Dokumen tersebut membahas tentang algoritma perceptron untuk klasifikasi pola dengan tiga bagian utama yaitu arsitektur perceptron sederhana, algoritmanya, dan contoh aplikasinya untuk fungsi logika AND.
Kelompok:
- Bunga AmeliaRestuputri
115060800111114
- Anis Maulida Dyah Ayu Putri
115060801111087
- Inten Widi P
115060800111001
- Regita Ayu P
115060800111028
2.3 Perceptron
Aturan pembelajaran perceptron adalah aturan belajar yang lebih kuat daripada aturan
Hebb. Biasanya, perceptrons asli memiliki tiga lapisan neuron sensorik unit, Unit associator
membentuk model perkiraan retina. Percepteron sederhana yang digunakan aktivasi biner
untuk unit sensorik dan associator dan aktivasi +1,0, atau -1 untuk unit respon. Sinyal yang
dikirim dari unit associator ke unit keluaran adalah biner (0 atau 1) sinyal. Output dari
perceptron adalah y = f(y_in), dimana fungsi aktivasi adalah
Bobot dari unit associator ke unit respon yang disesuaikan dengan aturan belajar
percepteron. Jaringan akan menghitung respon dari unit output. Jaringan akan menentukan
apakah kesalahan terjadi untuk pola ini. Jaringan tidak membedakan antara kesalahan di
mana output dihitung adalah nol dan target -1, sebagai kebalikan dari kesalahan di mana
output dihitung adalah +1 dan target -1. Dalam kedua kasus ini, tanda kesalahan
menunjukkan bahwa bobot harus diubah ke arah yang ditunjukkan oleh nilai target. Jika
kesalahan terjadi untuk pola input pelatihan tertentu, bobot akan berubah sesuai dengan
rumus:
Dimana t nilai target adalah +1 atau -1 dan α adalah tingkat pembelajaran. Jika kesalahan
tidak accur, bobot tidak akan berubah.
2.3.1 Architecture
Simple Perceptron for pattern classification
Sebagai bukti dari aturan pembelajaran perceptron konvergensi teorema diberikan dalam
bagian 2.3.4 menggambarkan, asumsi input biner tidak diperlukan. Karena hanya bobot dari
unit associator ke unit keluaran dapat disesuaikan, kami membatasi pertimbangan kami ke
jaringan, ditunjukkan pada Gambar 2.14.
2.
2.3.2 Algorithm
Algoritma yangdiberikan di sini adalah cocok untuk vektor masukan baik biner atau bipolar,
dengan target bipolar, θ tetap, dan bias disesuaikan. Peran ambang dibahas
mengikutipresentasi dari algoritma. Algoritma ini tidak terlalu sensistive dengan nilai-nilai
awal bobot atau nilai dari nilai learning.
Ambang batas pada fungsi aktivasi untuk unit respon adalah tetap, non nilai negatif θ.
Bentuk fungsi aktivasi untuk unit keluaran adalah sedemikian rupa sehingga ada keragu raguan memisahkan wilayah respon positif dari yang respon negatif.
Perhatikan bahwa disini terdapat satu baris memisahkan, kami memiliki garis yang
memisahkan wilayah respon positif dari wilayah nol respon
Dan garis yang memisahkan wilayah respon negatif dari wilayah nol respon
2.3.3 Aplication
Logic Function
Contoh pada 2.11 perceptron for And function: binary input, dan bipolar target
Pada data training seperti contoh pada 2.6 pada aturan Hebb. Kita mengambil α = 1 dan
mengatur bobot awal dan bias 0. Sementara itu, menggambarkan peran dari ambang batas,
kita menggunakan θ = 2, bobot yang berubah adalah Δw = t(x1,x2, 1) jika error terjadi dan
bernilai 0, maka
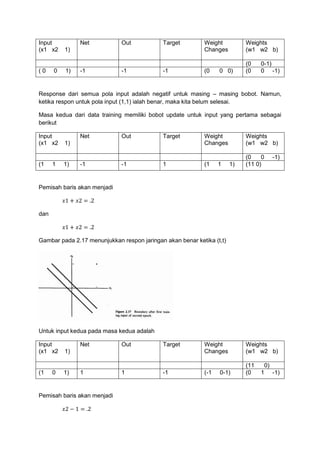
Input
(x1 x2
1)
(1
1)
1
Net
Out
Target
Weight
Changes
0
0
1
(1
Pemisah baris akan menjadi
dan
1
Weights
(w1 w2 b)
1)
(0
(1
0
1
0)
1)
3.
Gambar pada figure2.15 menunjukkan bahwa respon dari jaringan akan benar untuk input
pola pertama. Menampilkan input yang kedua sebagai berikut
Input
(x1 x2
1)
(1
1)
0
Net
Out
Target
Weight
Changes
2
1
-1
(-1
0
Weights
(w1 w2 b)
- 1)
(0
(0
0
1
0)
0)
Pemisah baris akan menjadi
dan
Gambar pada 2.16 menunjukkan espon pada jarigan masih tetap benar untuk poin input
pertama. Menampilkan input ketiga sebagai berikut
Input
(x1 x2
( 01
1)
Net
Out
Target
1)
1
1
-1
Untuk pola data training ke-empat, sebagai berikut
Weight
Changes
Weights
(w1 w2 b)
(0 -1
(0
(0
- 1)
1
0
0)
-1)
4.
Input
(x1 x2
1)
(0
1)
0
Net
Out
Target
Weight
Changes
Weights
(w1 w2b)
-1
-1
-1
(0
(0
(0
0 0)
0-1)
0 -1)
Response dari semua pola input adalah negatif untuk masing – masing bobot. Namun,
ketika respon untuk pola input (1,1) ialah benar, maka kita belum selesai.
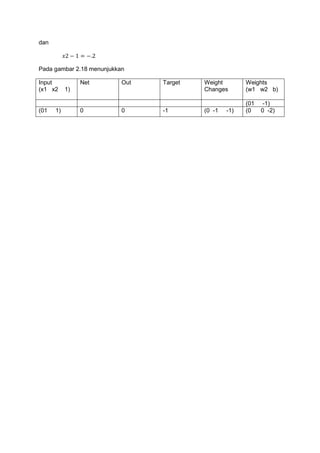
Masa kedua dari data training memiliki bobot update untuk input yang pertama sebagai
berikut
Input
(x1 x2
(1
1
Net
Out
Target
1)
1)
-1
-1
1
Weight
Changes
Weights
(w1 w2 b)
(1
(0
0
(11 0)
1
1)
-1)
Pemisah baris akan menjadi
dan
Gambar pada 2.17 menunjukkan respon jaringan akan benar ketika (t,t)
Untuk input kedua pada masa kedua adalah
Input
(x1 x2
(1
0
Net
Out
Target
1)
1)
1
Pemisah baris akan menjadi
1
-1
Weight
Changes
Weights
(w1 w2 b)
(-1
(11
(0
0-1)
0)
1 -1)
5.
dan
Pada gambar 2.18menunjukkan
Input
(x1 x2
(01
1)
Net
Out
Target
1)
0
0
-1
Weight
Changes
Weights
(w1 w2 b)
(0 -1
(01
(0
-1)
-1)
0 -2)