Download as PDF, PPTX
























![Example #1
Typical ScaleIn/ScaleOut events and cases
onAfterScaleOut[nodeGroup:ejb-app1] {
“call”: “registerNodeInMonitoringSystem”,
“call”: “addMemberToHazelcast”,
“call”: “call3rdPartyApiService”
}
onAfterScaleIn[nodeGroup:jsp-app2] {
“call”: “removeNodeFromMonitoringSystem”,
“call”: “removeMemberFromHazelcast”
}
THE FULL WORKING AND MORE COMPLEX CODE EXAMPLE CAN BE FOUND HERE](https://image.slidesharecdn.com/jeeconf-2017-final-170529073914/85/JEEconf-2017-34-320.jpg)
![Example #2
2. Get auth keys by instance before joining DAS
onBeforeStartService[nodeGroup:instance] {
“cmd”: “/root/scripts/pullAccessKeys.sh ${token}”
}
THE FULL WORKING AND MORE COMPLEX CODE EXAMPLE CAN BE FOUND HERE
1. Decrypt encrypted volume, that was attached on-fly
onAfterVolumeAttached[nodeGroup:instance] {
“call”: “decryptVolume”
}
3. Deprovision node from DAS if cluster was shrinked
onAfterScaleOut[nodeGroup:das] {
“cmd”: “./asadmin_proxy remove ${instance[@last].ip}”
}](https://image.slidesharecdn.com/jeeconf-2017-final-170529073914/85/JEEconf-2017-35-320.jpg)




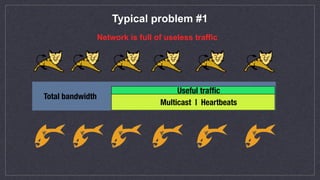

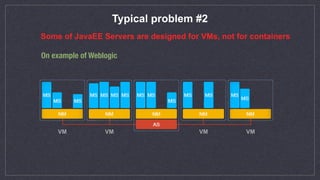
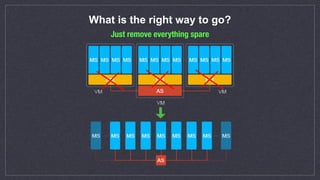



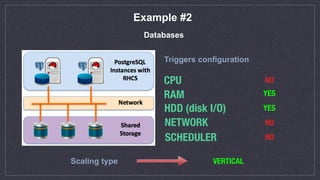
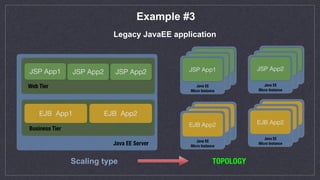
This document discusses automated scaling of JavaEE microservice stacks. It begins by introducing the speaker and their experience with autoscaling technologies. It then explains that while simple applications can be easily scaled by increasing container replicas, scaling complex JavaEE applications requires more work. The document outlines three key aspects needed for scalable applications: using lightweight application servers adapted for containers; decomposing monolithic applications into independently scalable microservices; and using orchestration software to automate provisioning, health checks, metrics collection, and scaling. It provides examples of scaling strategies for different application components like message queues and databases. It also discusses common issues like ensuring new instances are properly registered for events and services. The document emphasizes that proper configuration of autoscaling triggers


























































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








