Downloaded 251 times





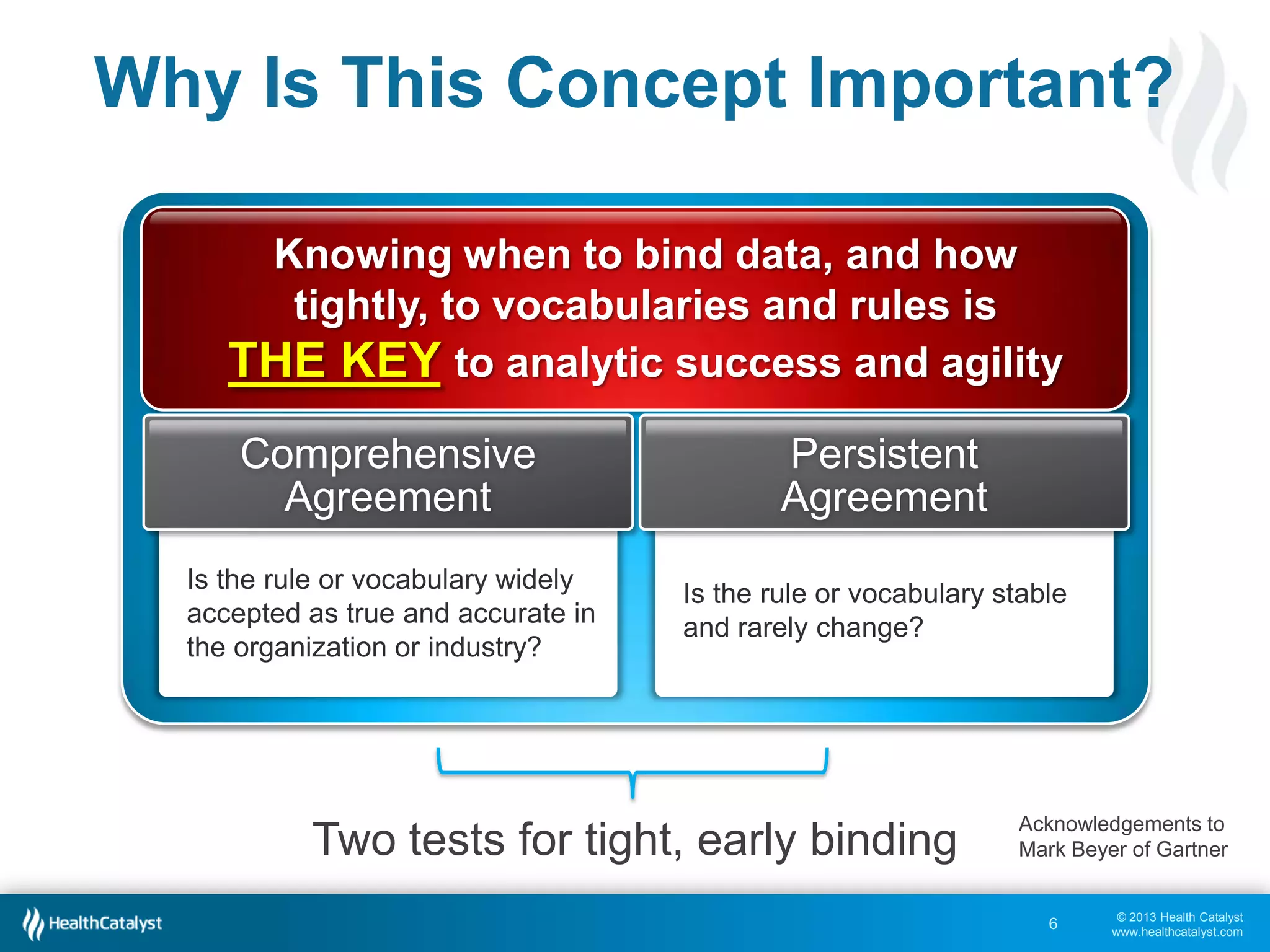
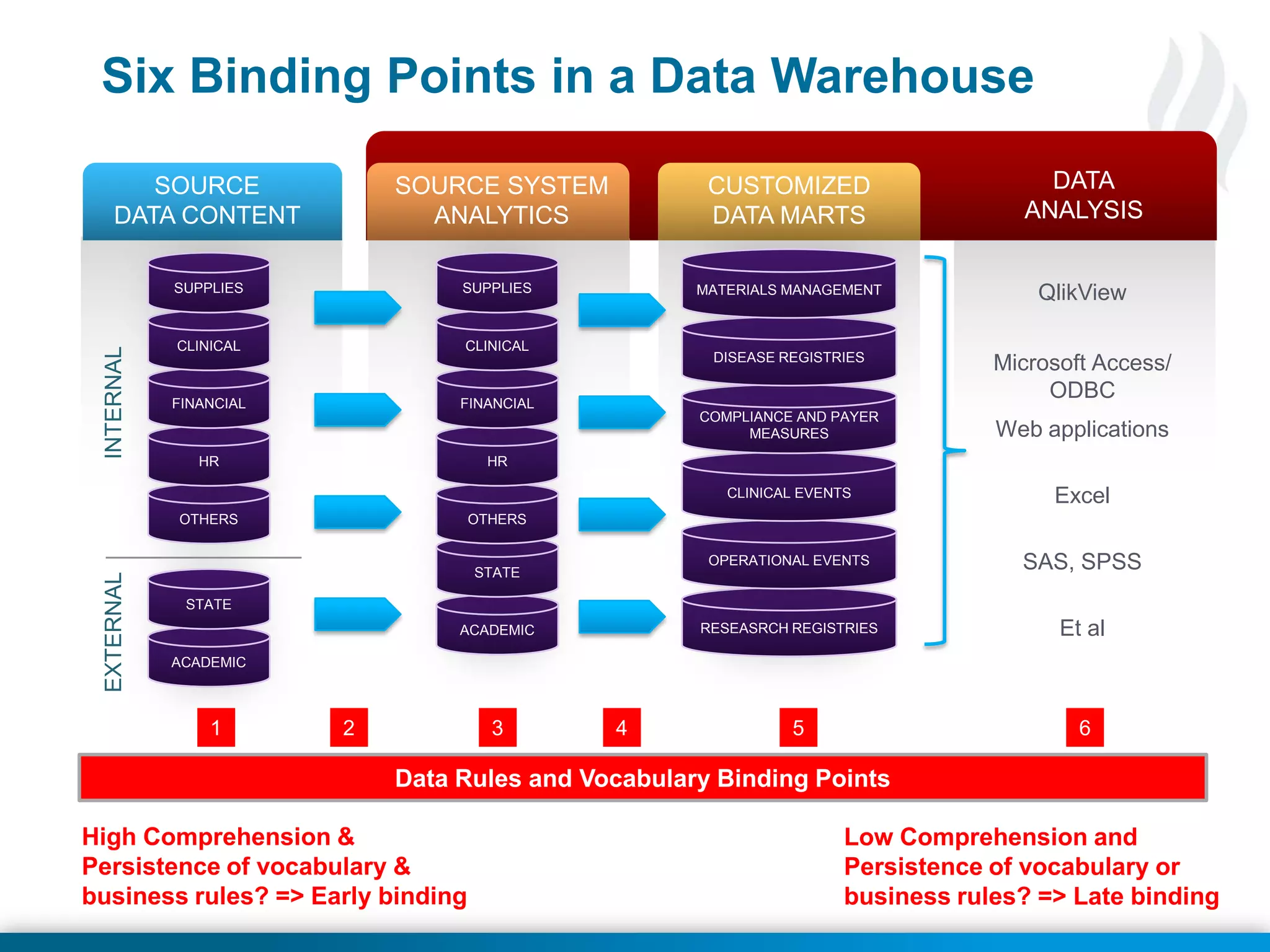

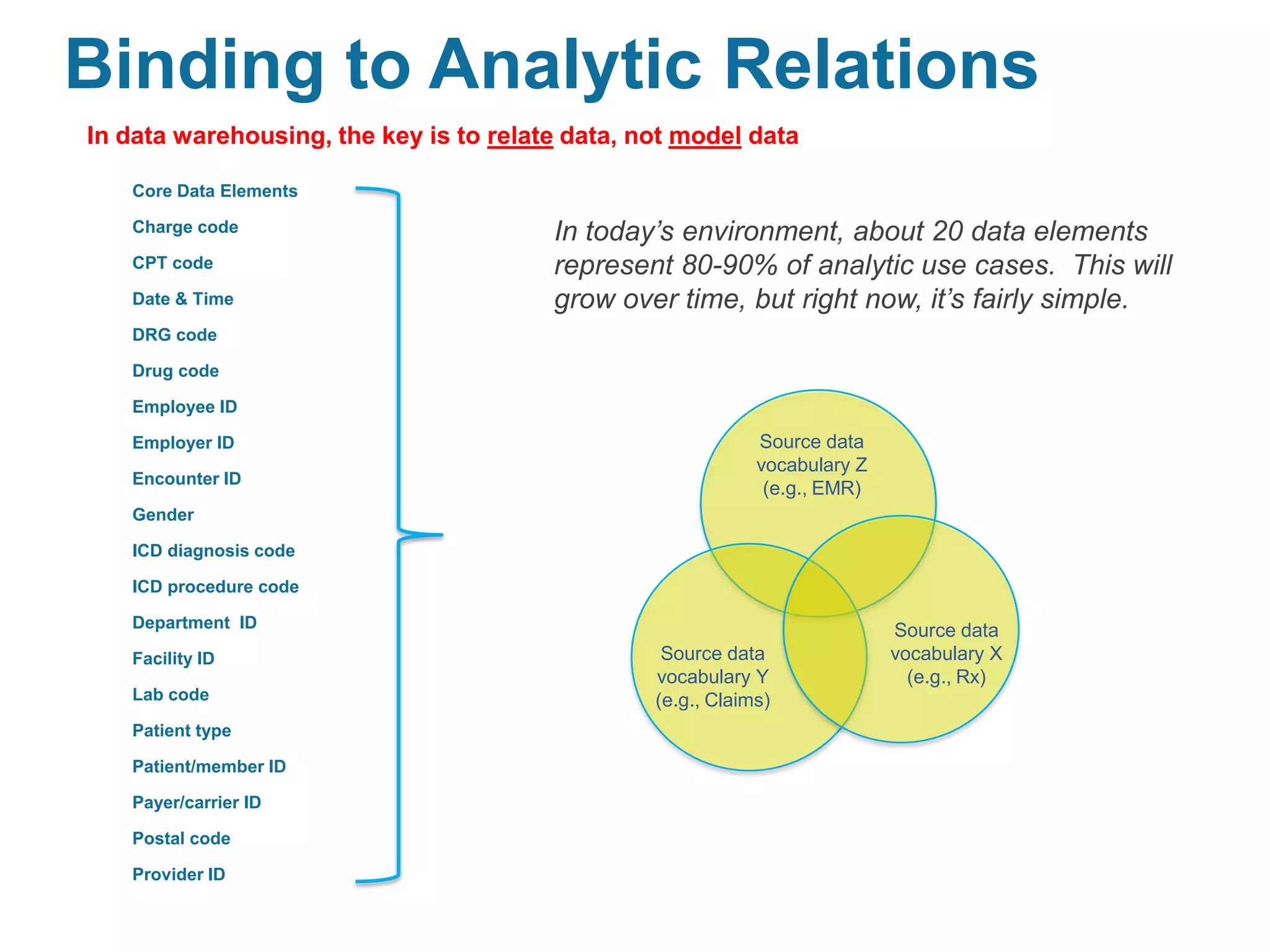
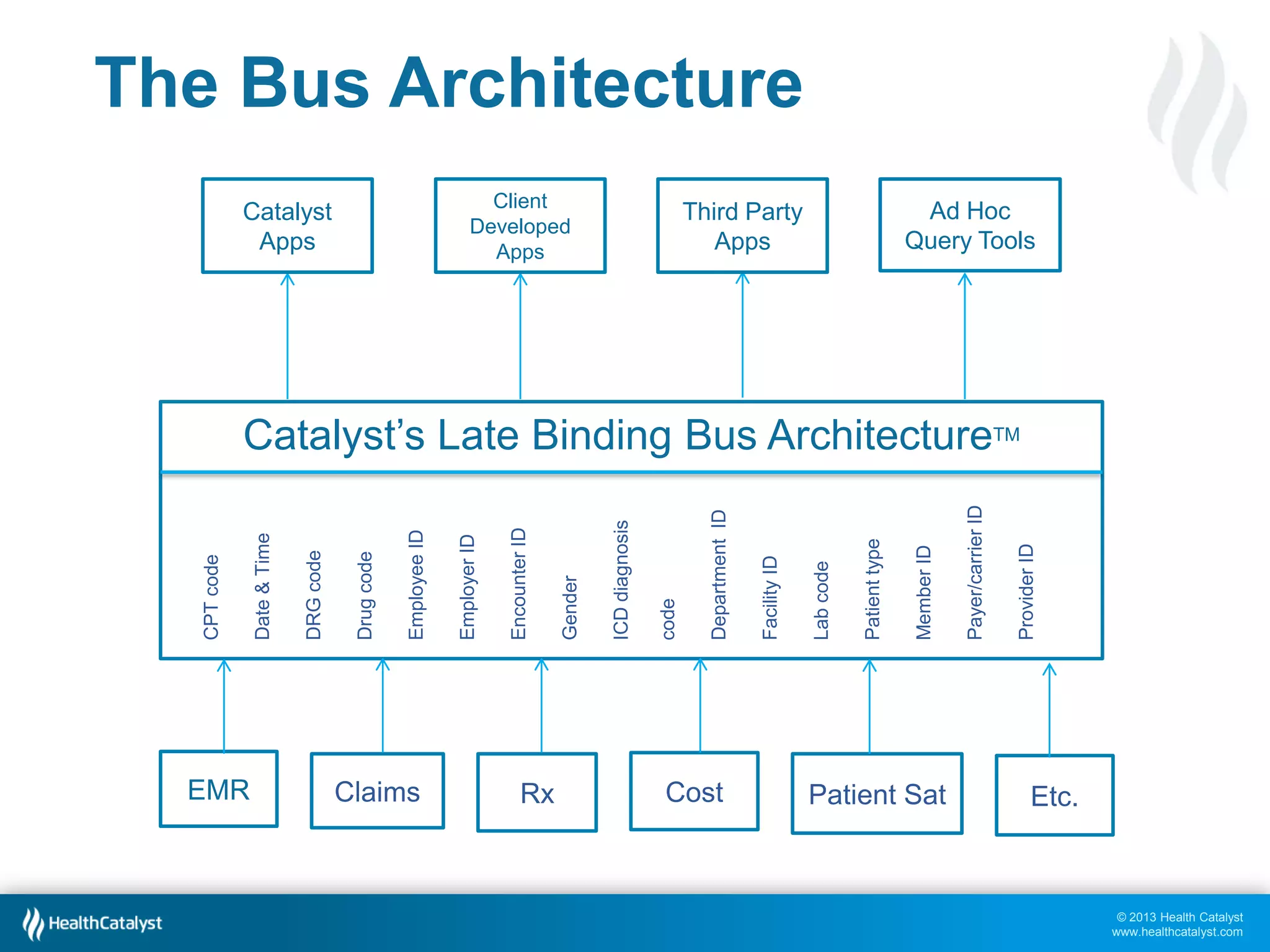


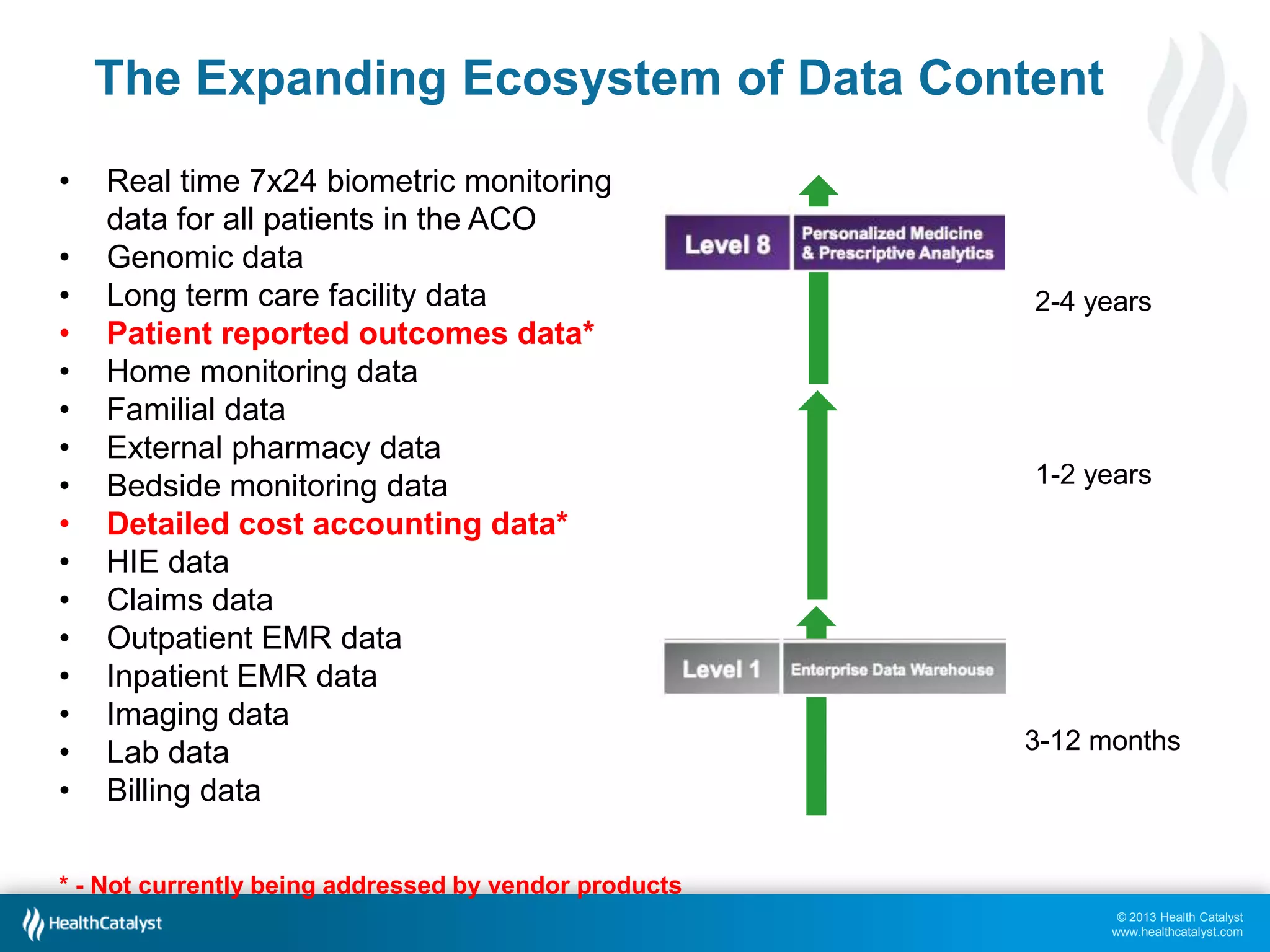
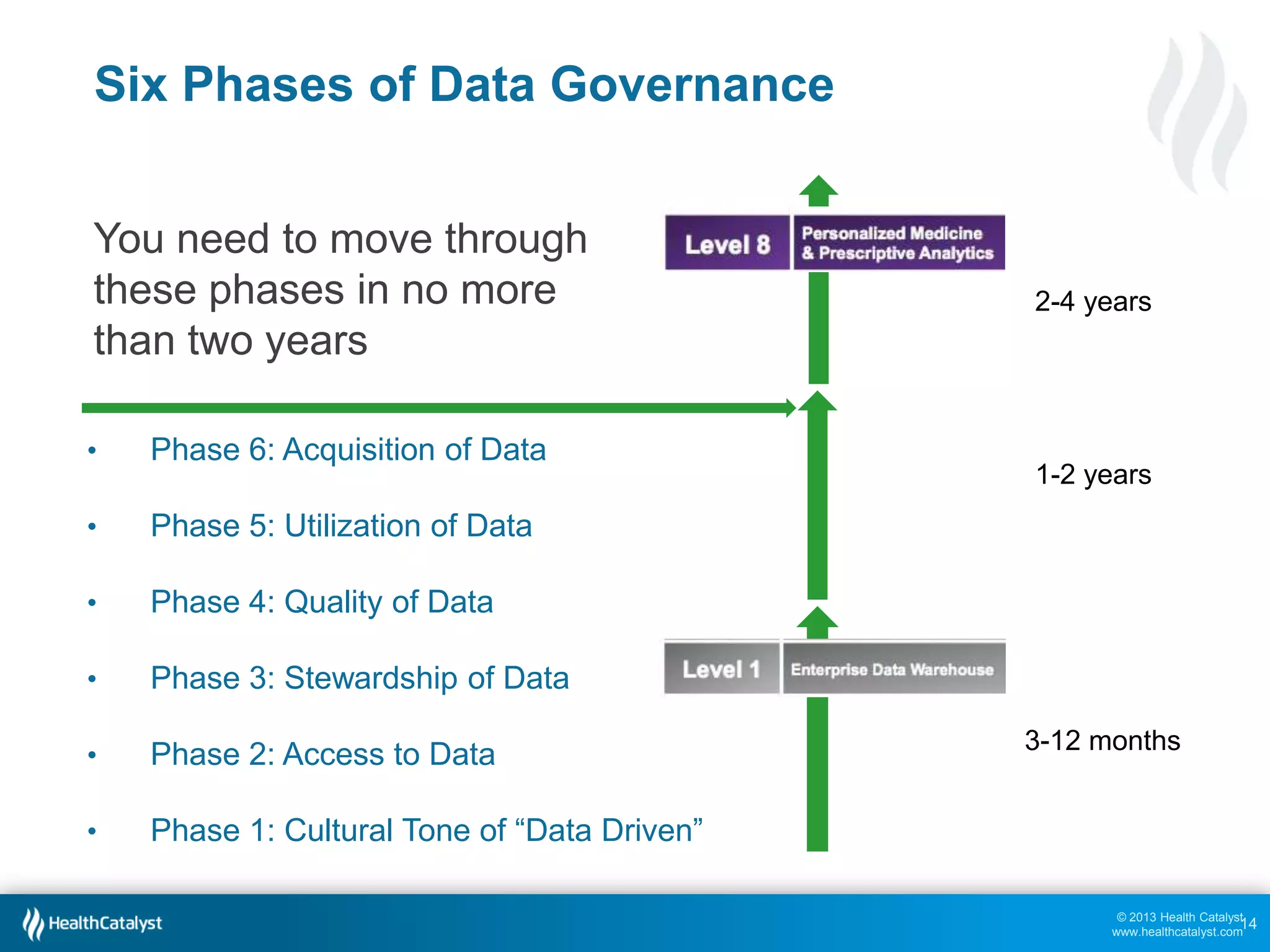




This document discusses late binding in data warehousing and its importance for analytic agility. Late binding means delaying the binding of data to rules and vocabularies for as long as possible. This allows data to be used flexibly for different analyses without being rigidly structured early on. It also discusses the progression of analytic sophistication in healthcare and how late binding is needed to support more advanced predictive and prescriptive analytics. Maintaining a record of changes to data bindings over time helps enable retracing of analytic steps. While early binding may be suitable when rules/vocabularies are stable, late binding is generally preferable to maximize flexibility and adaptability for analytics.












![[Cloud OnAir] BigQuery で実現する Smart Analytics Platform 2019年10月24日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1024-191024090721-thumbnail.jpg?width=640&height=640&fit=bounds)








































































