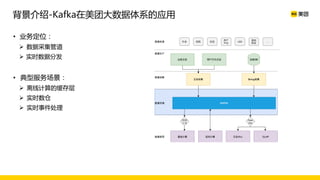
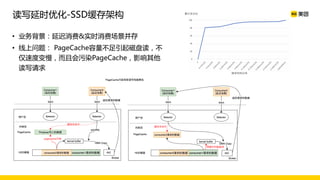
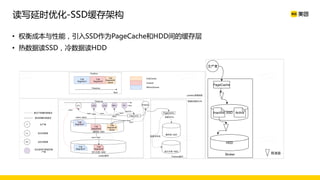
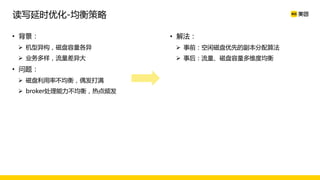
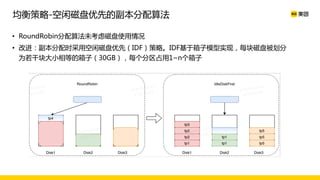
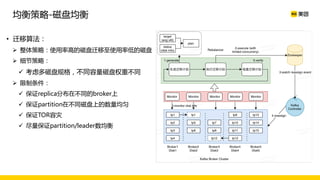
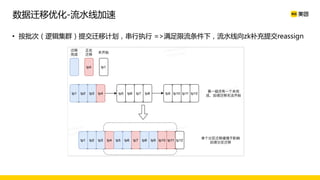
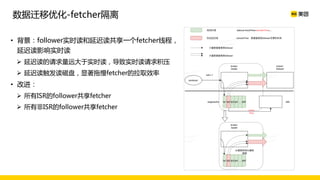
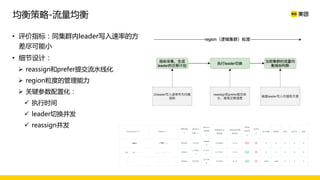
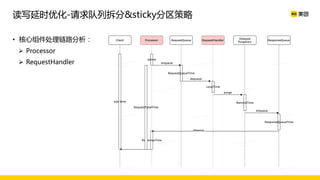
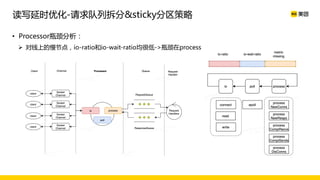
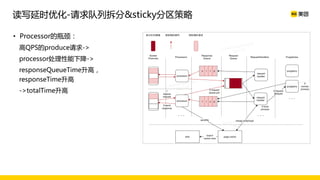
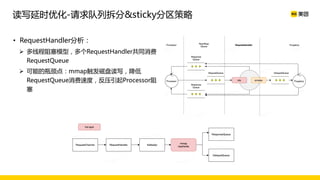
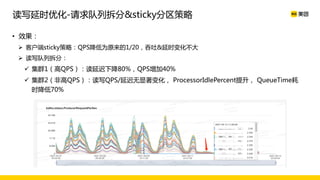
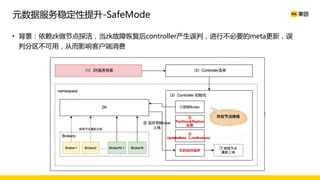
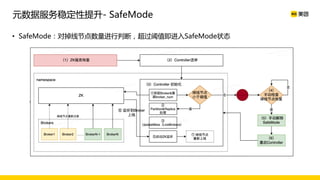
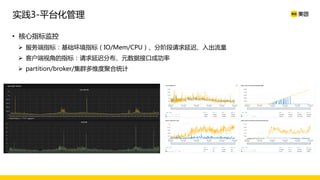
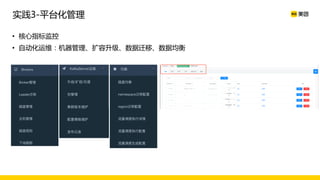
美团数据平台以Kafka为核心,进行数据采集及实时处理的应用与优化,涵盖读写延时优化、元数据服务稳定性提升及平台化管理等实践。优化措施包括使用SSD作为缓存、改进副本分配策略与请求队列拆分,有效提高读写性能和系统稳定性。后续规划聚焦于自动化运维和系统扩展能力的发展。










































![[GKE & Spanner 勉強会] Cloud Spanner の技術概要](https://cdn.slidesharecdn.com/ss_thumbnails/gke02-200121091040-thumbnail.jpg?width=640&height=640&fit=bounds)




















