OPEX for disaster recovery
Manual process causing disaster recovery delays
8.
8
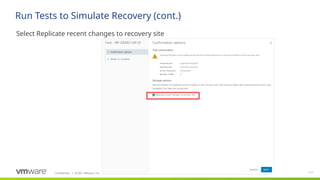
Logical Diagram
VMware Solution
PSOConsultant: Insert
appropriate logical diagrams
based on the current
solution. Review the
diagram, covering each
component and its function
9.
9
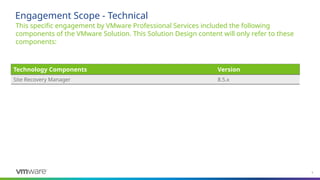
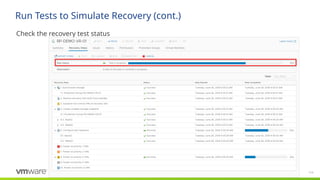
This specific engagementby VMware Professional Services included the following
components of the VMware Solution. This Solution Design content will only refer to these
components:
Engagement Scope - Technical
Technology Components Version
Site Recovery Manager 8.5.x
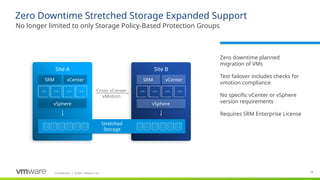
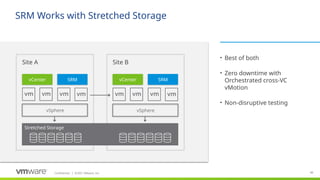
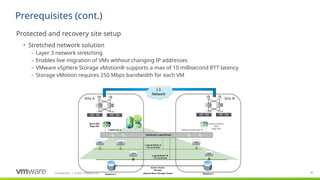
#14 Stretched storage support, which originally was made available in SRM 6.1 now supports regular VM Protection Groups, not just Storage Policy-Based Protection Groups.
It utilizes stretched storage (storage that presents the same storage/LUN/datastore to both sites at the same time as read-write) and cross-VC vmotion to move VMs between sties with zero downtime
Actual DR failovers will use SRM standard failover (vmotion isn’t possible if a site is down)
Non-disruptive testing will include testing for vmotion compliance for all powered on VMs on the stretched storage consistency group – protected or not
Dependencies can cause issues as vMotion VMs are done prior to other VMs
VM1 is configured for vMotion
VM2 is configure for regular failover
This will cause an error - VM1 depends on VM2 – because VM2 would be started first (since it is a vmotion VM)
There are some differences between SPPGs and VMPGs
Reverse mappings are required (if no reverse mappings then reprotect will fail)
Placeholder VMs are removed during planned migration (this could potentially cause an issue if there is a problem during the migration as if the placeholders are removed a subsequent migration will fail
Make sure to read the release notes!
Stretched datastores now appear in VMPG list
xVC vMotion
Test failover includes compliance checks for vmotion compliance
Results included in test results
Checks all VMs on stretched storage (same CG - protected or not) and powered on
Differences to SPPGs
Reverse mappings are required (if no reverse mappings reprotect will fail)
Placeholder VMs are removed during planned migration
vMotion steps are performed before regular failover
VM1 is configured for vMotion
VM2 is configure for regular failover
VM1 depends on VM2
Read the release notes - device isolation
No specific vSphere/vCenter requirements
Requires enterprise licensing
In the past there were Stretched cluster and SRM and it was really a choice between the two
The reason is a Stretched cluster requires single VC while SRM requires two VC instances, it’s a two VC concept
SRM now supports using Stretched Storage underneath SRM environment
With Stretched Storage – I’m talking about two active-active arrays on both sites provided by storage vendors with certain requirements for metro distance, low latency etc. depending by the Storage vendor
The biggest benefit – SRM now provides Zero downtime during planned migration from one site to another
It uses cross-VC vMotion technology to migrate the VMs without Power Off/Power On operation
And SRM can now non-disruptively test that
Before, if you’d wanted to test failover with Stretched Cluster, you had to take down one of your site and see what would happen
SRM lets you test this in an orchestration fashion – things will happen in the same order you defined. SRM will do vMotion compatibility checks for all VMs on the stretched devices.
SRM now combines the benefits of SRM with the advantages of Stretched Storage - to achieve what was previously only possible with Stretched Clusters
Planned maintenance and Disaster avoidance with Zero downtime
If some VMs, due any reason, are not eligible for cross-VC vMotion, SRM is still compatible and will use the old fashioned way to migrate the VMs with power Off and power ON to the other side.
=== more details ===============
Today customers who are looking for a disaster avoidance/recovery solution have to make a stark trade-off between two incompatible solutions: SRM or VMSC?
Benefits from SRM
Orchestrated DR
Management resiliency (VC at each site)
DR Testing
Traditional benefits of vMSC now available with SRM 6.1
Downtime avoidance – cross-site vMotion
Disaster avoidance – zero downtime (SRM could do DA but not zero downtime, though was orchestrated, vMSC is manual)
Automatic failover – w/SRM 6.1 Failover can be triggered by third system witness via SRM API
Requirements:
Stretched Storage solution
Storage clustering solution that supports distributed data mirroring
Read/write access to the same volumes from both sites
Some tie-break mechanism to avoid splitbrain
Examples: EMC VPLEX, IBM SVC, NetApp MetroCluster, etc.
Stretched Network solution
VMware NSX or 3rd party
Enables live migration of apps without changing IP addresses
Notes/Warnings:
Assumes VM IPs don’t change (can be changed if they are powered off, not for vMotion)
Recovery Plan testing doesn’t do anything with vMotion
Requires stretched storage and specific SRA (look for “supports stretched storage in SRA compatibility guide)
Orchestrated vMotion is only used with Planned Migration mode
vMotion in planned migration mode can be overridden for individual VMs or for the recovery plan (if vMotion would take too long, etc)
Not all arrays/vendors will support Recovery Plan testing (don’t allow snapshots of stretched datastore)
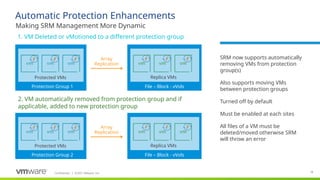
#15 Automatic unprotection/protection removal and automatic move between groups Delete VM or move to unprotected = unprotection
Steps
Move to other PG = move protection
Auto unprotection automatically turned off by default (autoprotect is on by default)
autoprotect.abrUnprotectEnabled
autoprotect.vvolUnprotectEnabled
These flags are per site (make sure to enable at both)
All files of a VM must be deleted/moved otherwise SRM will throw an error
autoprotect.username - name of a local account that SRM uses to check the local VC and SRM permissions when applying autoprotect - if left blank/default the SRM user is used
Demo
Auto protect VMs (migrate VM to protected LUN, or register VM already there)
Delete VM - show auto unprotect
#16 1. vSphere Replication and vRO and vROps mgmt packs now support FIPS (SRM did in 8.4)
2. Now when a replicated disks storage policy is changed when reconfiguring replication, the target replica’s storage will change as well
3. Additional metrics (Average disk read latency & Replication Network Latency) are now available through the vCenter reporting tool. Both at the VM and host level of the source. Additionally, there are other target site metrics available through the logs at the target site for now. More details here: https://confluence.eng.vmware.com/pages/viewpage.action?spaceKey=Replication&title=DataPath+Observability+Plan
4. 5. All UIs were upgraded to the latest version of Clarity
6. The datagrids in the UI have been redesigned to show more data with clusters with multiple datastores
vSphere Replication and Site Recovery Manager both now interoperate with LWD (less than 4 hr RPO replication engine used by VCDR (DRaaS for VMC on AWS). If a VM is protected by VCDR SRM & VR will throw errors if it is protected/replicated
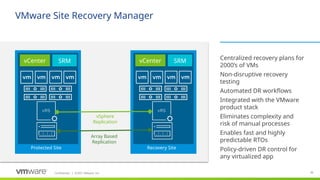
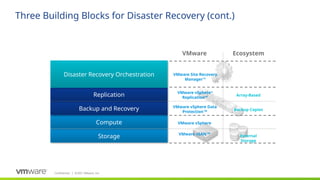
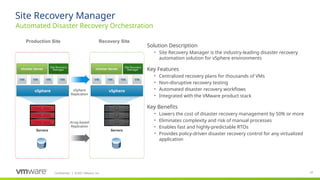
#18 Site Recovery Manager is a product specifically designed to leverage the capabilities of vSphere. SRM integrates tightly with vCenter Server to simplify DR management by automating the testing and orchestration of centralized recovery plans.
SRM essentially does 3 things:
1 – SRM simplifies the setup and on-going management of recovery and migration plans. Customers can replace traditional, manual runbooks with centralized recovery plans, which reduces the time required for set up from weeks to minutes.
2 - SRM automates the orchestration of the failover process to the secondary site, as well as the failback to the production environment. Failover and failback automation eliminates errors inherent with manual processes and eliminates complexity. This level of automation also enables users to test their recovery plans non-disruptively as frequently as required, increasing the predictability of Recovery Time Objectives (RTOs) and ultimately the level of confidence in the recovery plan.
3 – Last, SRM provides support flexibility to choose from different replication solutions. SRM can leverage vSphere Replication, the industry’s first hypervisor-based replication, which is included with the vSphere platform. SRM also supports a very broad range of array-based replication products from major storage and replication vendors.
Centralized recovery plans
Non-disruptive recovery testing
Automated DR workflows
Integrated with the VMware products
Eliminates complexity and risk
Fast and highly predictable RTOs
Policy-driven DR control
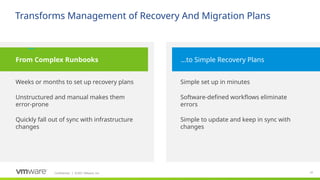
#19 One of the main aspects of the value proposition of SRM is simplifying the setup of recovery plans.
Setting up manual runbooks in traditional DR scenarios can be incredibly complex. The runbooks have to document all the required manual recovery steps. They are typically very long and complicated documents. Even worse, they very quickly fall out of sync with on-going configuration changes at the recovery site. And they provide plenty of room for errors, since they are documenting manual processes.
With SRM, recovery plans can be set up in minutes. Most of the recovery steps are automated and do not have to be actively managed by admins. Since the recovery plans are mostly automated, they are much more reliable than runbooks. And, they are much simpler to keep in sync with on-going configuration changes.
#20 vCenter Site Recovery Manager is a product specifically designed to leverage the capabilities of vSphere. SRM integrates tightly with vCenter Server to simplify DR management by automating the testing and orchestration of centralized recovery plans.
SRM essentially does 3 things:
1 – SRM simplifies the setup and on-going management of recovery and migration plans. Customers can replace traditional, manual runbooks with centralized recovery plans, which reduces the time required for set up from weeks to minutes.
2 - SRM automates the orchestration of the failover process to the secondary site, as well as the failback to the production environment. Failover and failback automation eliminates errors inherent with manual processes and eliminates complexity. This level of automation also enables users to test their recovery plans non-disruptively as frequently as required, increasing the predictability of Recovery Time Objectives (RTOs) and ultimately the level of confidence in the recovery plan.
3 – Last, SRM provides support flexibility to choose from different replication solutions. SRM can leverage vSphere Replication, the industry’s first hypervisor-based replication, which is included with the vSphere platform. SRM also supports a very broad range of array-based replication products from major storage and replication vendors.
#21 One of the main aspects of the value proposition of SRM is simplifying the setup of recovery plans.
Setting up manual runbooks in traditional DR scenarios can be incredibly complex. The runbooks have to document all the required manual recovery steps. They are typically very long and complicated documents. Even worse, they very quickly fall out of sync with on-going configuration changes at the recovery site. And they provide plenty of room for errors, since they are documenting manual processes.
With SRM, recovery plans can be set up in minutes. Most of the recovery steps are automated and do not have to be actively managed by admins. Since the recovery plans are mostly automated, they are much more reliable than runbooks. And, they are much simpler to keep in sync with on-going configuration changes.
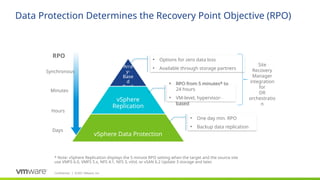
#25 RPO from 5 mins only when both source and target locations to be vSAN datastore else it reverts to 15 mins.
#26 RPO of 5 mins only when both source and target are vSAN datastore else it reverts to 15mins.
#30 From 5.8 on Multi-site doesn’t have to be configured up front
5.8 on made it easier to see what’s going on with multiple sites
#31
Introduced in SRM 6.1
Previously SRM required explicit management of contents of Protected Resources, including datastores and VMs
Management is primarily via UI
Limited management via API
This leads to operational overhead or complex orchestration configuration whenever we want to:
Protect/Unprotect VMs
Add/Remove datastores from Protection Groups
The existing operational overhead increases the cost to protect a VM.
Leveraging Storage Profiles to identify protected resources reduces costs by removing the SRM operations required to:
Protect/Unprotect VMs
Add/Remove datastores from protection groups
Configuration steps:
Create Tag catagory
Create Tag
Tag replicated storage
Create Storage Policy (tag based, using tag from previous)
Place VM on replicated storage and associate with SP
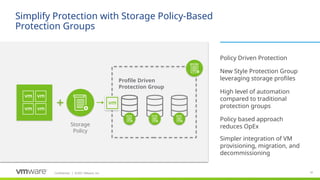
Customers managing at DR scale have been asking about automating the DR protection process using policies or integrations that step into VM creation workflow
The idea is that there is likely a strong correlation between VMs being provisioned into higher tiers of storage and VMs that need DR protection. So a customer can tie these two policies together using this new construct called SPPG which allows SRM protection groups to associate directly with storage profiles. Any VMs getting provisioned onto corresponding datastores will be automatically added to SRM’s DR protection and recovery plans
SRM will automatically discover and protect all corresponding datastores
SRM will automatically discover and protect all associated VMs
SPPGs support only array based replication
Other new SRM 6.1 features require SPPGs
FAQ
Legacy VM-based protection groups are still fully supported
Recovery Plans can either contain SPPGs or VM and/or ABR PGs, not both (SPPGs have to be in a RP by themselves, VM & datastore PGs can be in the same RP)
No more placeholders
MoRef no longer the same
When a VM is associated with a storage profile, vCenter picks a datastore from the profile’s datastore set
Association is per-VM and per-disk
The user can override the datastore selection manually
vCenter can perform a compliance check to ensure that VMs are still stored on the correct datastores
#32
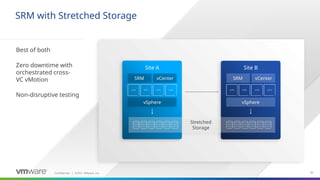
One new topology introduced in SRM 6.1 – Stretched Storage
In the past there were Stretched cluster and SRM and it was really a choice between the two
The reason is a Stretched cluster requires single VC while SRM requires two VC instances, it’s a two VC concept
SRM now supports using Stretched Storage underneath SRM environment
With Stretched Storage – I’m talking about two active-active arrays on both sites provided by storage vendors with certain requirements for metro distance, low latency etc. depending by the Storage vendor
The biggest benefit – SRM now provides Zero downtime during planned migration from one site to another
It uses cross-VC vMotion technology to migrate the VMs without Power Off/Power On operation
And SRM can now non-disruptively test that
Before, if you’d wanted to test failover with Stretched Cluster, you had to take down one of your site and see what would happen
SRM lets you test this in an orchestration fashion – things will happen in the same order you defined. SRM will do vMotion compatibility checks for all VMs on the stretched devices.
SRM now combines the benefits of SRM with the advantages of Stretched Storage - to achieve what was previously only possible with Stretched Clusters
Planned maintenance and Disaster avoidance with Zero downtime
If some VMs, due any reason, are not eligible for cross-VC vMotion, SRM is still compatible and will use the old fashioned way to migrate the VMs with power Off and power ON to the other side.
For more information about SS and Stretched clusters integration with SRM, there is a really good BLOG available publicly online
=== more details ===============
Today customers who are looking for a disaster avoidance/recovery solution have to make a stark trade-off between two incompatible solutions: SRM or VMSC?
Benefits from SRM
Orchestrated DR
Management resiliency (VC at each site)
DR Testing
Traditional benefits of vMSC now available with SRM 6.1
Downtime avoidance – cross-site vMotion
Disaster avoidance – zero downtime (SRM could do DA but not zero downtime, though was orchestrated, vMSC is manual)
Automatic failover – w/SRM 6.1 Failover can be triggered by third system witness via SRM API
Requirements:
Stretched Storage solution
Storage clustering solution that supports distributed data mirroring
Read/write access to the same volumes from both sites
Some tie-break mechanism to avoid splitbrain
Examples: EMC VPLEX, IBM SVC, NetApp MetroCluster, etc.
Stretched Network solution
VMware NSX or 3rd party
Enables live migration of apps without changing IP addresses
Notes/Warnings:
This feature is only available when using SPPGs
Assumes VM IPs don’t change (can be changed if they are powered off, not for vMotion)
Recovery Plan testing doesn’t do anything with vMotion
Requires stretched storage and specific SRA (currently only IBM and EMC VPLEX)
Orchestrated vMotion is only used with Recovery Plan – Planned Migration mode
vMotion in planned migration mode can be overridden for individual VMs or for the recovery plan (if vMotion would take too long, etc)
Not all arrays/vendors will support Recovery Plan testing (don’t allow snapshots of stretched datastore)
#33
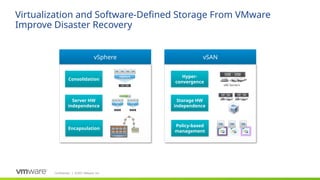
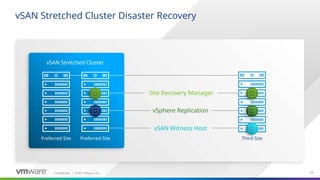
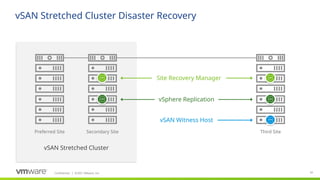
VMware Site Recovery Manager and vSphere Replication are compatible with standard vSAN clusters and vSAN stretched clusters. vSphere Replication is configured on a per-VM basis with RPOs as low as five minutes. It is simple to deploy using virtual appliances at both the source and target locations for bidirectional VM protection. Recovering a VM with vSphere Replication is a matter of just a few mouse clicks for each VM. To automate and scale the disaster recovery solution, Site Recovery Manager – or SRM – can be layered on top of vSphere Replication.
SRM provides a number of orchestrated workflows including disaster recovery, planned migration, and recovery plan testing. SRM’s automation capabilities and scale make it possible to recover hundreds of virtual machines in just a few hours with the press of a button. Furthermore, since these are all VMware solutions, you only need to call one number to get support for the entire stack, if needed. This is especially beneficial in a high-stress, disaster recovery situation.
In this diagram we see a vSAN stretched cluster across two sites on the left side of the slide. A third site – the disaster recovery site – is located on the right side. Note that the vSAN Witness Host is deployed at the disaster recovery site. There are two virtual machines running SRM – one running on the vSAN stretched cluster and one running at the third site. A vCenter Server Virtual Appliance – or VCSA – is running on the stretched cluster and at the third site. These are not shown in the diagram for simplicity. There is also vSphere Replication virtual appliances running on the stretched cluster and at the third site. To scale vSphere Replication, you can run multiple vSphere Replication virtual appliances – up to 10 per vCenter Server environment.
Let’s take a closer look at vSphere Replication and SRM. We will then conclude with a demo that shows a vSAN stretched cluster, vSphere Replication, and SRM working together to minimize downtime when failures occur.
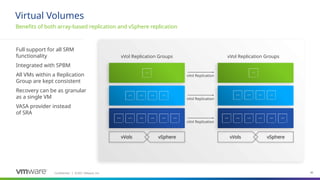
#34 Key Message/Talk track:
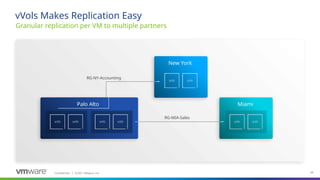
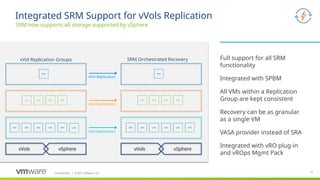
vSphere Virtual Volumes introduces the concept of Replication Groups bringing more efficient, accurate, and responsive recovery of your virtual machines. A Replication Group is a group of replicated storage devices as defined by a storage administrator (perhaps acting on behalf of an application owner) to provide atomic failover for an application. In other words, a Replication Group is the minimum unit of failover. In vSphere 6.5, Replication Groups are created and managed by a storage administrator using the storage vendor’s tools or created on the fly(if the array supports so called "automatic" RG group selection).
Replication Groups also define the set of vVols that are maintained in write-order fidelity where writes are replicated on the destination site in the exact same order they're generated at the source site to ensure at any time the destination site represents at least a crash-consistent version of the data on the source site.
Overview:
How it works:
Vendor specific replication capabilities are advertised up to vSphere via VASA
VI administrators create VM storage policies containing replication capabilities from the storage system
Details:
When VMs are being provisioned the user:
1. Selects a policy containing the replication capabilities
2. Chooses the compatible datastore
3. Chooses a replication group in which to place the VM (to support multi-VM consistency)
4. Completes the provisioning
From on-slide:
Replication is modeled as relationship (“Replication Group”) between “Fault Domains”
Topology Discovery (Fault Domains, Replication Groups) through VASA APIs
Replicate between multiple partners based on your requirements
Reduced WAN traffic
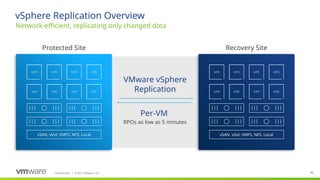
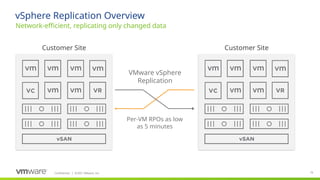
#35 To summarize…
vSphere Replication is used today to protect thousands of VMs. vSphere Replication has matured nicely since its introduction in 2011 with vCenter Site Recovery Manager (SRM).
vSphere Replication transmits only the changes to a VM, which reduces the amount of network bandwidth required. Further efficiency is achieved through compression that is enabled optionally on a per-VM basis.
vSphere Replication is included with vSphere Essentials Plus Kit and higher editions making it a very cost effective solution.
vSphere Replication is can be deployed with as little as one virtual appliance and it is managed using the familiar vSphere Web Client user interface.
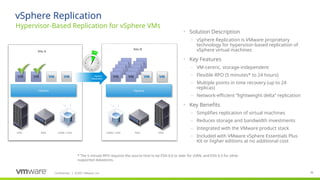
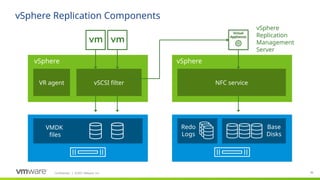
#36 This is a logical diagram showing the main components of vSphere Replication (VR). The replication components that are built into vSphere include the VR agent and VSCSI filter.
VR agent: The agent provides the plugin for vSphere Replication and coordinates the schedule to achieve configured RPOs.
VSCSI filter: The VSCSI filter is part of the vmkernel and intercepts I/O to the storage. The filter also tracks which regions of each disk have changes and records that information in memory. Disk consistency within a VM is coordinated by the VSCSI filter. Consistency across VMs is not currently supported. The VSCSI filer driver also transmits (replicates) changed data to a vSphere Replication (VR) appliance - specifically, to the vSphere Replication Server (VRS) component.
There are two types of VR virtual appliances:
vSphere Replication Management Server (VRMS): The first vSphere Replication (VR) virtual appliance deployed must be the appliance that contains the Management Server (VRMS) component and also the Server (VRS) component (which received replicated data - more on that in the next slide). One VRMS is deployed per vCenter Server environment. The VRMS maintains mappings between the source VM and its replica at the target location. VRMS also allocates storage, handles authentication, and provide the management interface for SRM. It also contains the vSphere Replication Server component (below). Only one VRMS is deployed per vCenter Server environment. In some cases, e.g. smaller environments, this is the only virtual appliance that must be deployed. This appliance also includes the vCloud Air tunneling agent (vCTA) that is used with the vCloud Air Disaster Recovery (DR) service.
vSphere Replication Server (VRS): These are not required since the VRMS also contains this component, but up to 9 can be deployed in a vCenter Server environment (in addition to the VRMS for a total of 10 appliances). This facilitates scale (up to 2000 VMs total) and helps spread the replication workload across multiple appliances. VR uses vSphere’s Network File Copy protocol to move replicated data from an appliance to storage. The data is first written to redo logs and then, after all data has been received, the redo logs are committed to the base disks. This mechanism helps ensure the integrity of the replica and makes it possible to recovery a VM at any given moment (whether replication is in process or not). The vSphere Replication Server (VRS) appliance does not contain the VRMS component.
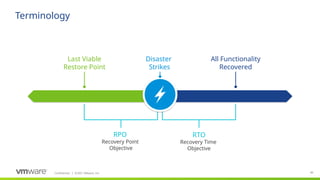
#37 vSphere Replication supports recovery point objectives (RPOs) from 5 minutes to 24 hours to address a wide variety of business requirements. Since it is a host-based replication solution, it works with vSAN, traditional SAN and NAS, VVol-enabled SAN and NAS, and local direct-attached storage. It is possible to replicate between different storage types, e.g. VSAN to SAN. Recovery is performed on a per-VM basis. Each recover takes only a few minutes to help minimize downtime.
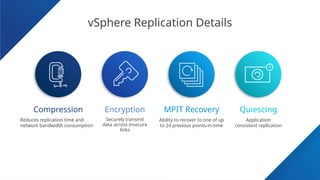
#38 New to vSphere Replication 6.0 is the option to enable compression, which further minimizes network bandwidth consumption. Compression is enabled when configuring replication on a per-VM basis. It is disabled by default. Also new is the ability to isolate replication and management traffic. This makes it easier for administrators to control bandwidth and improve security since vSphere Replication traffic is not encrypted. vSphere Replication can optionally quiesce many Windows file systems and Microsoft Volume Shadow Copy Service (VSS) aware applications. A few recent distributions of Linux file systems can also be quiesced for replication. Quiescing file systems and applications increases the reliability of recovered workloads.
#39 There are multiple use cases that can be addressed with vSphere Replication. These range from local data protection.
For example, keeping a second copy of a VM locally “just in case” - to disaster recovery by replicating VMs across geographically dispersed locations. vSphere Replication is also useful for data center migration - VMs can be replicated from the old site to the new site, power down the old VMs, and recover the new VMs with no data loss and minimal downtime.
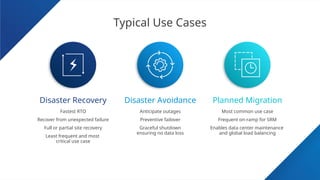
Use cases:
Disaster Recovery – protection of a VM against unplanned outages,
Disaster Avoidance – proactive replication and failover of VM workloads to secondary/target sites in the cases of upcoming natural disasters.
Planned Migration – planned migration of VM workloads in the situation of site hardware maintenance, etc.
VMware Site Recovery Manager is a disaster recovery orchestration solution that requires replication of VMs between sites. vSphere Replication works very well with Site Recovery Manager and enables selection of single VM, a few VMs, or many VMs to be included in a Site Recovery Manager recovery plan. This is especially useful with larger numbers of VMs where finer selection and control is desired.
vSphere Replication can replicate VMs within the same site, across two sites, and ROBO environments. ROBO example: 8 remote sites all replicating VMs into a main data center site.
vSphere Replication is also the replication engine for vCloud Air DR. For example, a customer with a single site needs DR protection, but does not want to invest in and manage a secondary DR site. This customer can simply subscribe to vCloud Air DR and use vSphere Replication to replicate the customer’s on-premise VMs to vCloud Air. If disaster recovery is needed, the VMs can easily be recovered and utilized in vCloud Air.
#41 To estimate the amount of bandwidth that vSphere Replication requires, VMware provides an unsupported tool, the vSphere Replication Capacity Planning Appliance, that you can download from http://labs.vmware.com/flings/vsphere-replication-capacity-planning-appliance.
You can also use the vSphere Replication Calculator at http://www.vmware.com/vrcalculator for initial guidance.
#44 Key Message/Talk track:
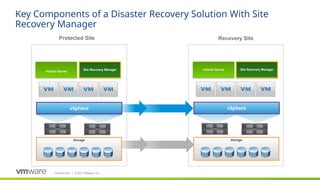
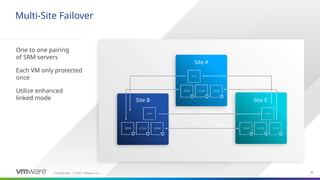
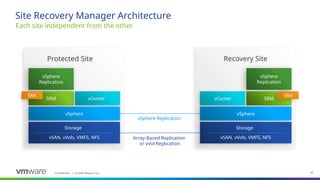
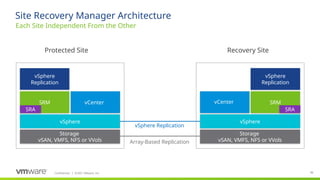
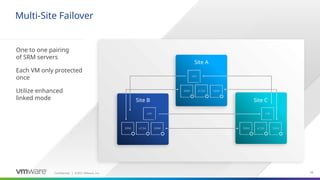
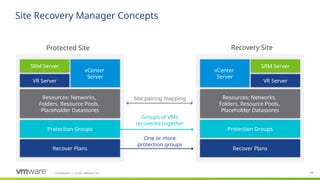
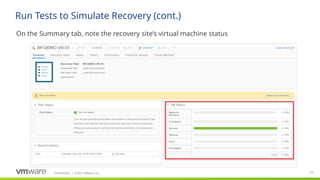
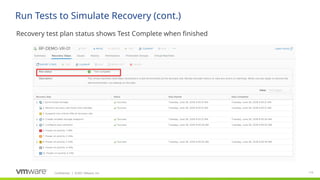
Site Recovery Manager is designed for the scenario that we see our customers most commonly implementing for disaster recovery—two datacenters. Site Recovery Manager supports both bi-directional failover as well as failover in a single direction. In addition, there is also support for multi-site configurations.
The key elements that make up a Site Recovery Manager deployment:
- vCenter at each site, hosts at each site, storage at each site. Each site is a mirror of the other so that there are no dependencies between them.
Storage: Site Recovery Manager supports any storage supported by vSphere (see replication slides for more detail)
VMware vSphere: Site Recovery Manager is designed for virtual-to-virtual disaster recovery. It works with many versions of ESX and ESXi (consult product documentation for more details).
Site Recovery Manager requires that you have a vCenter Server management server at each site; these two vCenter Servers are independent, each managing its own site, but Site Recovery Manager makes them aware of the virtual machines that they will need to recover if a disaster occurs. Note that these vCenters can be different versions of and do not have to be the most current vCenter release
Site Recovery Manager appliance (appliance only as of version 8.4): the Site Recovery Manager service is the disaster recovery brain of the deployment and takes care of managing, updating, and executing disaster recovery plans. Site Recovery Manager ties in very tightly with vCenter Server
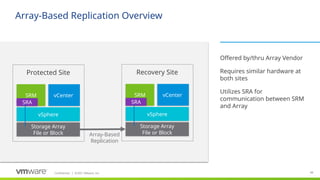
Storage-based (also called array-based) replication: Site Recovery Manager can utilize storage vendors’ array-based replication to get the important data from the protected site to the recovery site. Site Recovery Manager communicates with the replication via storage replication adapters (or through the VASA provider for vVols) that the storage vendor creates and certifies for Site Recovery Manager.
vSphere Replication is host based per VM replication and has no restrictions on use of storage-type or adapters (it does have other restrictions, see VR slide). It supports any storage supported by vSphere.
Key Points:
Site Recovery Manager is designed for virtual-to-virtual recovery for the VMware vSphere environment
Built for two-site scenario but can protect bi-directionally. Can also protect multiple sites (N:1, 1:N and some other varients – see later in this deck for details)
No physical-to-virtual recovery today
Works with supported versions of vCenter Server, ESX, and ESXi. (Consult product documentation for specific versions that are supported/required).
Site Recovery Manager is tightly integrated with VMware vCenter Server
Site Recovery Manager integrates with third-party storage-based replication (also known as array-based replication) to move data to the remote site
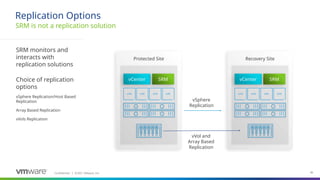
#45 Key point – SRM is not a replication solution, it interoperates with them, it doesn’t handle replication itself
You can use both vSphere Replication, Array Based Replication and vVol replication, just not for the same VM and VMs of the different protection types can’t be in the same protection group
ABR must be on the compatibility list and support both replication (either sync or async) and snapshot or cloning to support running SRM Recovery Plan tests
The next 3 slides cover these replication options in more detail
#46 Key Message/Talk track:
SRM now supports VMs on vVols replicated with array-based replication (previously SRM only supported vVols with vSphere Replication).
vVols provide many of the benefits of VR (granularity of protection, per-VM replication) with the benefits of array-based replication (multi-VM consistency groups, storage policy-based management, etc).
vVols use the VASA provider instead of the SRA
vVols enable automatic VM protection, just by associating a VM (that is already on a vVol) with a policy that includes replication, or by placing a VM onto a vVol and associating it with a replication policy, the VM will be automatically protected
vVols are the future of storage at VMware and provide significant benefits to customers. For more details on vVols see the vVol tech overview deck
----------------------------------
Overview:
vVols now supported with SRM
Initially only Pure, 3Par and Nimble
Internal:
https://confluence.eng.vmware.com/pages/viewpage.action?spaceKey=SRM&title=VVol+support
SRM now supports all storage supported by vSphere, local, block, file, vSAN and vVOL
Simplify DR orchestration for all of your datastores – VMFS, NFS vVols, vSAN and local
Easily extend VM protection to existing vVols replication policies
Use with any VASA 3.0 and vVols 2.0 array
#47 Offered by/thru Array Vendor
Requires similar hardware at both sites
Utilizes SRA for communication between SRM and Array
#48
vSphere Replication is configured on a per-VM basis allowing fine control over which VMs are replicated. After the initial replication, only changes to the VM are replicated to minimize network bandwidth consumption. vSphere Replication is included with vSphere Essentials Plus Kit and higher editions
Limitations - VR doesn’t support:
Replicating anything other than VMs (templates, images, etc)
Multi-VM consistency groups
Multi-writer disks
Physical mode RDMs
#49 Key Message/Talk track:
End-to end network compression can be enabled when configuring replication for 1 or more VMs. It is disabled by default. Enabling this feature is very simple - a single checkbox. No knobs to tune. vSphere Replication uses FastLZ for faster/lower CPU overhead than other comparable compression algorithms, but with similar compression ratios. The ratio is typically from 1.6:1 to 1.8:1. Replicated data is compressed on the primary and stays compressed until they are written to storage at the target location. While reducing network bandwidth utilization, it does require additional CPU cycles at the source and target. This is usually not an issue as most vSphere environments have sufficient CPU capacity to handle the additional load. The amount of additional CPU cycles will of course depend on the number of VMs and amount of data being replicated.
For example, a virtual machine containing 37GB of data took 52 minutes to replicate with compression off. With compression enabled, that same 37GB of data was compressed to 20GB and took only 29 minutes to replicate.
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
#52 vMotion requirement:
vMotion supports a max of 10 millisecond RTT latency
vMotion requires 250 Mbps bandwidth for each VM
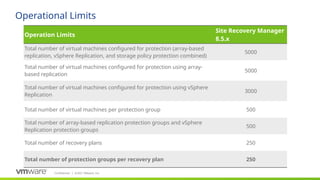
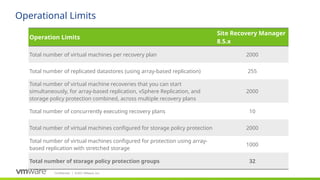
#53 Scalability limits have changed significantly from 6.5, and are still not enforced. The limits, however, should be adhered to in order to ensure supportability.
https://kb.vmware.com/kb/2102453.
#54 Scalability limits have changed significantly from 6.5, and are still not enforced. The limits, however, should be adhered to in order to ensure supportability.
https://kb.vmware.com/kb/2102453.
#56 Key Message/Talk track:
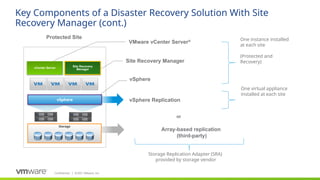
Site Recovery Manager is designed for the scenario that we see our customers most commonly implementing for disaster recovery—two datacenters. Site Recovery Manager supports both bi-directional failover as well as failover in a single direction. In addition, there is also support for multi-site configurations.
The key elements that make up a Site Recovery Manager deployment:
VMware vSphere: Site Recovery Manager is designed for virtual-to-virtual disaster recovery. It works with many versions of ESX and ESXi (consult product documentation for more details). Site Recovery Manager also requires that you have a vCenter Server management server at each site; these two vCenter Servers are independent, each managing its own site, but Site Recovery Manager makes them aware of the virtual machines that they will need to recover if a disaster occurs. Note that these vCenters can be different versions of and do not have to be the most current vCenter release (vCenter 6.0 U3, 6.5 or 6.7)
Site Recovery Manager service: the Site Recovery Manager service is the disaster recovery brain of the deployment and takes care of managing, updating, and executing disaster recovery plans. Site Recovery Manager ties in very tightly with vCenter Server — in fact, Site Recovery Manager is managed via a vCenter Server plug-in.
Storage: Site Recovery Manager requires iSCSI, FibreChannel, or NFS storage that supports replication at the block level.
Storage-based (also called array-based) replication: Site Recovery Manager relies on storage vendors’ array-based replication to get the important data from the protected site to the recovery site. Site Recovery Manager communicates with the replication via storage replication adapters that the storage vendor creates and certifies for Site Recovery Manager. VMware is working with a broad range of storage partners to ensure that support for Site Recovery Manager will be available regardless of what storage a customer chooses, so expect the list to continue to grow.
vSphere Replication has no such restrictions on use of storage-type or adapters.
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
Highlight version flexibility
Script:
We start with our customer site. Note that we support vCenter running either version 6.0 U3 or 6.5 U1. Any underlying storage supported by VMware is supported. If using vSAN or VVOLs, policies can
Next we add a VMC on AWS instance. Note that all components including components related to VSR are deployed, managed and maintained by VMware. No customer interaction is needed (or possible) in the management of vCenter, Hosts, vSAN, vSphere Replication or SRM
Now we enable the Site Recovery add-on which automatically deploys vSphere Replication and the Site Recovery Manager server to our VMC on AWS instance
Next the customer deploys vSphere Replication and Site Recovery Manger to their on prem environment, pairs the sites, maps resources and starts replicating and protecting VMs
We start with our protected site and recovery site
Then add in vCenter (and PSC/SSO), vSphere, Storage, and web client
Next we add replication (can be either or)
Lastly we add SRM, the SRM plugin and the SRA on top of that. The SRM architecture is now complete (see following notes)
vCenter – must be 6.0 and licensed and running on each site (this and the SRM server run at each site so that if one site is down/unavailable we can still perform recovery)
vSphere – must be 5 or later and running on each site
SRM Server – Requires a Windows 64 bit OS
Storage Replication – must be on our compatibility list, and have the snapshot or clone technology licensed for SRM tests
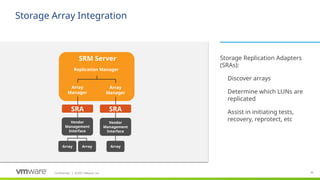
SRA – Storage Replication Adapter is the connection between VMware and the storage environment
VR Appliances – vSphere Replication Appliance
VRS – vSphere Replication Server (Optional for scale)
Key Points:
Site Recovery Manager is designed for virtual-to-virtual recovery for the VMware vSphere environment
Built for two-site scenario, but can protect bi-directionally. Can also protect multiple sites (N:1, 1:N and some other varients – see later in this deck for details)
No physical-to-virtual recovery today
Works with supported versions of vCenter Server, ESX, and ESXi. (Consult product documentation for specific versions that are supported/required).
Site Recovery Manager is tightly integrated with VMware vCenter Server
Site Recovery Manager integrates with third-party storage-based replication (also known as array-based replication) to move data to the remote site
Script:
Additional Notes:
The Site Recovery Manager service can be installed on the same server (or VM) as the vCenter management server. It can also be installed in a virtual machine.
Site Recovery Manager is not designed to be able to use 3rd party server-based or in-VM replication software.
Customers should work with their storage vendor to ensure that replication adapters for that system’s replication software are available. VMware publish a compatibility list for storage and replication on vmware.com. New support for FC, iSCSI and NFS arrays can be added by VMware and partners asynchronously without waiting for a new release of Site Recovery Manager since the adapters are plug-ins to Site Recovery Manager.
Current storage vendors who are currently working with VMware to provide replication adapters include over 95% of all deployments.
#57 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
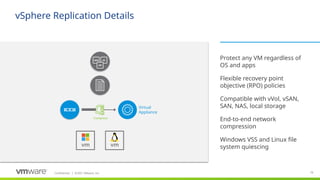
Protect any VM regardless of OS and apps
Flexible recovery point objective (RPO) policies
Compatible with vSAN, SAN, NAS, local storage
End-to-end network compression and encryption
Windows VSS and Linux file system quiescing
#58 Active-Passive: Site Recovery Manager absolutely supports the traditional active-passive DR scenario, where a production site running applications is recovered at a second site that is idle until failover is required. Although the most common configuration, this scenario also means that you are paying a lot of money for a DR site that is idle most of the time.
•Active-Active: To make better use of the recovery site, Site Recovery Manager also enables you to leverage your recovery site for other workloads when you aren’t using it for DR. Site Recovery Manager can be configured to automatically shutdown or suspend VMs at the recovery site as part of the failover process so that you can easily free up compute capacity for the workloads being recovered.
Bidirectional: Site Recovery Manager can also provide bidirectional failover protection so that you can run active production workloads at both sites and failover to the other site in either direction. The spare capacity at the other site will be used to run the VMs that are failed over.
#59 From 5.8 on Multi-site doesn’t have to be configured up front
5.8 on made it easier to see what’s going on with multiple sites
#60
One new topology introduced in SRM 6.1 – Stretched Storage
In the past there were Stretched cluster and SRM and it was really a choice between the two
The reason is a Stretched cluster requires single VC while SRM requires two VC instances, it’s a two VC concept
SRM now supports using Stretched Storage underneath SRM environment
With Stretched Storage – I’m talking about two active-active arrays on both sites provided by storage vendors with certain requirements for metro distance, low latency etc. depending by the Storage vendor
The biggest benefit – SRM now provides Zero downtime during planned migration from one site to another
It uses cross-VC vMotion technology to migrate the VMs without Power Off/Power On operation
And SRM can now non-disruptively test that
Before, if you’d wanted to test failover with Stretched Cluster, you had to take down one of your site and see what would happen
SRM lets you test this in an orchestration fashion – things will happen in the same order you defined. SRM will do vMotion compatibility checks for all VMs on the stretched devices.
SRM now combines the benefits of SRM with the advantages of Stretched Storage - to achieve what was previously only possible with Stretched Clusters
Planned maintenance and Disaster avoidance with Zero downtime
If some VMs, due any reason, are not eligible for cross-VC vMotion, SRM is still compatible and will use the old fashioned way to migrate the VMs with power Off and power ON to the other side.
For more information about SS and Stretched clusters integration with SRM, there is a really good BLOG available publicly online
=== more details ===============
Today customers who are looking for a disaster avoidance/recovery solution have to make a stark trade-off between two incompatible solutions: SRM or VMSC?
Benefits from SRM
Orchestrated DR
Management resiliency (VC at each site)
DR Testing
Traditional benefits of vMSC now available with SRM 6.1
Downtime avoidance – cross-site vMotion
Disaster avoidance – zero downtime (SRM could do DA but not zero downtime, though was orchestrated, vMSC is manual)
Automatic failover – w/SRM 6.1 Failover can be triggered by third system witness via SRM API
Requirements:
Stretched Storage solution
Storage clustering solution that supports distributed data mirroring
Read/write access to the same volumes from both sites
Some tie-break mechanism to avoid splitbrain
Examples: EMC VPLEX, IBM SVC, NetApp MetroCluster, etc.
Stretched Network solution
VMware NSX or 3rd party
Enables live migration of apps without changing IP addresses
Notes/Warnings:
This feature is only available when using SPPGs
Assumes VM IPs don’t change (can be changed if they are powered off, not for vMotion)
Recovery Plan testing doesn’t do anything with vMotion
Requires stretched storage and specific SRA (currently only IBM and EMC VPLEX)
Orchestrated vMotion is only used with Recovery Plan – Planned Migration mode
vMotion in planned migration mode can be overridden for individual VMs or for the recovery plan (if vMotion would take too long, etc)
Not all arrays/vendors will support Recovery Plan testing (don’t allow snapshots of stretched datastore)
#61 Ken
GS
VMware Site Recovery Manager and vSphere Replication are compatible with standard vSAN clusters and vSAN stretched clusters. vSphere Replication is configured on a per-VM basis with RPOs as low as five minutes. It is simple to deploy using virtual appliances at both the source and target locations for bidirectional VM protection. Recovering a VM with vSphere Replication is a matter of just a few mouse clicks for each VM. To automate and scale the disaster recovery solution, Site Recovery Manager – or SRM – can be layered on top of vSphere Replication.
SRM provides a number of orchestrated workflows including disaster recovery, planned migration, and recovery plan testing. SRM’s automation capabilities and scale make it possible to recover hundreds of virtual machines in just a few hours with the press of a button. Furthermore, since these are all VMware solutions, you only need to call one number to get support for the entire stack, if needed. This is especially beneficial in a high-stress, disaster recovery situation.
In this diagram we see a vSAN stretched cluster across two sites on the left side of the slide. A third site – the disaster recovery site – is located on the right side. Note that the vSAN Witness Host is deployed at the disaster recovery site. There are two virtual machines running SRM – one running on the vSAN stretched cluster and one running at the third site. A vCenter Server Virtual Appliance – or VCSA – is running on the stretched cluster and at the third site. These are not shown in the diagram for simplicity. There is also vSphere Replication virtual appliances running on the stretched cluster and at the third site. To scale vSphere Replication, you can run multiple vSphere Replication virtual appliances – up to 10 per vCenter Server environment.
Let’s take a closer look at vSphere Replication and SRM. We will then conclude with a demo that shows a vSAN stretched cluster, vSphere Replication, and SRM working together to minimize downtime when failures occur.
#63 Key Message/Talk track:
Assuming you have your
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
#64 Key Message/Talk track:
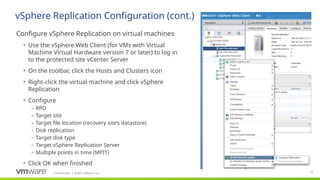
Installation/configuration Sequence:
Pair sites
Resource mappings
Networks
Folders (VMs & Templates)
Resources (Hosts & Clusters)
Storage policies (for SPPGs)
Placeholder datastores
Protection groups (technically used at protected site)
Recovery plans (technically used at recovery site) – consist of 1 or more PGs
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
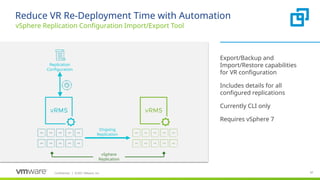
#67 Provides the capability to export and import the configuration for all replicated VMs. The details include the following for each replication - host folder information, compute resources, network and datastore information, datastore paths, RPO setting, multiple points in time (MPIT) setting, quiescing, network compression, encryption, etc.
Requirements/Limitations:
Currently CLI only. It is a separate download from the download page
Requires Java 1.8
Before you can export a configuration, you must have a site pair with vSphere Replication up and running on both the protected and the recovery site.
Import is supported in a clean vSphere Replication installation, registered to the same vCenter Server instance or to a vCenter Server instance which contains the same inventory.
#70 If using storage-based replication, integration with the arrays with vendor-specific replication and protection engines are a very fundamental. This integration is provided via code written by the array vendors themselves.
SRAs were advanced in SRM 5, improving the integration with array-replication software for functionality like reprotect/replication reversal and failback.
With SRM 5.1, the SRM process is now fully 64-bit. SRAs are rewritten and will require reinstallation and perhaps reconfiguration to be addressable by the new 64-bit process.
While SRM 5.5 and higher work with vSAN, there is no SRA. As such vSAN will work only with vSphere Replication.
#71 Key Message/Talk track:
SRM now supports VMs on vVols replicated with array-based replication (previously SRM only supported vVols with vSphere Replication).
----------------------------------
Overview:
vVols now supported with SRM
Initially only Pure, 3Par and Nimble
----------------------------------
Details:
----------------------------------
Additional Information:
----------------------------------
Internal:
https://confluence.eng.vmware.com/pages/viewpage.action?spaceKey=SRM&title=VVol+support
SRM now supports all storage supported by vSphere, local, block, file, vSAN and vVOL
Simplify DR orchestration for all of your datastores – VMFS, NFS vVols, vSAN and local
Easily extend VM protection to existing vVols replication policies
Use with any VASA 3.0 and vVols 2.0 array
Key Message/Talk track:
vSphere Virtual Volumes introduces the concept of Replication Groups bringing more efficient, accurate, and responsive recovery of your virtual machines. A Replication Group is a group of replicated storage devices as defined by a storage administrator (perhaps acting on behalf of an application owner) to provide atomic failover for an application. In other words, a Replication Group is the minimum unit of failover. In vSphere 6.5, Replication Groups are created and managed by a storage administrator using the storage vendor’s tools or created on the fly(if the array supports so called "automatic" RG group selection).
Replication Groups also define the set of vVols that are maintained in write-order fidelity where writes are replicated on the destination site in the exact same order they're generated at the source site to ensure at any time the destination site represents at least a crash-consistent version of the data on the source site.
Overview:
How it works:
Vendor specific replication capabilities are advertised up to vSphere via VASA
VI administrators create VM storage policies containing replication capabilities from the storage system
Details:
When VMs are being provisioned the user:
1. Selects a policy containing the replication capabilities
2. Chooses the compatible datastore
3. Chooses a replication group in which to place the VM (to support multi-VM consistency)
4. Completes the provisioning
#72 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
vSphere Replication is configured on a per-VM basis allowing fine control over which VMs are replicated. After the initial replication, only changes to the VM are replicated to minimize network bandwidth consumption. vSphere Replication is included with vSphere Essentials Plus Kit and higher editions, all editions of VSOM, and all editions of vCloud Suite.
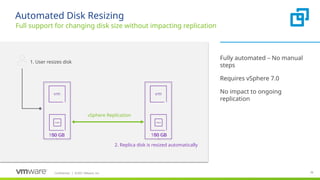
#79 Re-sizing virtual machine disk files that are protected by vSphere Replication (VR) is no longer a manual process.
If you replicate a VM with vSphere Replication, you can expand the source disk and vSphere Replication will detect the change and dynamically resize the destination.
No re-configuration of replication is needed or user intervention.
Limitations in VR 8.3
MPIT hierarchy will be lost. All available MPITs on the destination will be collapsed. But it will be possible after that to create new MPITs.
support for vSphere 7.0 only, and future releases of vSphere.
The problem –
VR requires disks at source and target to be the same size but there is no mechanism to extend the replica disks of a replication because we use redo-log chains to encode points in time and the platform does not support extending disks with a snapshot chain.
https://confluence.eng.vmware.com/pages/viewpage.action?spaceKey=Replication&title=Disk+Resize
#80 Improved steady state throughput
Improved VR initial sync
During initial sync what HBR does today is that even for newly configured replication, it compares the checksums, even though HMS just created an empty disk. This is inefficient as it performs lots of unnecessary read operations and if HBR can be "hinted" by HMS that this is brand new disk, HBR could skip the read operations and just transfer the replicated disk.
While trying to reproduce the issues, I've also found that we currently open 2 threads per NFC connection. There is only one NFC connection per host now but in environments with lots of hosts this becomes an issue because the threads are dedicated and can't be reused if idle so we should convert them to the same model as hostd (i.e. schedule completions instead of using a thread to wait for the NFC replies).
Upgrades supported from 8.1 or 8.2
#82 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
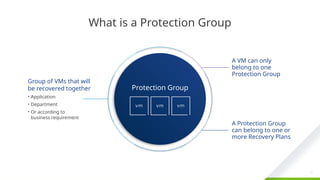
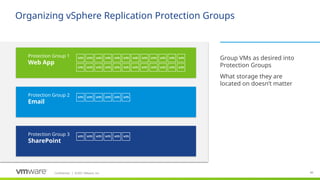
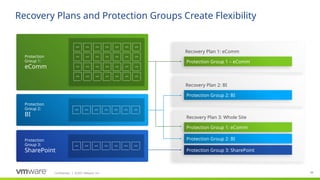
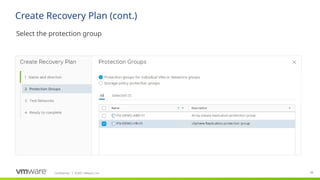
Protection groups are a way of grouping virtual machines that will be recovered together. In many cases, a protection group will consist of the virtual machines that support a service or application such as email or an accounting system. For example, an application might consist of a two-server database cluster, three application servers and four web servers. In most cases, it would not be beneficial to fail over part of this application, only two or three of the virtual machines in the example, so all nine virtual machines would be included in a single protection group.
Creating a protection group for each application or service has the benefit of selective testing. Having a protection group for each application enables non-disruptive, low risk testing of individual applications allowing application owners to non-disruptively test disaster recovery plans as needed.
A protection group contains virtual machines whose data has been replicated by either array-based replication or vSphere replication. Before a protection group can be created, replication must be configured. A protection group cannot contain virtual machines replicated by more than one replication solution (e.g. same virtual machine protected by both vSphere replication and array-based replication) and, a virtual machine can only belong to a single protection group.
#83 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
Recovery Plans are the runbook
Recovery Plan can contain VR & ABR PGs or SPPGs only
#84 GS
Ken
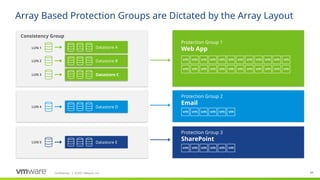
ABR PGs are based on storage. VMs that are located on a LUN or Consistency group have to be protected together.
It is not supported (or recommended) to have unprotected VMs on a replicated datastore as this can cause problems for SRM and the VM(s)
#85 GS
Ken
Introduced in SRM 6.1
Previously SRM required explicit management of contents of Protected Resources, including datastores and VMs
Management is primarily via UI
Limited management via API
This leads to operational overhead or complex orchestration configuration whenever we want to:
Protect/Unprotect VMs
Add/Remove datastores from Protection Groups
The existing operational overhead increases the cost to protect a VM.
Leveraging Storage Profiles to identify protected resources reduces costs by removing the SRM operations required to:
Protect/Unprotect VMs
Add/Remove datastores from protection groups
Configuration steps:
Create Tag catagory
Create Tag
Tag replicated storage
Create Storage Policy (tag based, using tag from previous)
Place VM on replicated storage and associate with SP
Customers managing at DR scale have been asking about automating the DR protection process using policies or integrations that step into VM creation workflow
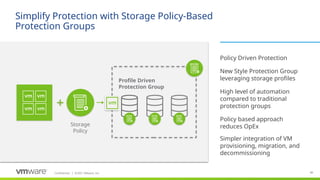
The idea is that there is likely a strong correlation between VMs being provisioned into higher tiers of storage and VMs that need DR protection. So a customer can tie these two policies together using this new construct called SPPG which allows SRM protection groups to associate directly with storage profiles. Any VMs getting provisioned onto corresponding datastores will be automatically added to SRM’s DR protection and recovery plans
SRM will automatically discover and protect all corresponding datastores
SRM will automatically discover and protect all associated VMs
SPPGs support only array based replication
Other new SRM 6.1 features require SPPGs
FAQ
Legacy VM-based protection groups are still fully supported
Recovery Plans can either contain SPPGs or VM and/or ABR PGs, not both (SPPGs have to be in a RP by themselves, VM & datastore PGs can be in the same RP)
No more placeholders
MoRef no longer the same
When a VM is associated with a storage profile, vCenter picks a datastore from the profile’s datastore set
Association is per-VM and per-disk
The user can override the datastore selection manually
vCenter can perform a compliance check to ensure that VMs are still stored on the correct datastores
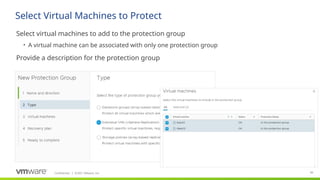
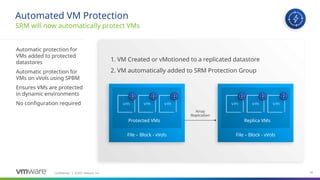
#91
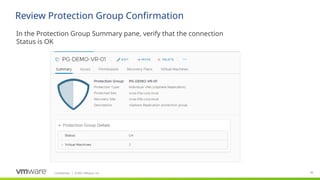
Site Recovery Manager supports the automatic protection of virtual machines deployed in datastores part of an array-based replication.
If you create a new virtual machine on a datastore that is replicated and protected in Site Recovery Manager, the virtual machine is automatically added to an existing protection group.
Site Recovery Manager applies automatic protection to new or existing virtual machines for which the SPBM policy is changed to a vVols policy for replication and to a Replication group protected with Site Recovery Manager.
Engineering confluence page: https://confluence.eng.vmware.com/display/SRM/Automatic+Protection+for+VMPGs
Automatic protection of VMs (part of array based replication or vVol Replication).
SCOPE
* New VMs deployed in datastores/LUNs part of array based replication, that are protected in SRM. If a new VM is created on a datastore, that is replicated and protected in SRM, VM will be auto-protected.
vVol - New or existing VMs, for which SPBM policy is changed and they are associated with vVol policy for replication and Replication groups that are protected in SRM. If I edit the Storage policy for the VM and associate it with Replication Group, that is already protected in SRM, VM will be auto protected.
Out of scope: *Auto – unprotection is not covered. It doesn’t work when a VM is deleted in vCenter – it is not auto-unprotected from SRM. SRM will display errors and the VM should be deleted from protection.
*vMotion is partially covered with array-based replication. If there are 2 datastores and they are in the same protection group, if I move a VM from one to another with vMotion, VM will be still auto-protected. If the 2 datastores are in different protection groups, and I move the VM from one to another, we go into the case of auto -unprotection and it doesn’t work.
* vSphere Replication is out of scope. VR replicates VMs from one datastore to another and there is no use-case for auto-protection and un-protection.
#94 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
Recovery Plans are the runbook
Recovery Plan can contain VR & ABR PGs or SPPGs only
#95 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
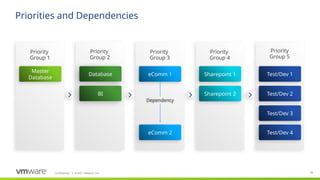
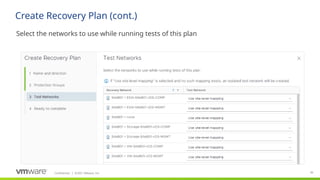
Build complex recovery matrices and interdependencies easily!
In this case, the start sequence is as follows:
Master Database
Database/Exchange in parallel
App Server 1 first, followed after successful startup by App Server 2 sequentially
Apache/Apache/Mail Sync in parallel
All desktops in parallel
#101 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
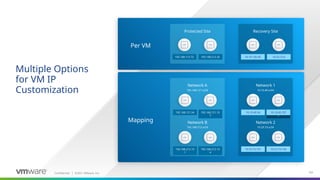
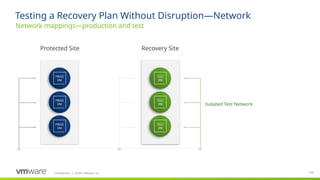
No need to manage IP address changes on an individual level anymore (though those options do remain if needed).
These can now be mapped from one subnet to another and applied at the Site>Network Mapping level.
There is the option of using both, eg. Subnet mapping for the subnet, and individual mapping for VMs within that subnet
Can configure DNS, gateway, etc
Note both sites can be configured – very important for doing regular failover/failback.
Limitations:
IPv4 only
#102 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
No need to manage IP address changes on an individual level anymore (though those options do remain if needed).
These can now be mapped from one subnet to another and applied at the Site>Network Mapping level.
There is the option of using both, eg. Subnet mapping for the subnet, and individual mapping for VMs within that subnet
Can configure DNS, gateway, etc
Note both sites can be configured – very important for doing regular failover/failback.
Limitations:
IPv4 only
#103 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
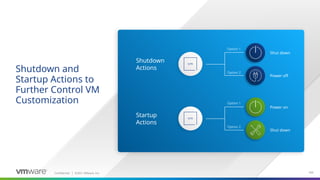
Shutdown actions are not used for Test workflow as VMs are not powered off for that workflow
#104 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
Shutdown actions are not used for Test workflow as VMs are not powered off for that workflow
#105 What languages are supported on the appliance? - Native scripting languages in the SRM appliance are Perl, Python and bash.
#107 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
No ability to run scripts from SRM server
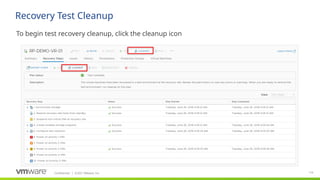
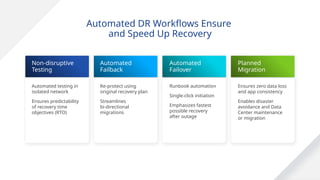
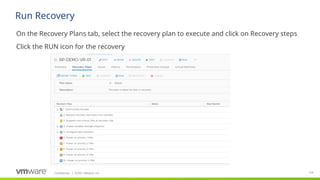
#120 Site Recovery Manager automates every aspect of executing a recovery plan, including testing, failover to the secondary site and failback to the production site, in order to accelerate recovery and eliminate the risks involved with manual processes.
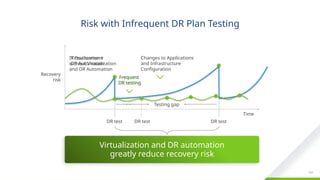
Non-disruptive testing
With traditional DR, organizations often do not have much confidence that they will be able to meet their RTO objectives. This is mostly due to the ‘testing gap’ and configuration drift. Tests are typically only conducted once or twice a year, at great organizational cost, and between the tests organizations have very little visibility into their ability to meet the business requirements.
Non-disruptive testing enables organizations to test as frequently as desired, whenever is convenient. Frequent testing provides organizations with great confidence that RTOs will be met. Any issues in recovery plans can be identified quickly and remediated.
Automated failover
With SRM, all you do is press the recovery button and recovery begins. Although SRM will provide notification when it loses contact with the primary site, it is important to note that you do need to hit the button. Your DR team declares that a disaster requiring recovery at the recovery site has occurred, and then Site Recovery Manager can begin executing the recovery process.
During automated failover, SRM does the following:
Stops replication at the primary site
Shuts down or suspends any VM’s that you designated earlier as low priority at the recovery site
Promotes the replicated copy of storage and attaches it to the ESX Servers at the recovery site
Powers on virtual machines and changes IP addresses
Generates reports about recovery process
Automated failback
Automated failback enables bi-directional migrations, so that VMs can automatically be migrated back to their original site with minimal user intervention. This is particularly useful to streamline frequent back-and-forth migrations between two sites.
Automated failback consists of two steps. First, applications are ‘re-protected’ from the failover site to the original site by reversing replication. SRM automatically coordinates replication activities with the storage-array so that the user is shielded from manually having to initiate the reversal of replication.
Second, SRM executes the original recovery plan in reverse direction. This eliminates the need to create a brand new recovery plan for failback.
#121 Parallel and cutover tests provide the best verification, but very resource intensive and time consuming.
Cutover tests are disruptive, may take days to complete and leaves the business at risk
Test often! SRM offers completely non-intrusive testing. The more often you test the better as you will have more reliable DR with less configuration drift between tests
Multiple options when it comes to testing
Normal SRM RP test
Actual run
#124 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
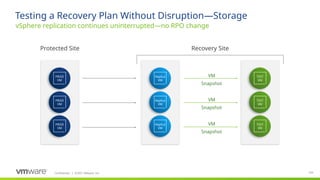
Notice that during a recovery plan execution, replication is interrupted. The mirror image, or replication destination datastore, is now promoted and made read/write. The virtual machines in it are registerd in vCenter in place of the shadow VM placeholders.
Important note – a number of vendors will do an automatic reversal of replication automatically at this point – sometimes without warning!
#125 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
Failback combines recovery plans and reprotect.
“Failback” is the capability of running a recovery plan *after* an environment has been migrated or failed-over to a recovery site, to return the environment back to its starting site.
After a failover has occurred, the environment can be reprotected back to the original environment once it is again safe. Following this reprotect the recovery plan can be run once more, moving the environment back to its initial primary site.
Next it is imperative to reprotect once more, to ensure the environment is once again protected and ready to failover.
With SRM 5 VMware introduced the “Reprotect” and failback workflows that allowed storage replication to be automatically reversed, protection of VMs to be automatically configured from the “failed over” site back to the “primary site” and thereby allowing a failover to be run that moved the environment back to the original site.
After running a *planned failover only*, the SRM user can now reprotect back to the primary environment:
Planned failover shuts down production VMs at the protected site cleanly, and disables their use via GUI. This ensures the VM is a static object and not powered on or running, which is why we have the requirement for planned migration to fully automate the process.
The “Reprotect” button when used with VR will now issue a request to the VR Appliance (VRMS in SRM 5.0 terminology) to configure replication in opposite direction.
When this takes place, VR will reuse the same settings that were configured for initial replication from the primary site (RPO, which directory, quiescence values, etc.) and will use the old production VMDK as seed target automatically.
VR now begins to replicate replicate back to the primary disk file originally used as the production VM before failover.
If things have gone wrong at the primary site and an automatic reprotect is not possible due to missing or bad data at the original site, VR can be manually configured, and when the “Reprotect” is issued SRM will automatically use the manually configured VR settings to update the protection group.
Once the reprotect is complete a failback is simply the process of running the recovery plan that was used to failover initially.
#126 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
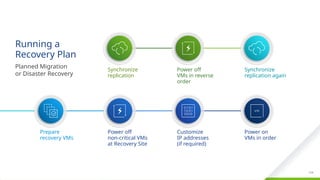
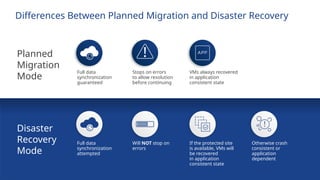
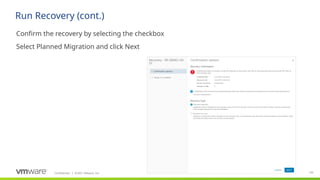
The difference between a Planned Migration and a Disaster Recovery is that a Planned Migration will automatically stop on errors and allow the administrator to fix the problem.
A Planned Migration is designed to ensure maximum consistency of data and availability of the environment.
A DR scenario is instead designed to return the environment to operation as rapidly as possible, regardless of errors.
#133 Failback combines recovery plans and reprotect. It is ability to run a recovery plan after an environment is migrated or failed over to a recovery site and return the environment back to its starting site.
After a failover has occurred, the environment can be reprotected back to the original environment after it is safe again. Following this reprotect, the recovery plan can be run once more, moving the environment back to its initial primary site. Then, it is imperative to reprotect again so that the environment is again protected and ready to fail over.
#134 Reprotect and failback workflows allow storage replication to be automatically reversed and protection of virtual machines to be automatically configured from the “failed over” site back to the “primary site,” thereby moving the environment back to the original site.
Users can perform automated reprotects and run failback workflows for recovery plans with any type of protection group, including vSphere Replication and array-based replication (ABR).
After running a planned failover only, the Site Recovery Manager user can reprotect back to the primary environment:
Planned failover shuts down production virtual machines at the protected site cleanly and disables their use through the graphical user interface. Thus, the virtual machine is a static object and not powered on or running. This is the reason that there is the requirement for planned migration to fully automate the process. The Reprotect button, when used with vSphere Replication, now issues a request to the vSphere Replication Appliance to configure replication in the opposite direction.
When this takes place, vSphere Replication reuses the same settings that were configured for initial replication from the primary site (RPO, directory location, quiescence values, and the like) and uses the old production VMDK as a seed target automatically.
vSphere Replication begins to replicate back to the primary disk file originally used as the production virtual machine before failover.
If things have gone wrong at the primary site and an automatic reprotect is not possible due to missing or bad data at the original site, vSphere Replication can be manually configured. When the reprotect is issued, Site Recovery Manager automatically uses the manually-configured vSphere Replication settings to update the protection group.
After the reprotect is complete, a failback is simply the process of running the recovery plan that was used to fail over initially.
#135 A failback is the process of running the same recovery plan that was used to migrate the environment to the recovery site initially.
Users might “mix-and-match” the modes in which a recovery plan is run. For example, an initial crisis may have dictated that an environment be failed over in disaster recovery mode. After the risk to the primary site is fixed, the user might have reprotected the environment, reversing direction and replicating the virtual machines back to the primary site. When change management allowed for a failback, the same recovery plan might have been run again, although this time (because the direction of replication is reversed), the recovery plan moves the virtual machines in the protection group back to the primary site. In this scenario, the recovery plan for failback might have been run as a planned migration, making certain there is data consistency and availability of all applications, rather than as a disaster recovery designed for rapid recovery.
Planned migration and failback in no way eliminate the need to do extensive testing of recovery plans. Even after a successful failover, there is no guarantee that the reprotect and failback will be as successful because the environment at the original site might have changed. It is important to test the failback process, just as it was important to test the original failover.
#137 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
You can see history reports here for an individual recovery plan
Test, Cleanup, Reprotect, and Failover operations are listed and detailed in the history report.
Individual reports, or the entire list, may be exported from the
#138 Key Message/Talk track:
----------------------------------
Overview:
•
----------------------------------
Details:
•
----------------------------------
Internal:
•
History reports now include “Started By” information, as well as information about storage synchronization.
user interface.
#146
In-place upgrade of Site Recovery Manager:
The simplest upgrade path. This path involves upgrading the Platform Services Controller and vCenter Server instances associated with Site Recovery Manager before upgrading Site Recovery Manager Server. Run the new version of the Site Recovery Manager installer on the existing Site Recovery Manager Server host machine, connecting to the existing database.
Upgrade Site Recovery Manager with migration:
This path involves upgrading the Platform Services Controller and vCenter Server instances associated with Site Recovery Manager before upgrading Site Recovery Manager Server. To migrate Site Recovery Manager to a different host or virtual machine as part of the Site Recovery Manager upgrade, stop the existing Site Recovery Manager Server. Do not uninstall the previous release of Site Recovery Manager Server and make sure that you retain the database contents. Run the new version of the Site Recovery Manager installer on the new host or virtual machine, connecting to the existing Platform Services Controller and database.
#147 Important
Upgrading from Site Recovery Manager 6.0.x to Site Recovery Manager 8.1 is not supported. Upgrade Site Recovery Manager to a Site Recovery Manager 6.1.x release before you upgrade to Site Recovery Manager 8.1. See Upgrading Site Recovery Manager in the Site Recovery Manager 6.1 documentation for information about upgrading to 6.1.x.
If you use vSphere Replication with Site Recovery Manager 6.0.x, and you upgrade vSphere Replication from version 6.0.x to version 6.5 directly, when you attempt the interim upgrade of Site Recovery Manager from version 6.0.x to version 6.1.x, the Site Recovery Manager upgrade fails with an error because of an incompatible version of vSphere Replication. Upgrade vSphere Replication to version 6.1.x before you upgrade Site Recovery Manager from 6.0.x to 6.1.x.