Downloaded 28 times















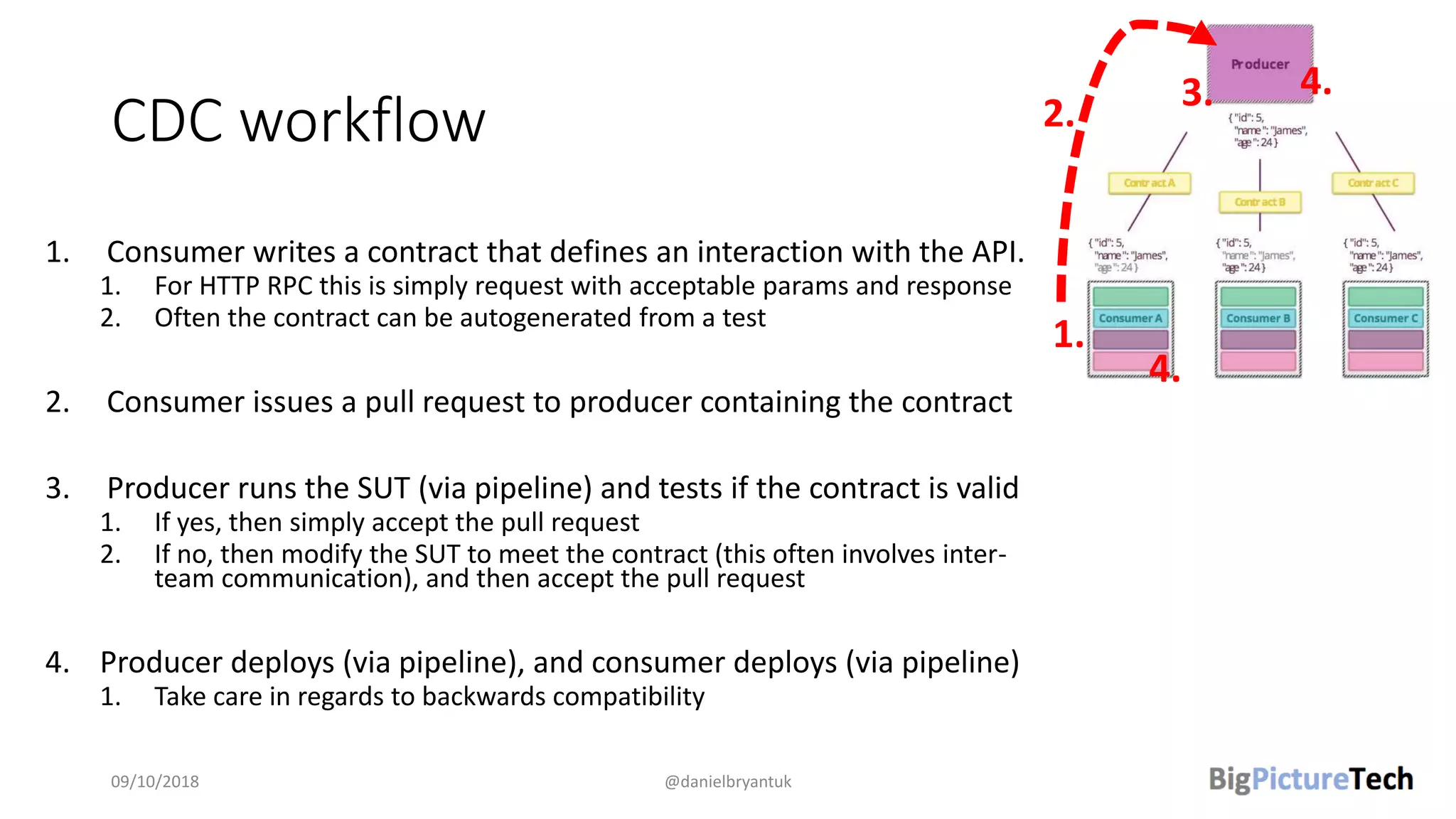
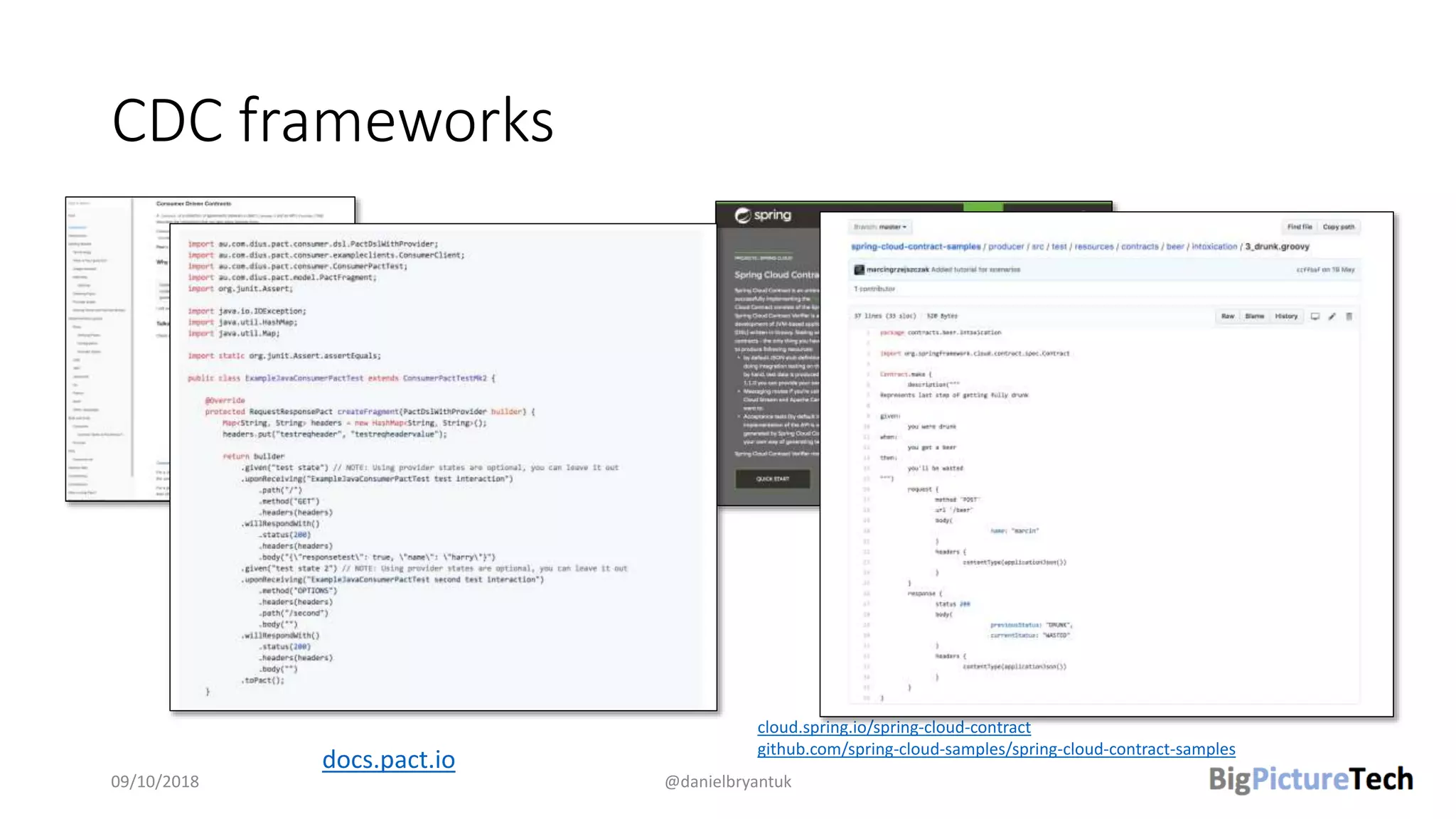

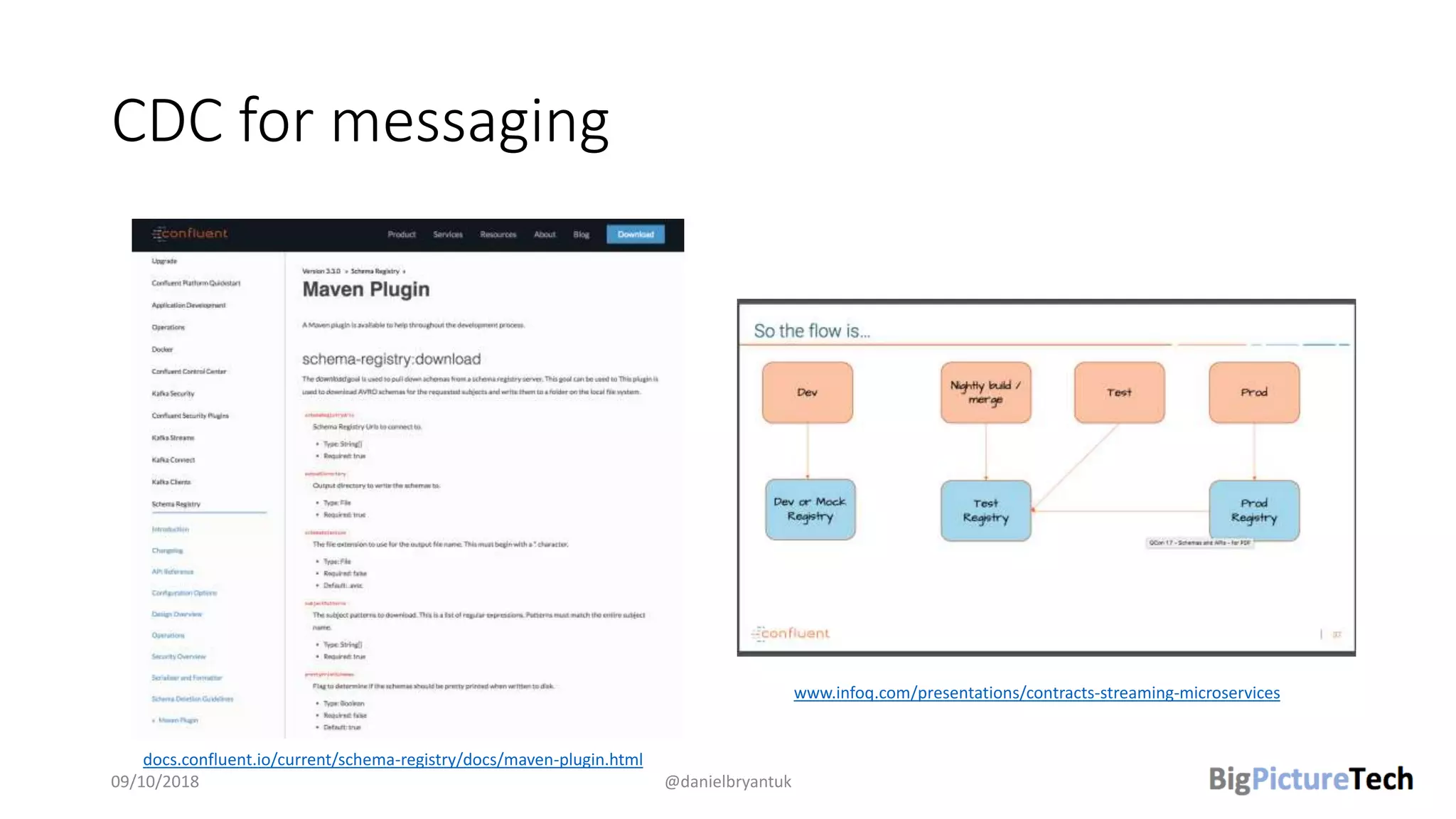


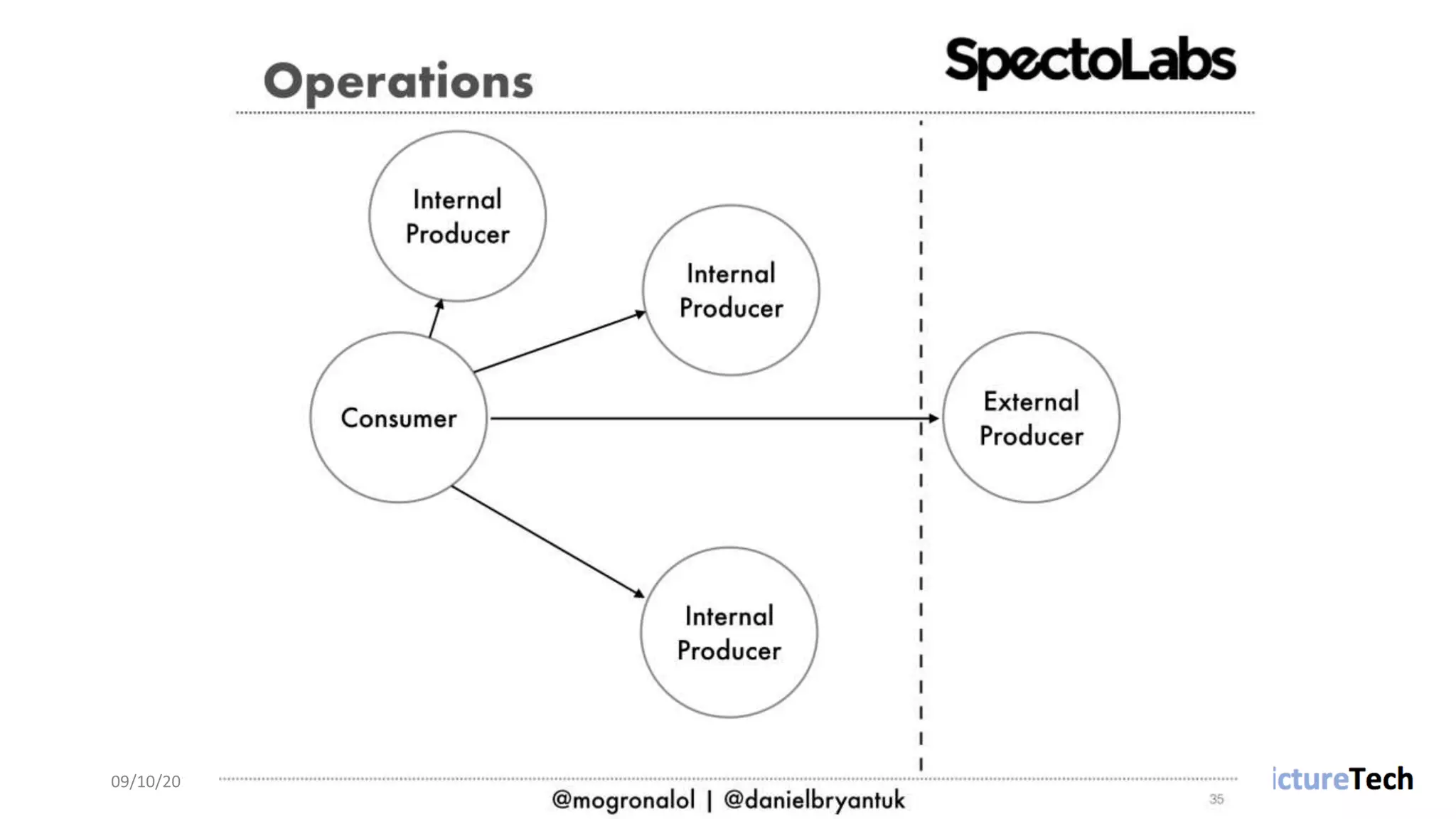
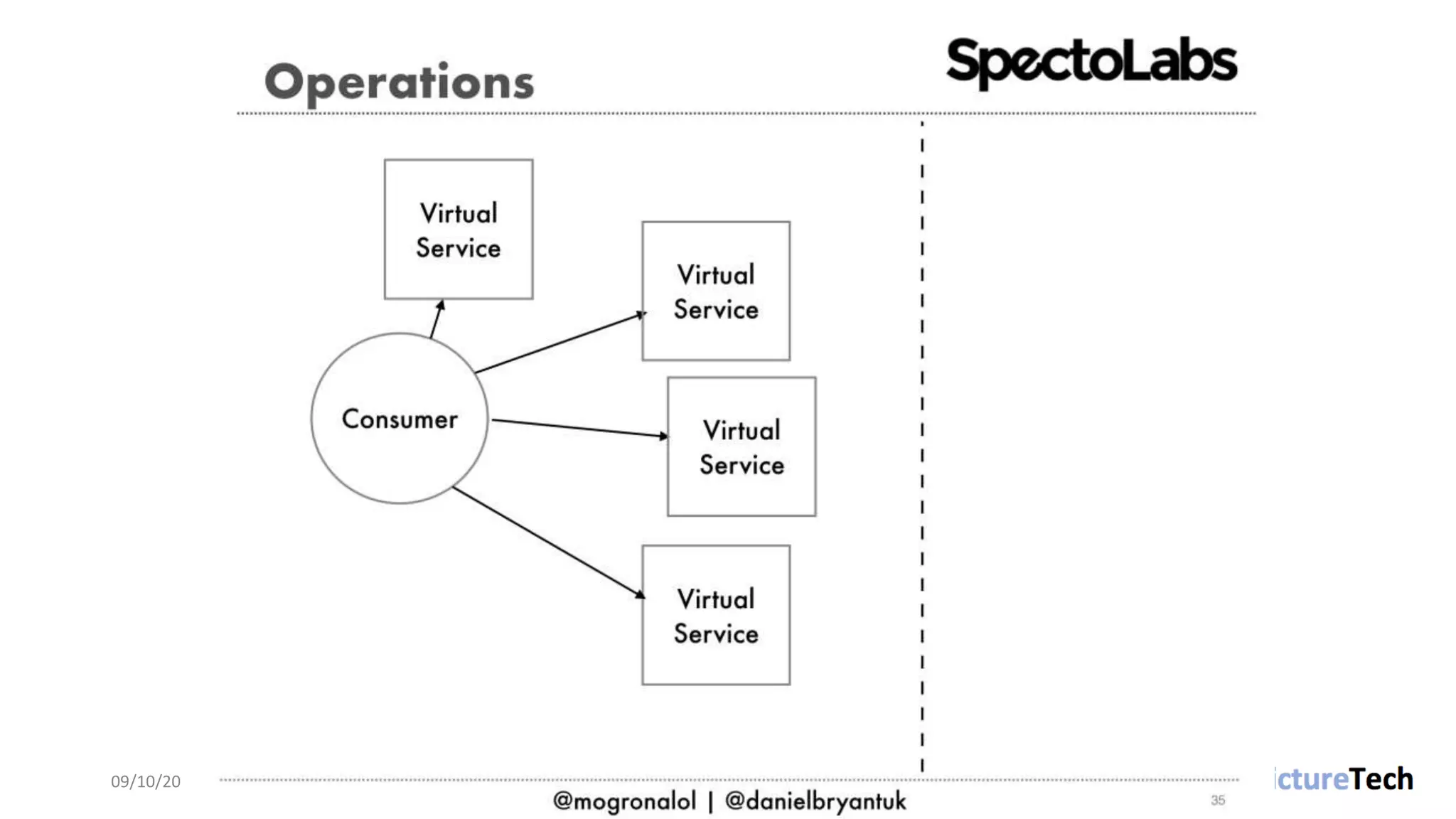

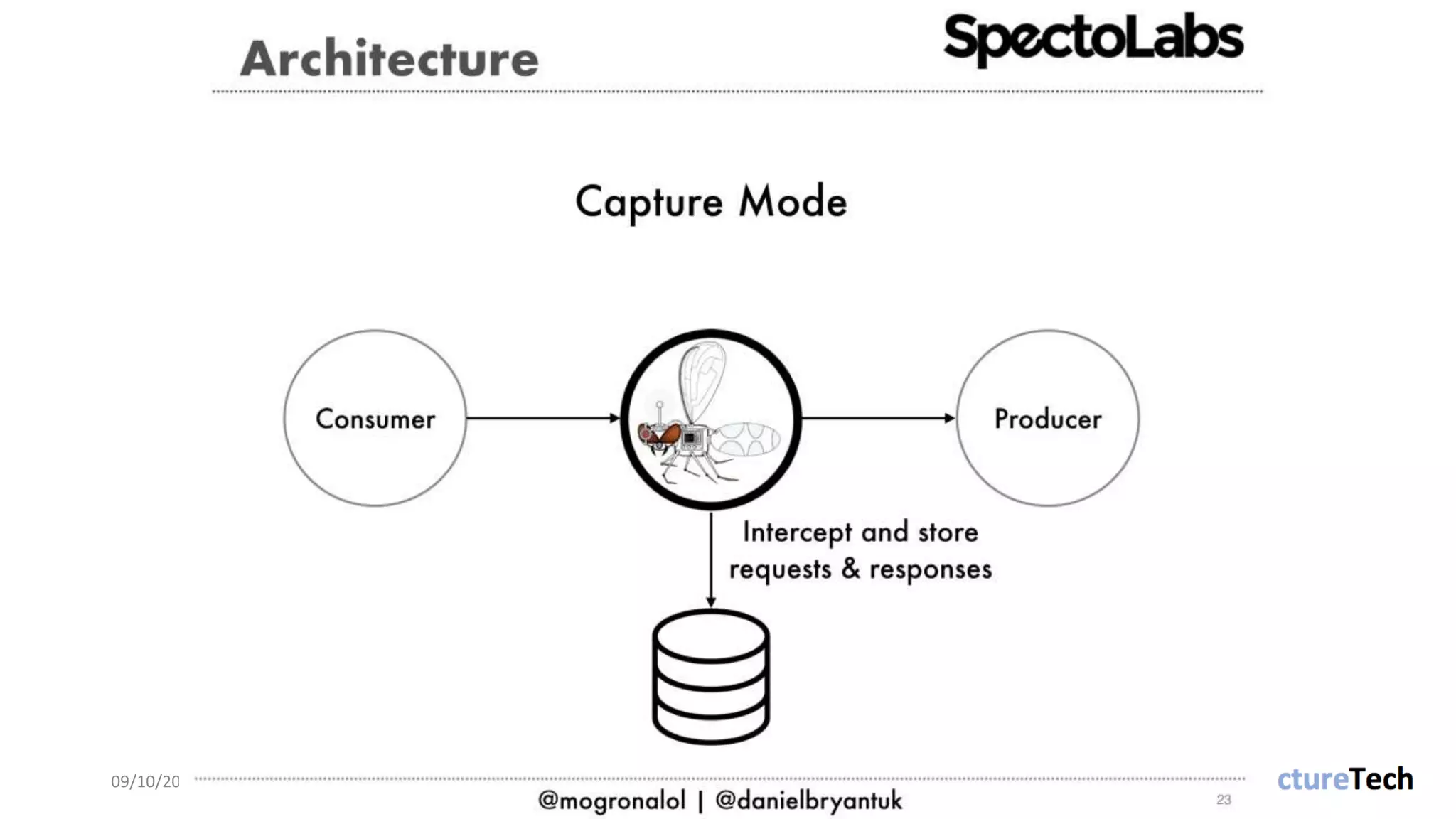
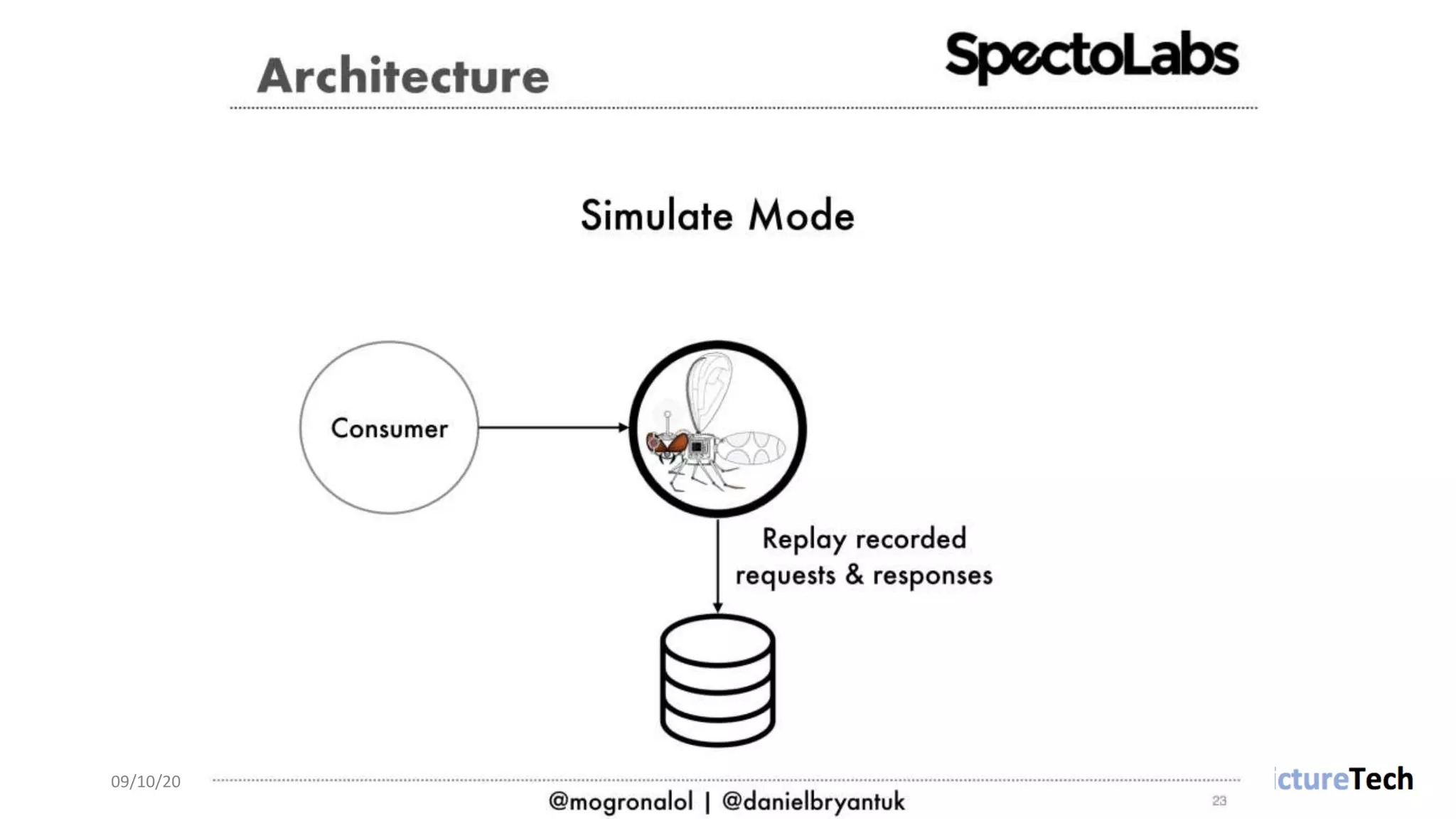
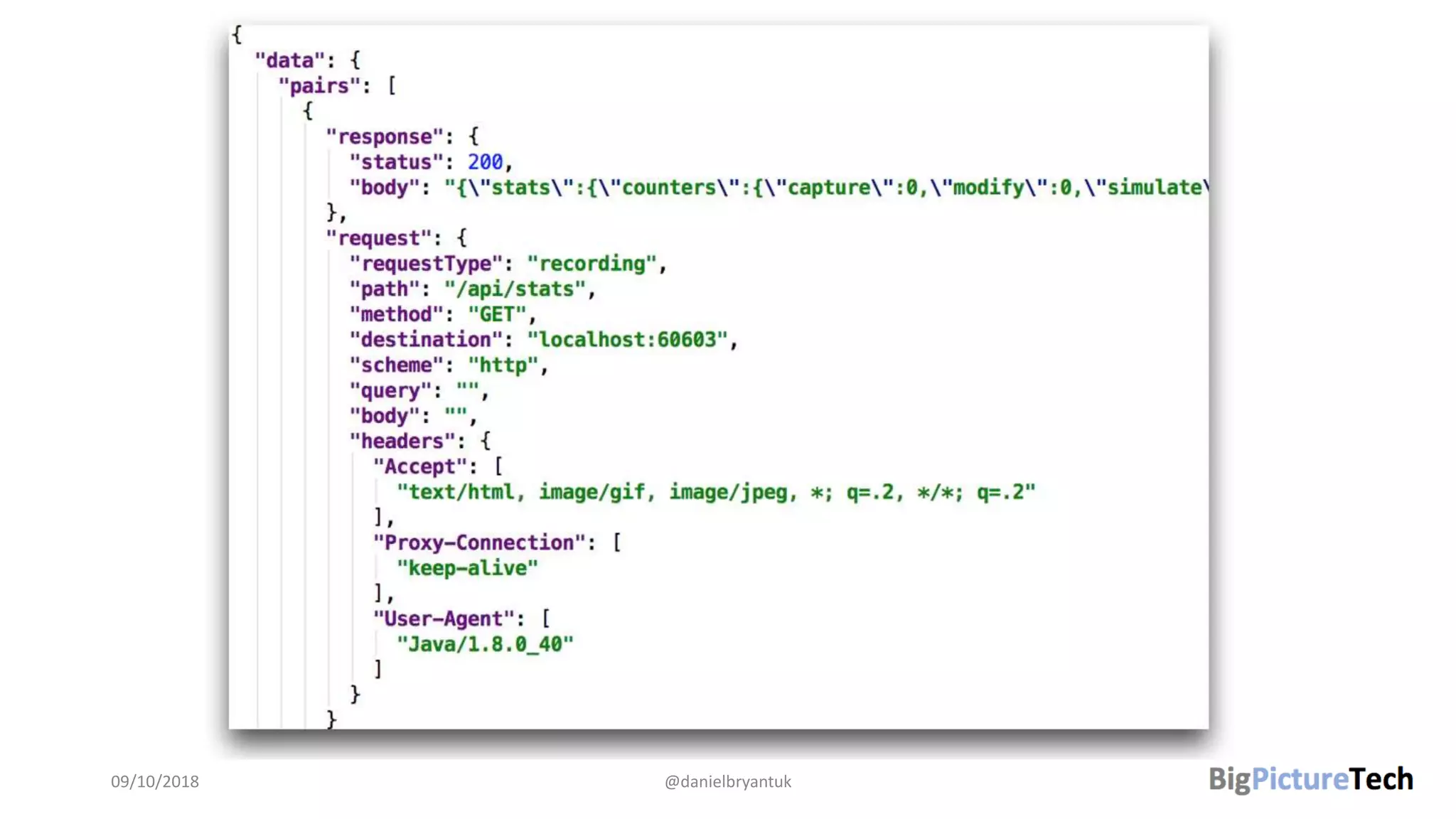
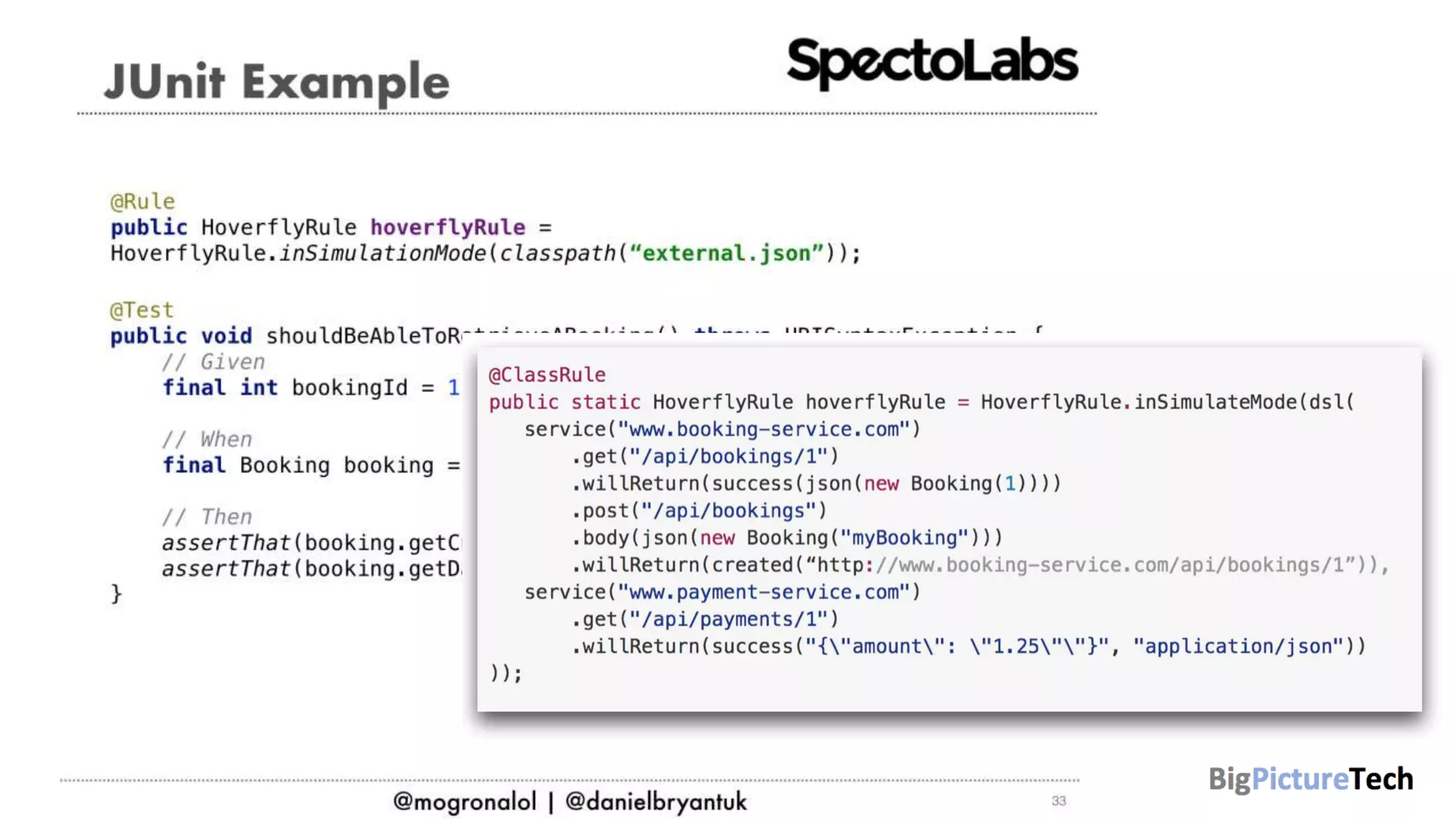

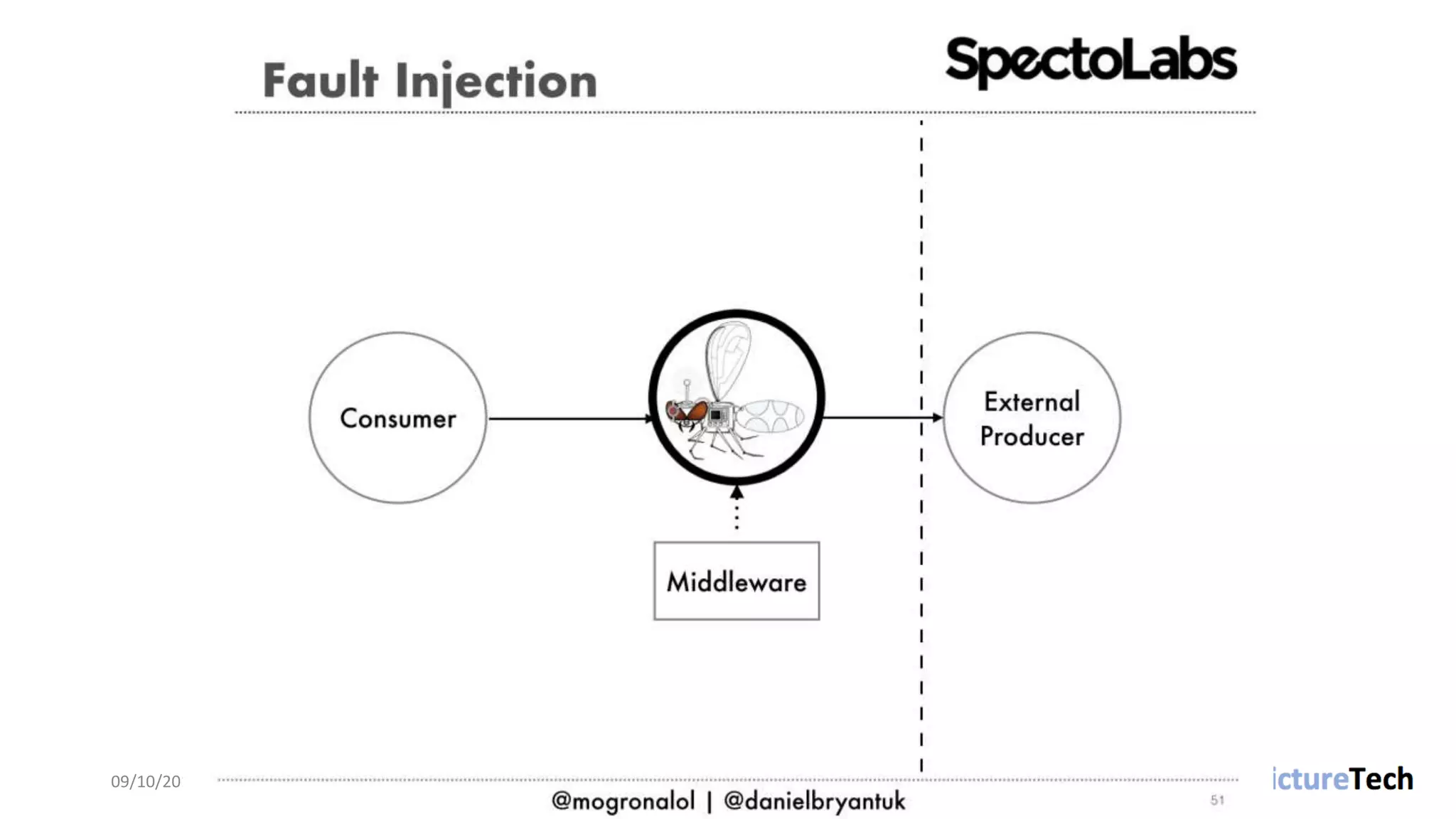







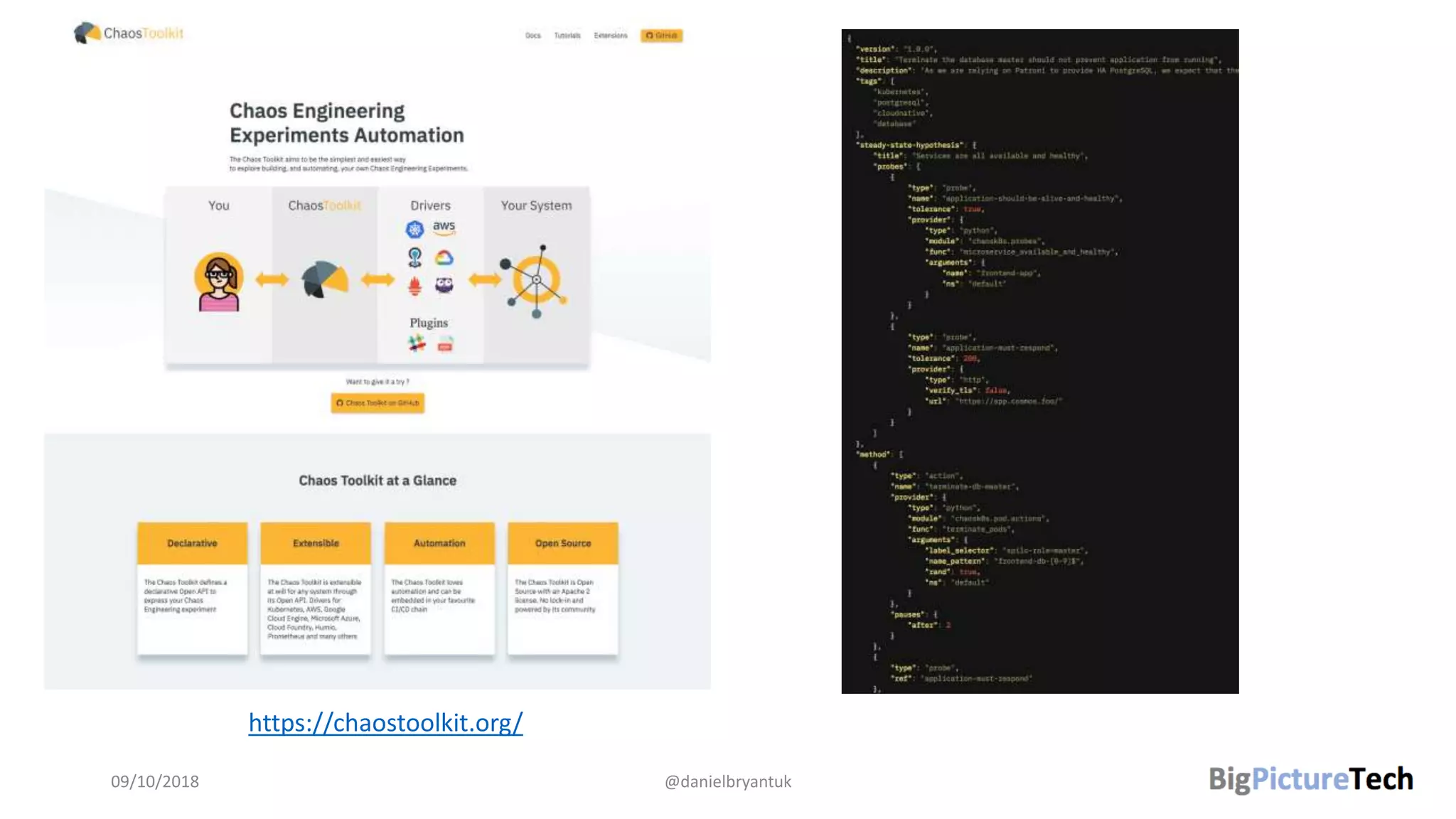
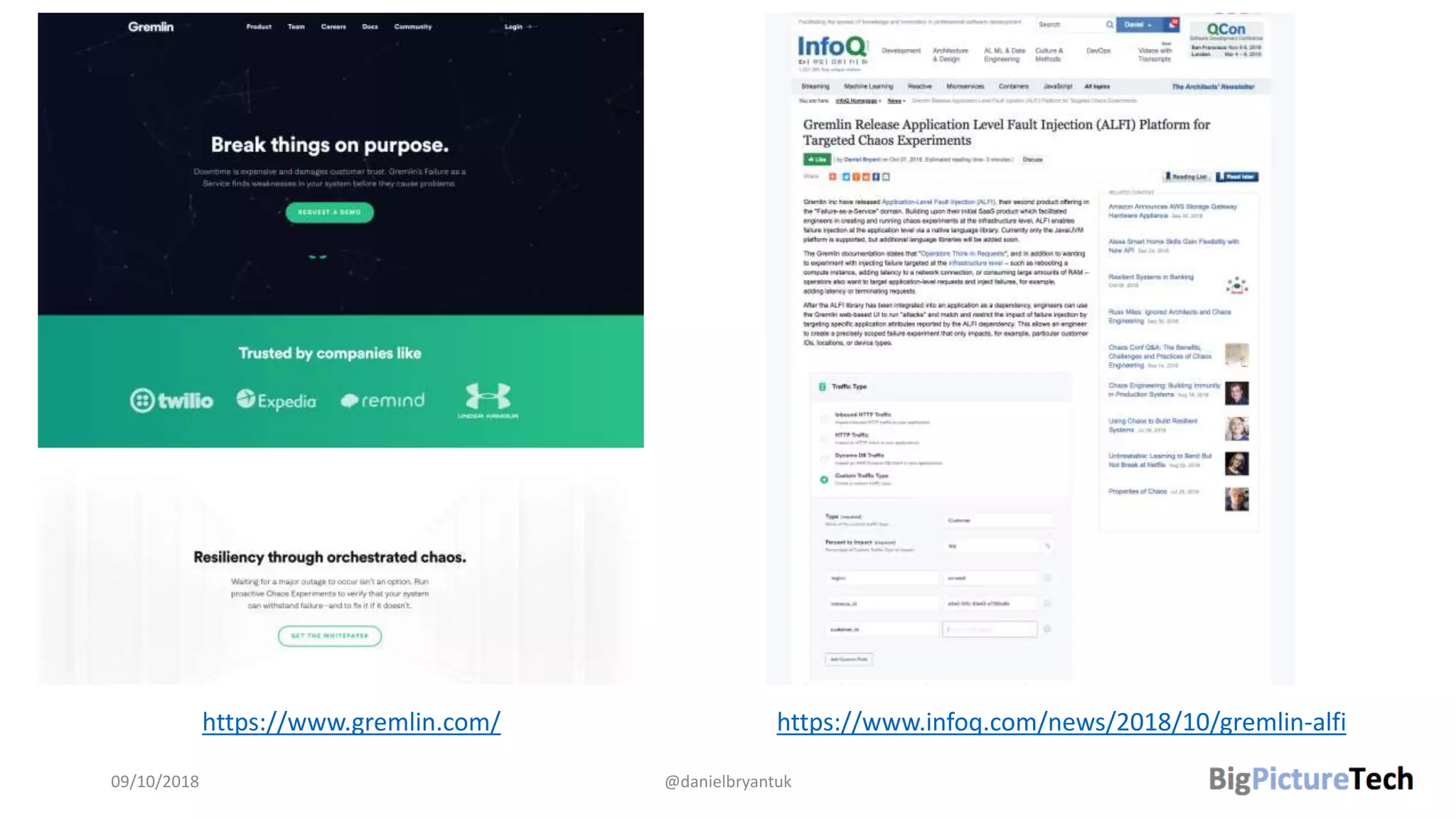







The document discusses strategies and techniques for testing microservices, emphasizing the balance between pre-production and post-production tests. It highlights the importance of contract testing, API simulation, and chaos engineering while cautioning against overly simplistic or rigid testing approaches. The author, Daniel Bryant, asserts that a well-thought-out testing strategy can enhance system reliability and resilience.





















![[SC London] "Testing Microservices: from Development to Production](https://cdn.slidesharecdn.com/ss_thumbnails/sclondontestingmicroservicesfromdevelopmenttoproduction1copy-191007090840-thumbnail.jpg?width=640&height=640&fit=bounds)













































