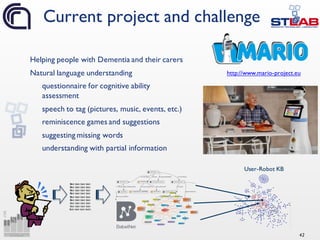
Downloaded 15 times













![14
Minsky [1]
“When one encounters a new situation
[…] one selects from memory a
structure called a Frame. This is a
remembered framework to be adapted
to fit reality by changing details as
necessary.”
“A frame is a data-structure for
representing a stereotyped situation,
like being in a certain kind of living room,
or going to a child's birthday party”
“We can think of a frame as a network
of nodes and relations.”
“Collections of related frames are
linked together into frame-systems”
Fillmore [2]
“[…] in characterising a language system
we must add to the description of grammar
and lexicon a description of the
cognitive and interactional
“frames” […]”
“The evolution toward language must have
consisted in part in the gradual acquisition
of a reportory of frames and of
mental processes for operating with them,
and eventually the capacity to create new
frames and to transmit them.”
“[…] in order to perceive something or to
attain a concept, what is […] necessary is
to have in memory a repertoire of
prototypes. The act of perception or
conception being that of recognizing in
what ways an object can be seens as an
instance of one or another of these
prototypes.”](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-14-320.jpg)

![18
From entity-centric to
frame-centric design and
extraction
Before:
Key terms à
classes/properties
After:
Key situationsà
frames/patterns
Frames as units of meaning [3]](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-18-320.jpg)




![25
This is useful, but it’s not enough
Semantic heterogeneity
Lack of knowledge boundaries
(context) [3]
marriedWith
firstMarriageWith
spousemarriage
spousedate](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-25-320.jpg)
![26
The role of frames in knowledge representation, extraction and
interaction
Performingempirical observations on the web (in line with van
Harmelen’s [4])
Using frames for driving the design of solutions to research
problems andtest their performance
Frames as units of meaning](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-26-320.jpg)

![28
Frame-based knowledge extraction [5]
http://wit.istc.cnr.it/stlab-tools/fred/
From text to linked data](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-28-320.jpg)
![31
Automatic selection of relevant binary projections of frames
Usable label generation
Formal alignmentbetween frames and binary properties
Binary relations [6]](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-31-320.jpg)
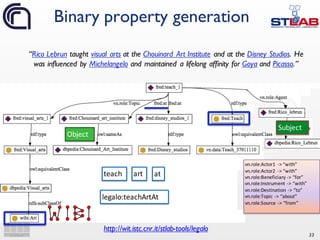
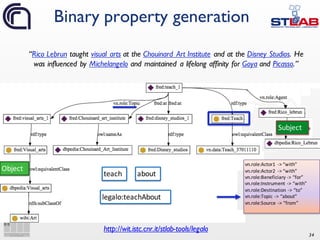
![35
Semantic Web triples and
properties generation
“Rico Lebrun taught visual arts at the
Chouinard Art Institute and at the Disney
Studios. He was influenced by Michelangelo
and maintained a lifelong affinity for Goya
and Picasso.”
dbpedia:Rico_Lebrun s:teachAbout dbpedia:Visual_arts .
s:teachAbout a owl:ObjectProperty ;
rdfs:subPropertyOf fred:Teach;
rdfs:domain wibi:Artist ;
rdfs:range wibi:Art ;
grounding:definedFromFormalRepresentation
fred-graph:a6705cedbf9b53d10bbcdedaa3be9791da0a9e94 ;
grounding:derivedFromLinguisticEvidence s:linguisticEvidence ;
owl:propertyChainAxiom([ owl:inverseOf s:AgentTeach ] s:TopicTeach) .
_:b2 a alignment:Cell ;
alignment:entity1 s:teachAbout ;
alignment:entity2 <http://purl.org/vocab/aiiso/schema#teaches> ;
alignment:measure "0.846"^xsd:float ;
alignment:relation "equivalence" .
domain, range, subsumption
linguistic and formal scope
alignment to existing LOD vocabularies](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-35-320.jpg)
![36
Evaluation tasks [7]
3
6
Tool/Task Topics NER NE-RS TE TE-RS Senses Taxo Rel Roles Events Frames
+SRL
AIDA
– + + – – + – – – – –
Alchemy
+ + – + – + – + – – –
Apache Stanbol
– + + – – + – – – – –
CiceroLite
– + + + + + – + + + +
DB Spotlight
– + + – – + – – – – –
FOX
+ + + + + + – – – – –
FRED
– + + + + + + + + + +
NERD
– + + – – + – – – – –
Ollie – – – – – – – + – – –
Open Calais
+ + – – – + – – – + –
PoolParty KD
+ – – – – – – – – – –
ReVerb
– – – – – – – + – – –
Semiosearch
– – + – + – – – – – –
Tagme – + + + + – – – – – –
Wikimeta
– + – + + + – – – – –
Zemanta
– + – – – + – – – – –](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-36-320.jpg)
![37
Topic detection and Opinion holder detection [8]
Sentiment propagation through frames and roles [9]
Sentiment analysis
“People hope that the President will be
condemned by the judges”](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-37-320.jpg)

![39
Frame-basedlinked data shows an effective representation of
discourse
Our ultimate goal is machine understanding, hence
an important issue is the limited coverage of existing resources
and their integration with factual world knowledge
FrameBase [10] partially addresses this problem, starting from
similar principles and intuitions
STLab has develop Framester [11,12]: a general web-scale
integrated resource which integrateslinguistic and world factual
knowledge
(see Aldo’s presentation later)
Coverage and integration of
linguistic and world knowledge](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-39-320.jpg)


![45
References
[1] Marvin Minsky: A Framework for Representing Knowledge. MIT-AI
Laboratory Memo 306, June, 1974.
[2] Charles J Fillmore. Frame Semantics and the Nature of Language. Annals of
the New York Academy of Sciences, 280(1):20-32, 1976.
[3] Aldo Gangemi, Valentina Presutti: Towards a pattern science for the Semantic
Web. Semantic Web 1(1-2): 61-68 (2010)
[4] Frank van Harmelen: The Web of Data: do we understand what we build?
https://sssw.org/2016/?page_id=386
[5] Aldo Gangemi, Valentina Presutti, Diego Reforgiato Recupero, Andrea
Giovanni Nuzzolese, Francesco Draicchio, Misael Mongiovì: Semantic Web
Machine Reading with FRED. Semantic Web (To appear)
[6] Valentina Presutti, Andrea Giovanni Nuzzolese, Sergio Consoli, Aldo
Gangemi, Diego Regorgiato Recupero: From hyperlinks to Semantic Web
properties using Open Knowledge Extraction pp. 351-378, Semantic Web,
Volume 7, Number 4 / 2016.](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-45-320.jpg)
![46
[7] Aldo Gangemi: A Comparison of Knowledge Extraction Tools for the
Semantic Web. ESWC 2013: 351-366
[8] Aldo Gangemi, Valentina Presutti, Diego Reforgiato Recupero:
Frame-Based Detection of Opinion Holders and Topics: A Model and a
Tool. IEEE Comp. Int. Mag. 9(1): 20-30 (2014)
[9] Diego Reforgiato Recupero, Valentina Presutti, Sergio Consoli, Aldo
Gangemi, Andrea Giovanni Nuzzolese: Sentilo: Frame-Based Sentiment
Analysis. Cognitive Computation 7(2): 211-225 (2015)
[10] Jacobo Rouces, Gerard de Melo, and Katja Hose. Framebase: Representing
n-ary relations using semantic frames. ESWC 2015: 505-521
[11] Aldo Gangemi, Mehwish Alam, Valentina Presutti, Luigi Asprino and Diego
Reforgiato Recupero: Framester: A Wide Coverage Linguistic Linked Data Hub.
In Proceedings of EKAW 2016
[12] Aldo Gangemi, Mehwish Alam, Valentina Presutti: Word Frame
Disambiguation: Evaluating Linguistic Linked Data on Frame Detection.
LD4IE@ISWC 2016: 23-31
References cont.](https://image.slidesharecdn.com/ld4ieiswc2016-161018000125/85/Knowledge-Extraction-and-Linked-Data-Playing-with-Frames-46-320.jpg)

This document summarizes Valentina Presutti's presentation on using frames for knowledge extraction and linked data. It discusses how frames can be used as units of meaning to reconcile knowledge from different sources. It provides background on frames and examples of how they can represent situations and relationships described in text. The document then outlines several projects from STLab that use a frame-based approach for tasks like knowledge extraction, relation extraction, and sentiment analysis. It discusses tools like FRED and Framester that perform frame-based knowledge extraction and integrate linguistic and factual knowledge through linked data.





















































