Download to read offline


























![Future Research Questions
• Can a PWAA perform content negotiation[1] on
the private-public spectrum?
• What level of security is needed?
– e.g., reporting UNAUTHORIZED vs. 0 mementos
A Framework for Aggregating Private and
Public Web Archives
62
JCDL 2015 Doctoral
Consortium
[1] RFC2295 https://www.ietf.org/rfc/rfc2295.txt](https://image.slidesharecdn.com/doctoralconsortiummatkelly-150621173738-lva1-app6892/85/JCDL-2015-Doctoral-Consortium-A-Framework-for-Aggregating-Private-and-Public-Web-Archives-62-320.jpg)





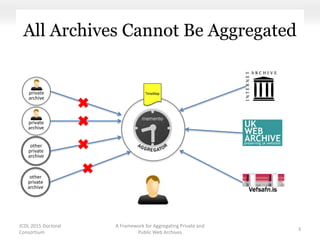
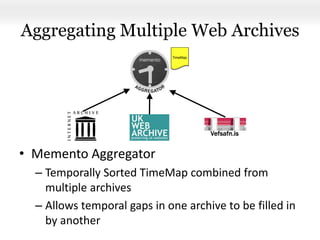
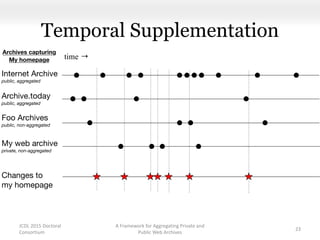
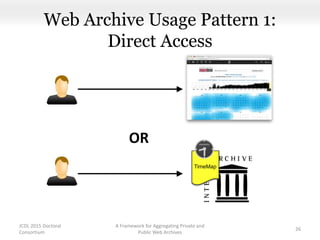
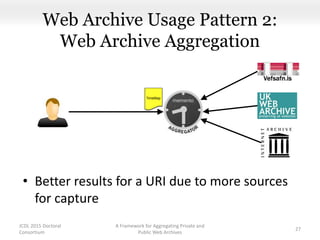
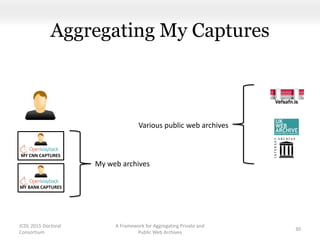
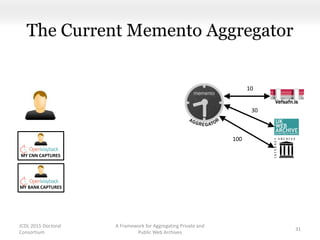
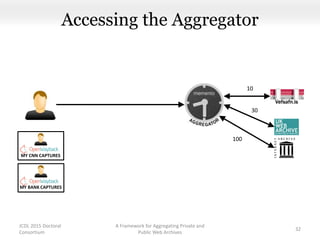
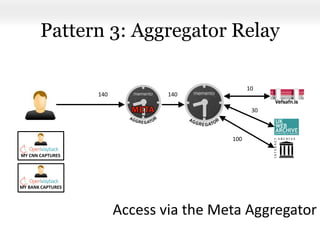
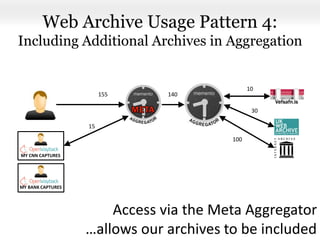
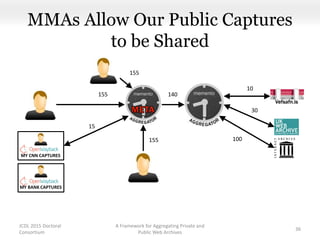
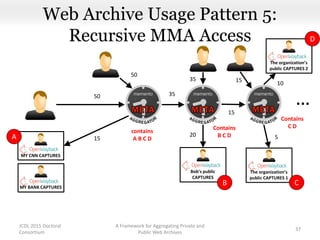
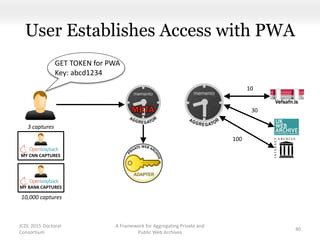
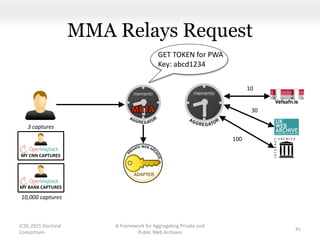
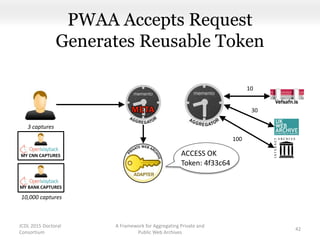
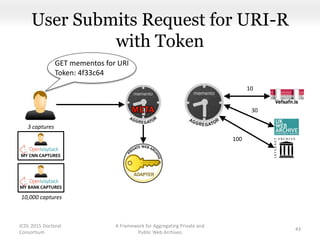
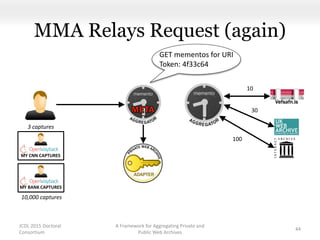
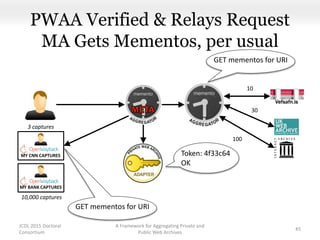
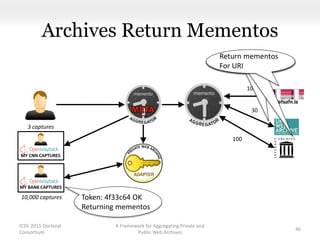
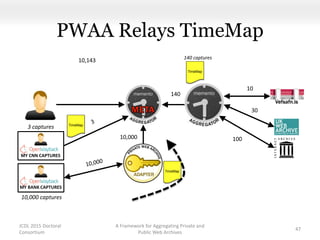
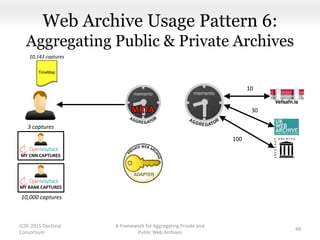
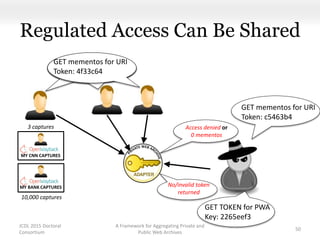
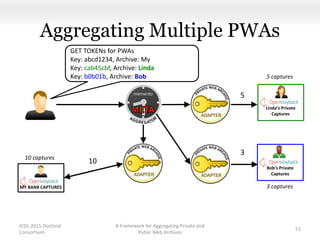
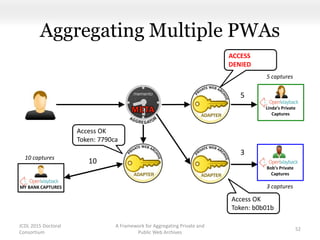
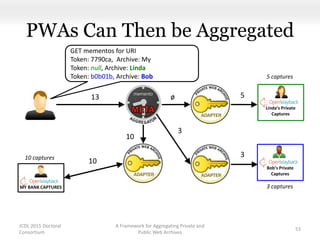
This document proposes a framework for aggregating private and public web archives. It introduces two new entities: the Memento Meta Aggregator (MMA) and the Private Web Archive Adapter (PWAA). The MMA allows for dynamic inclusion of archives and recursive construction of archive sets. The PWAA regulates access to private web archives by authenticating requests and relaying results. This framework enables private archives to be included in aggregations while preserving privacy through access control and authentication via the PWAA.


















































































