Downloaded 25 times



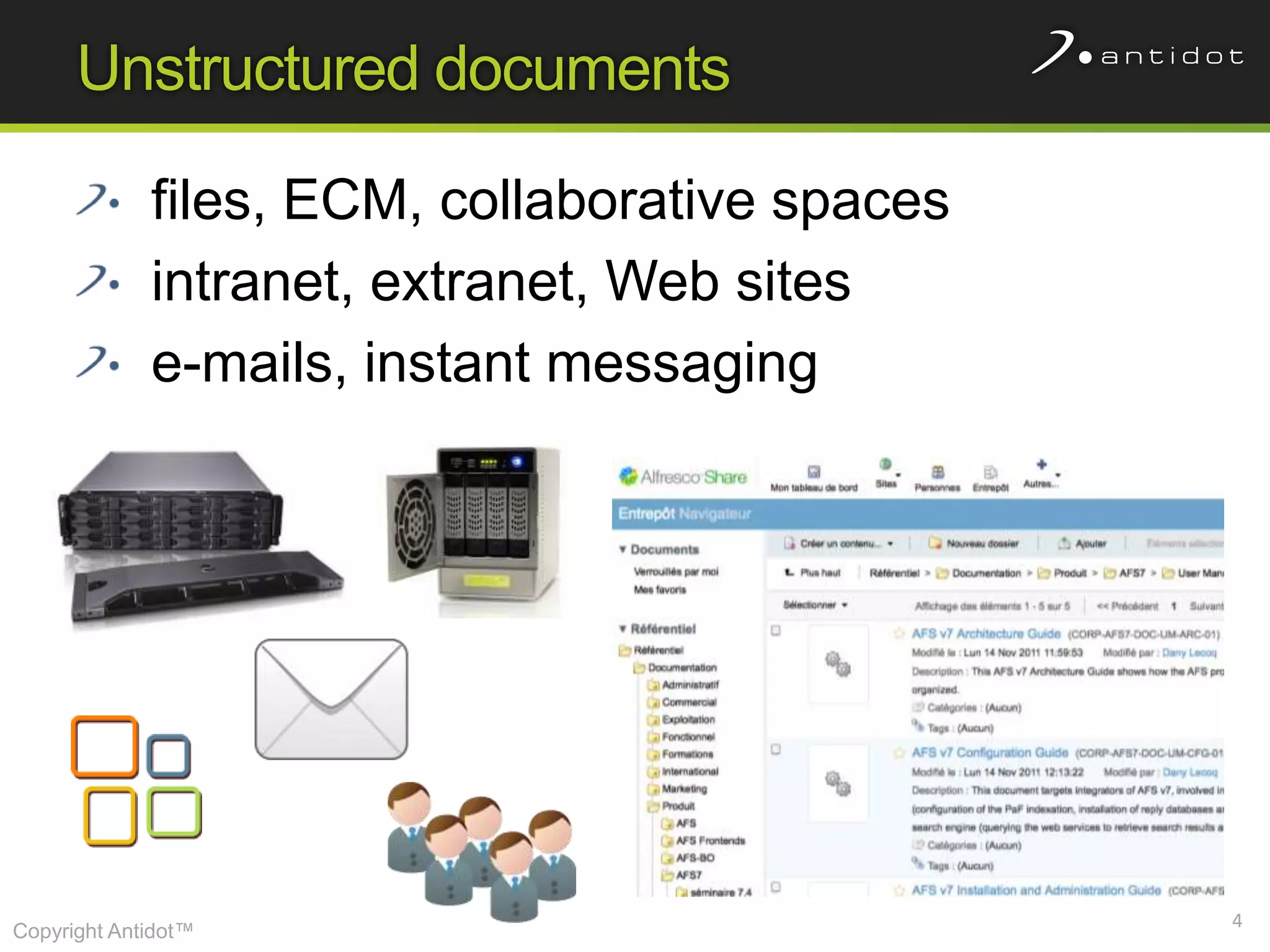
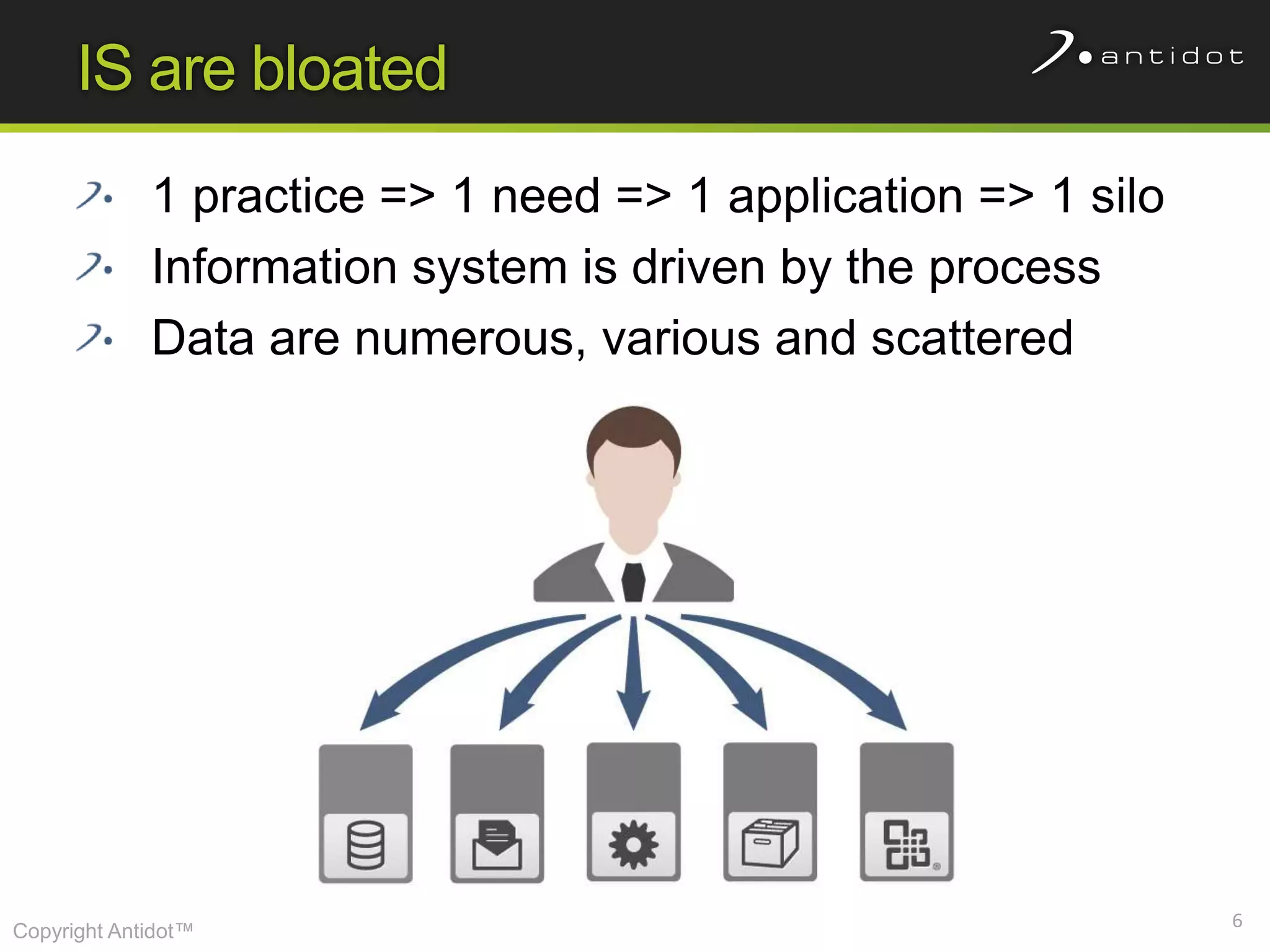
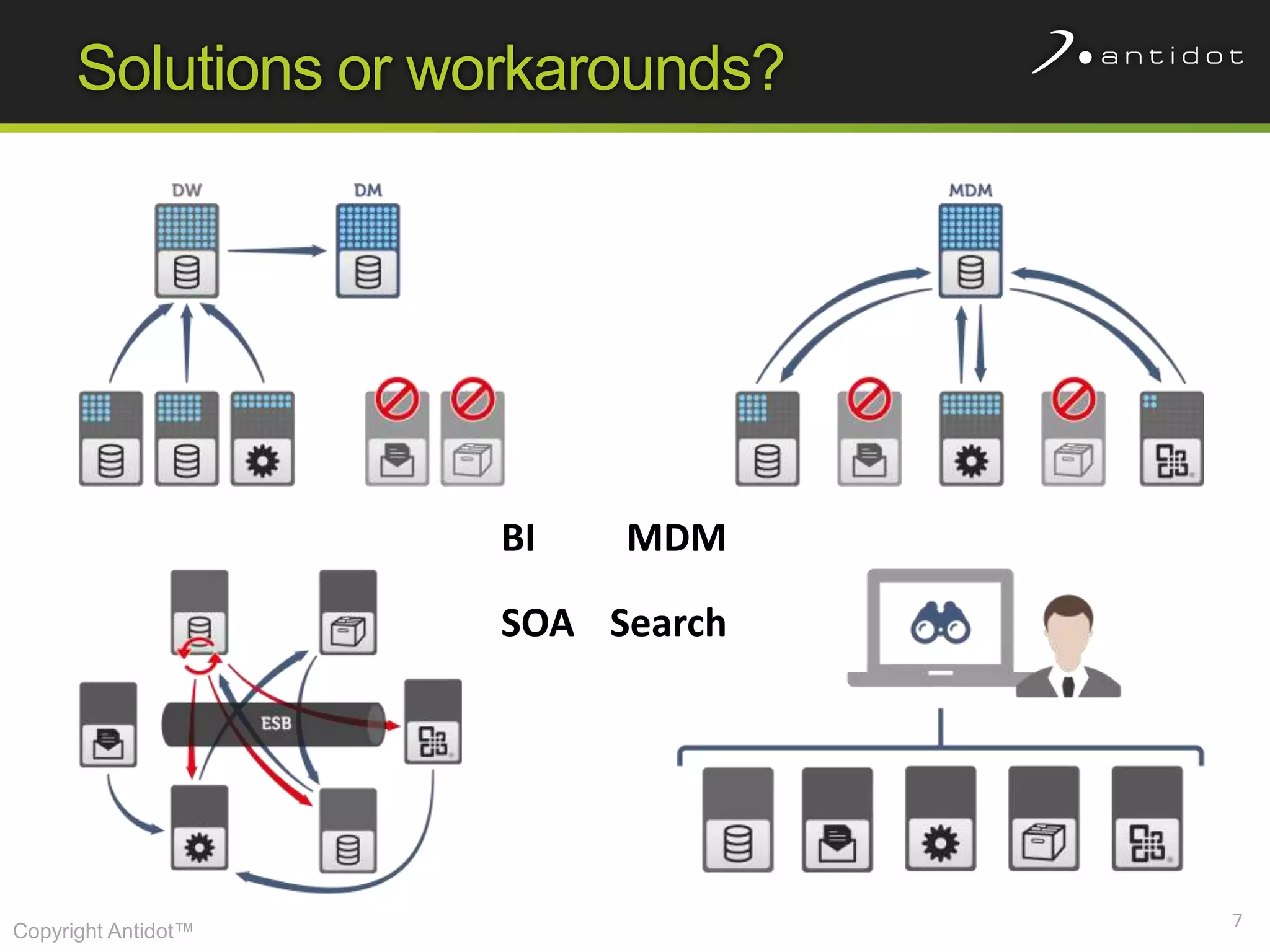
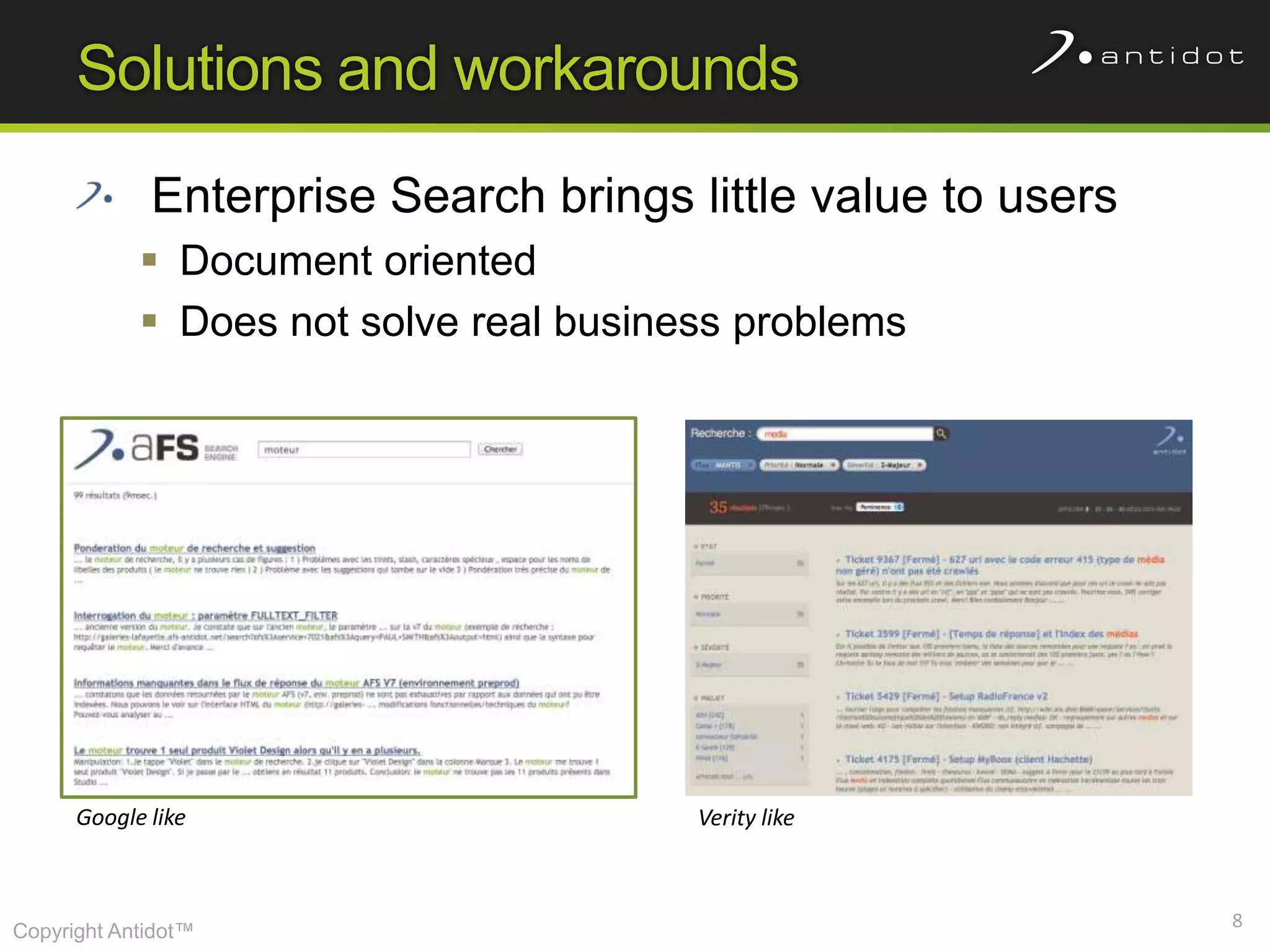
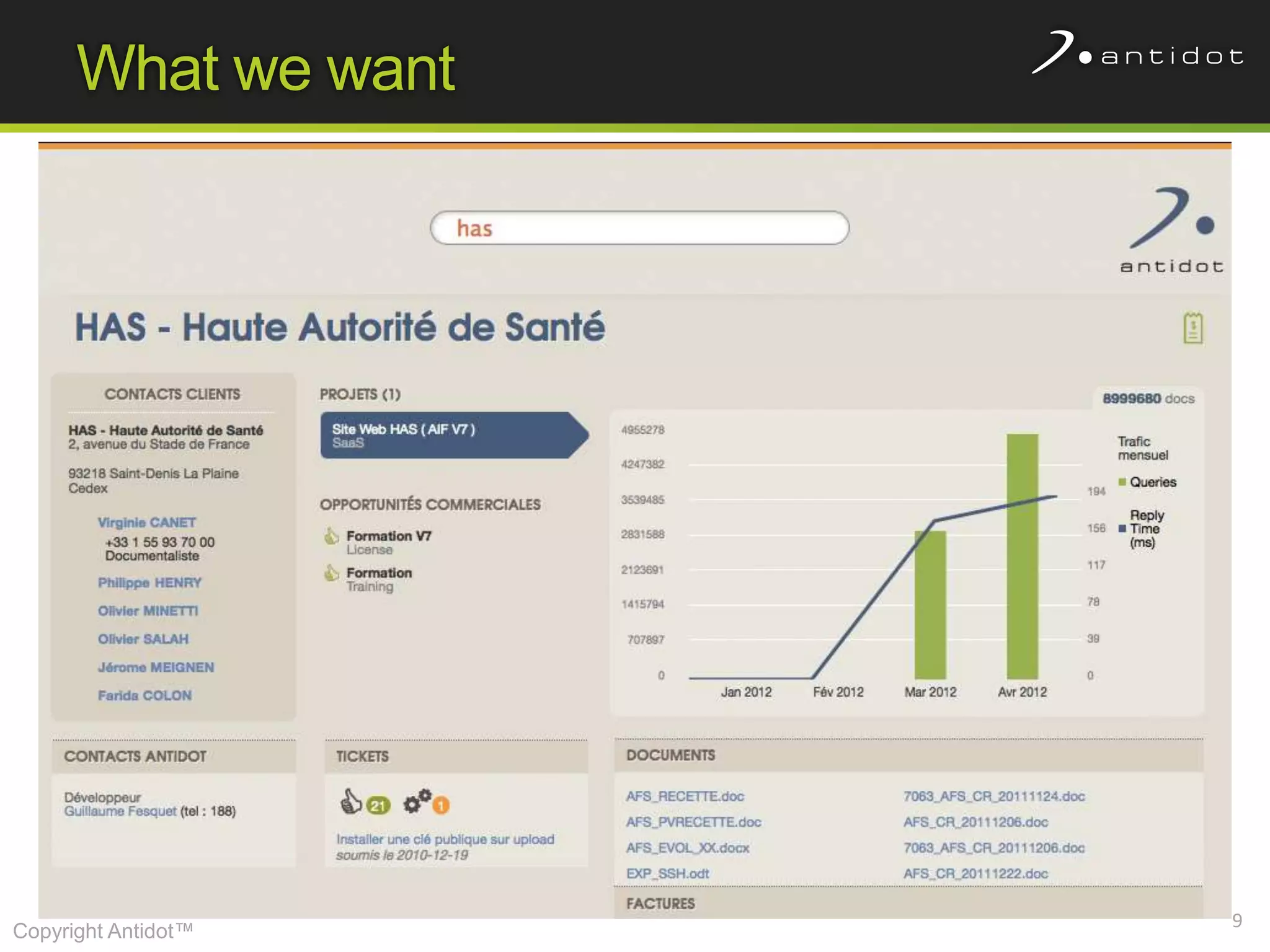
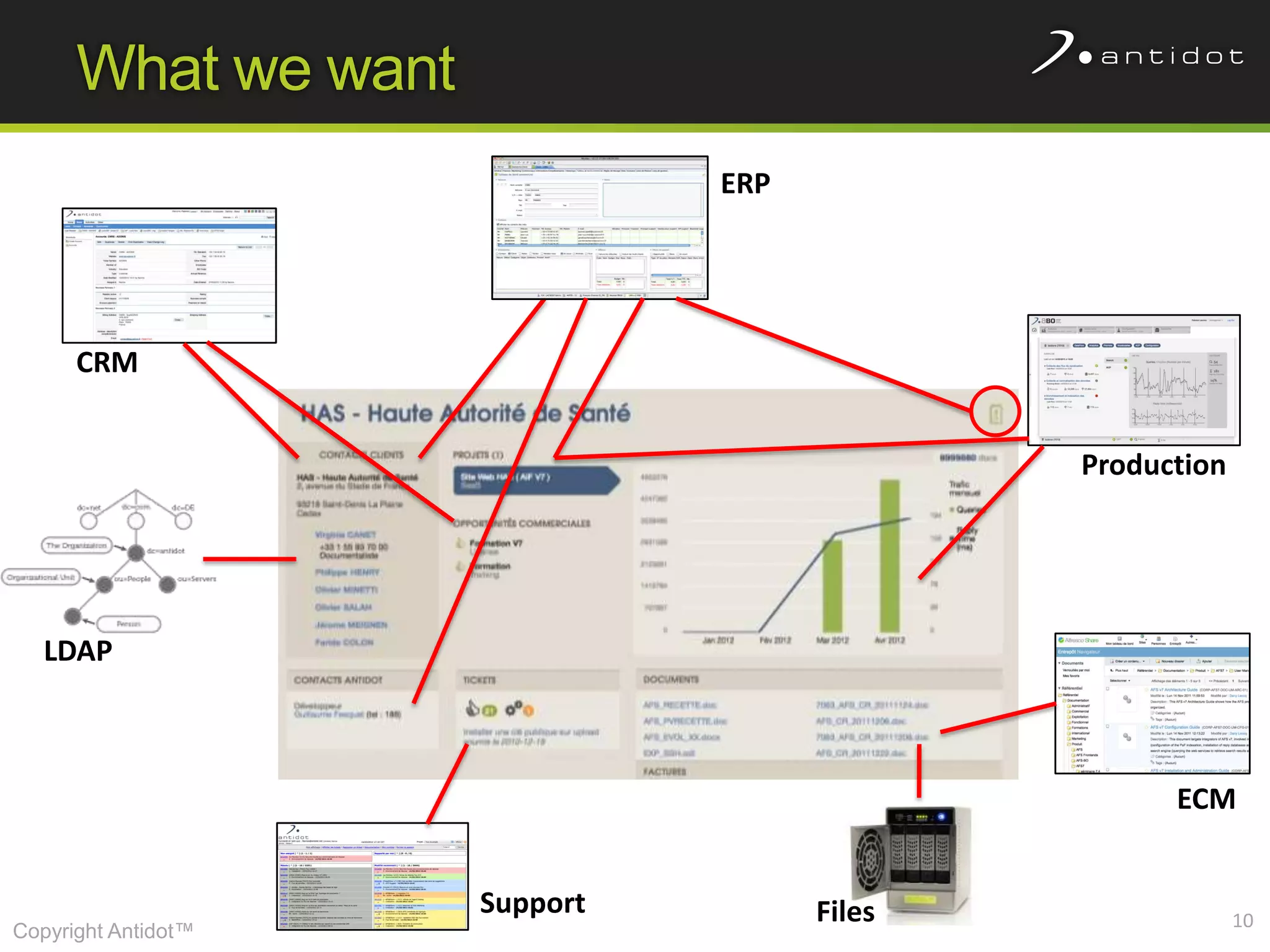
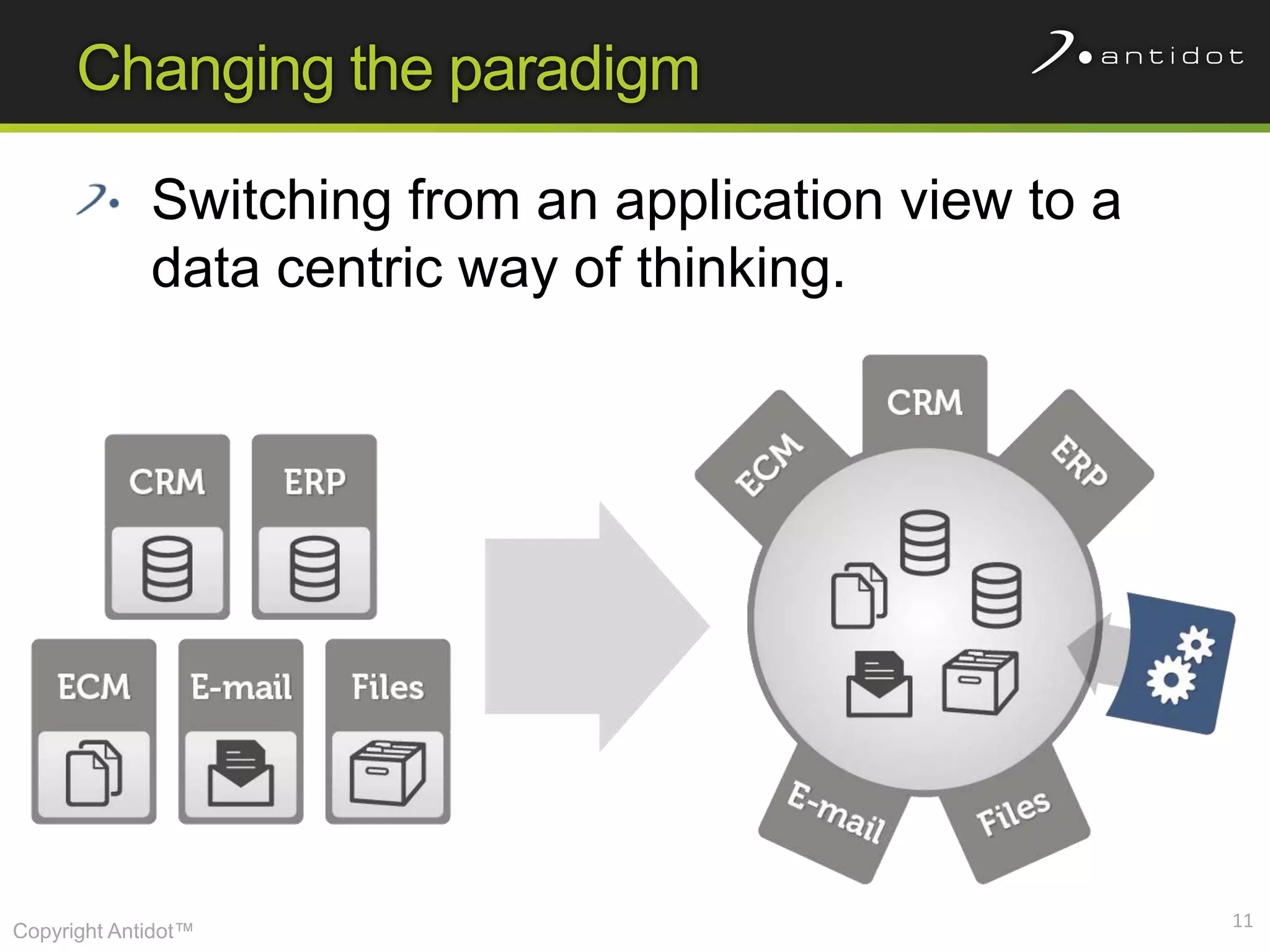
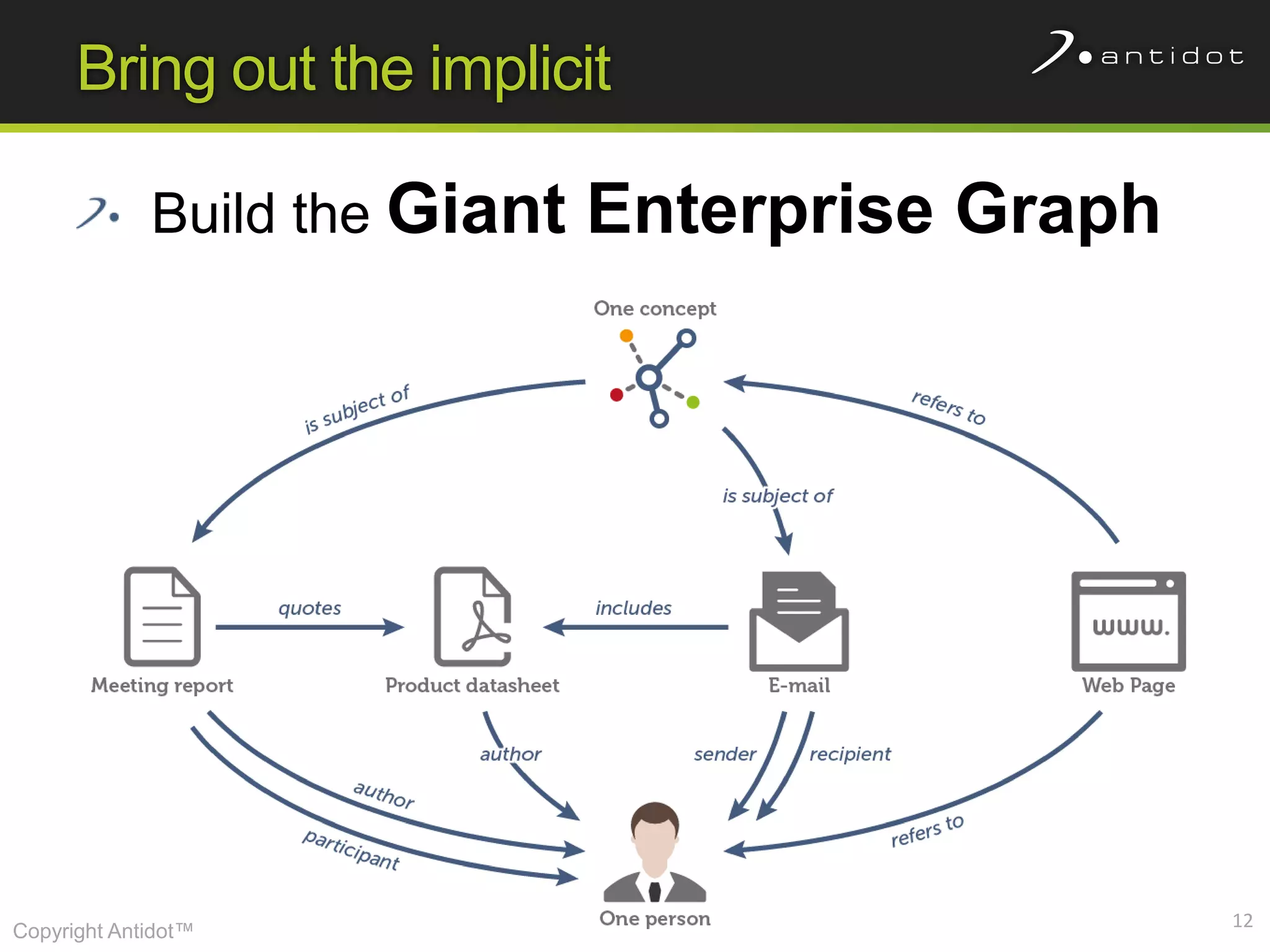

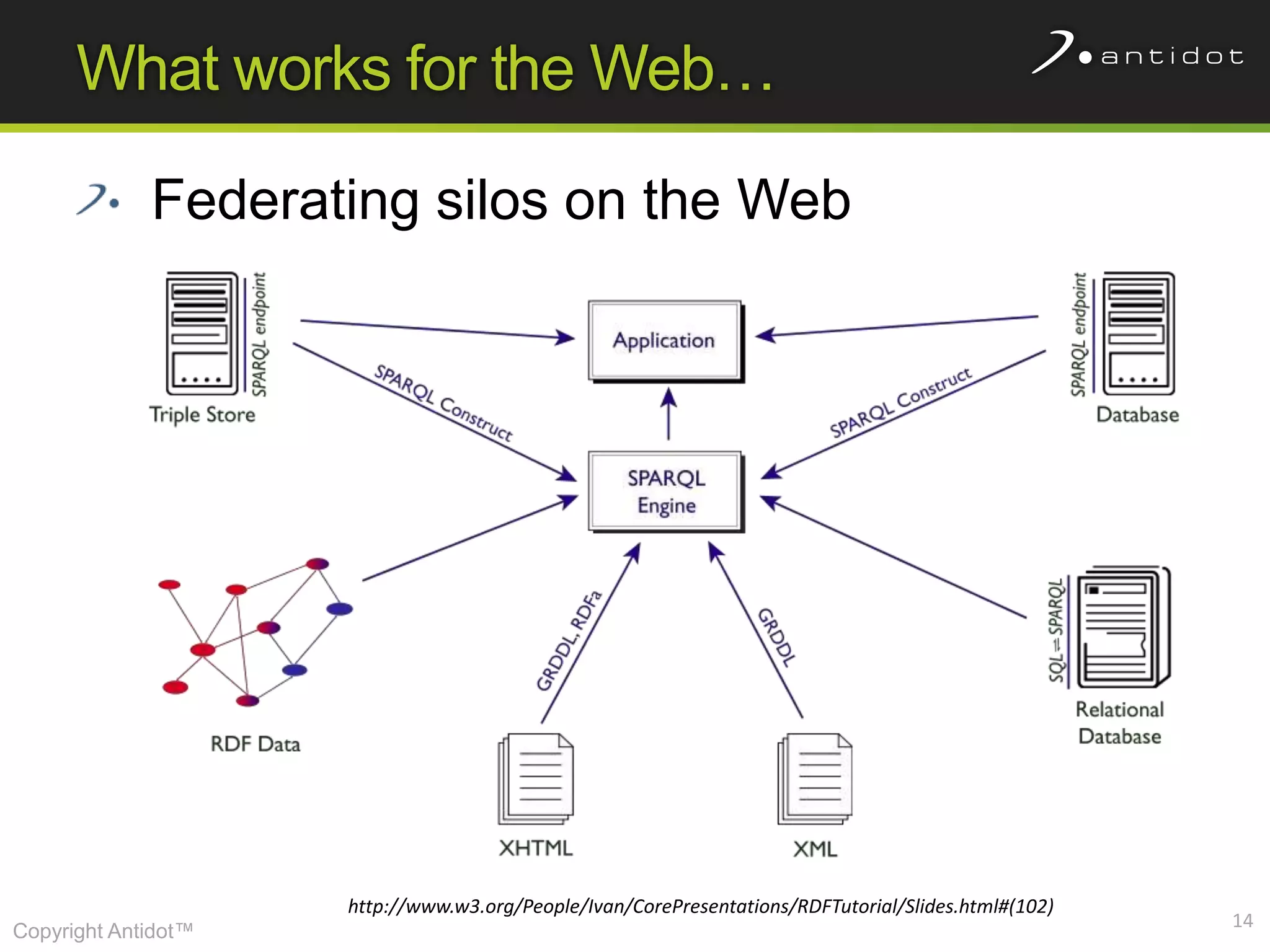



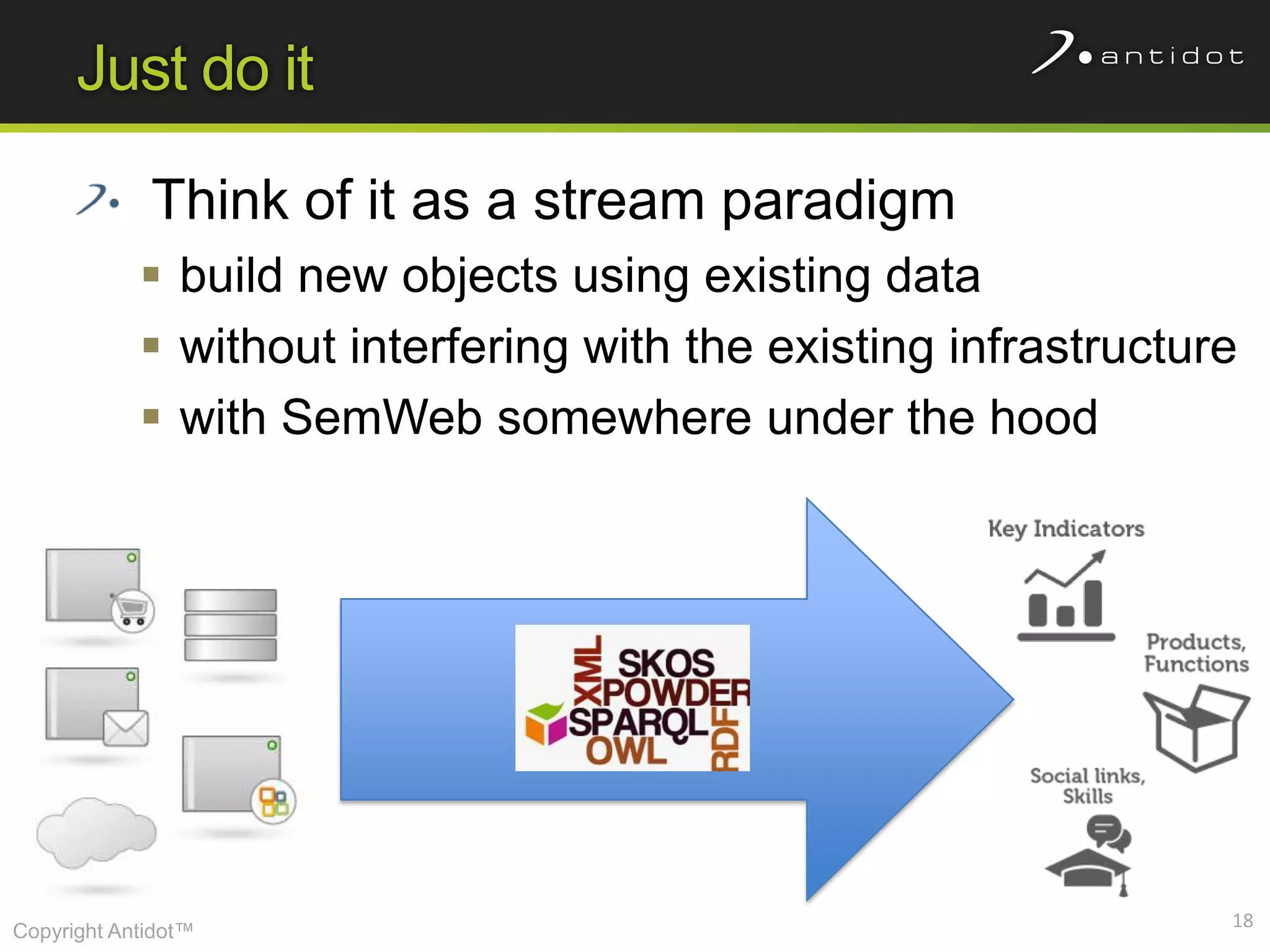
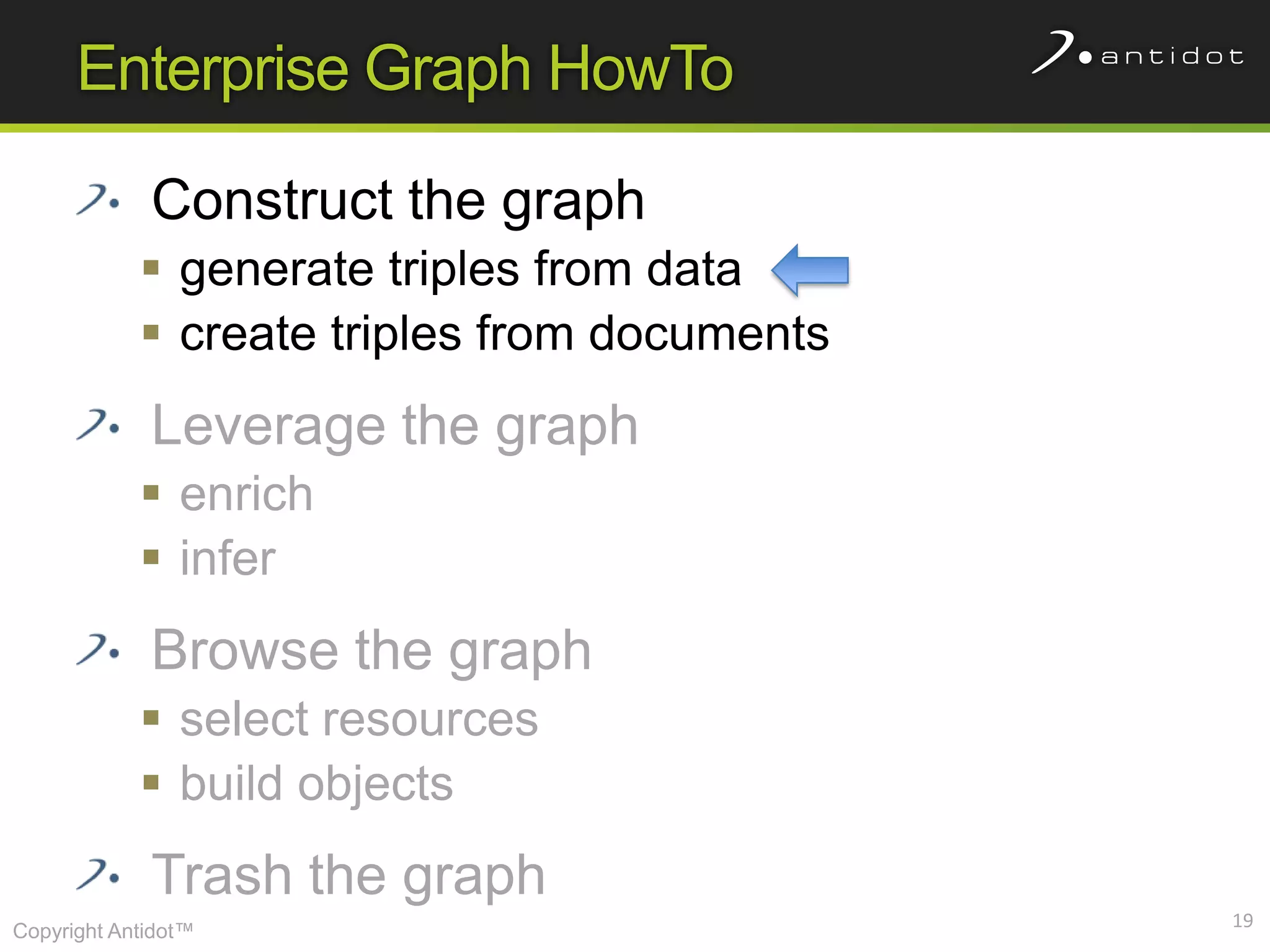

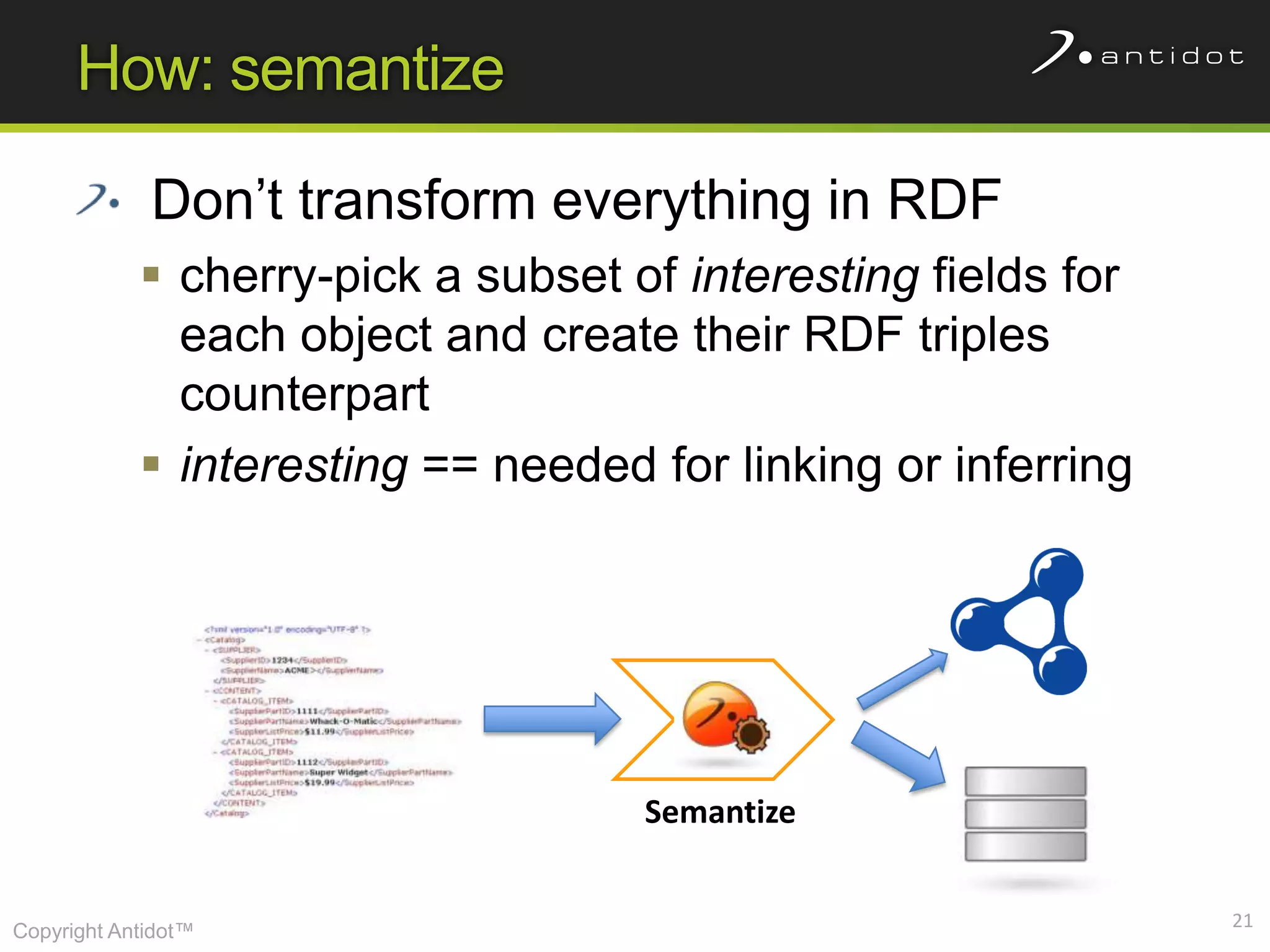



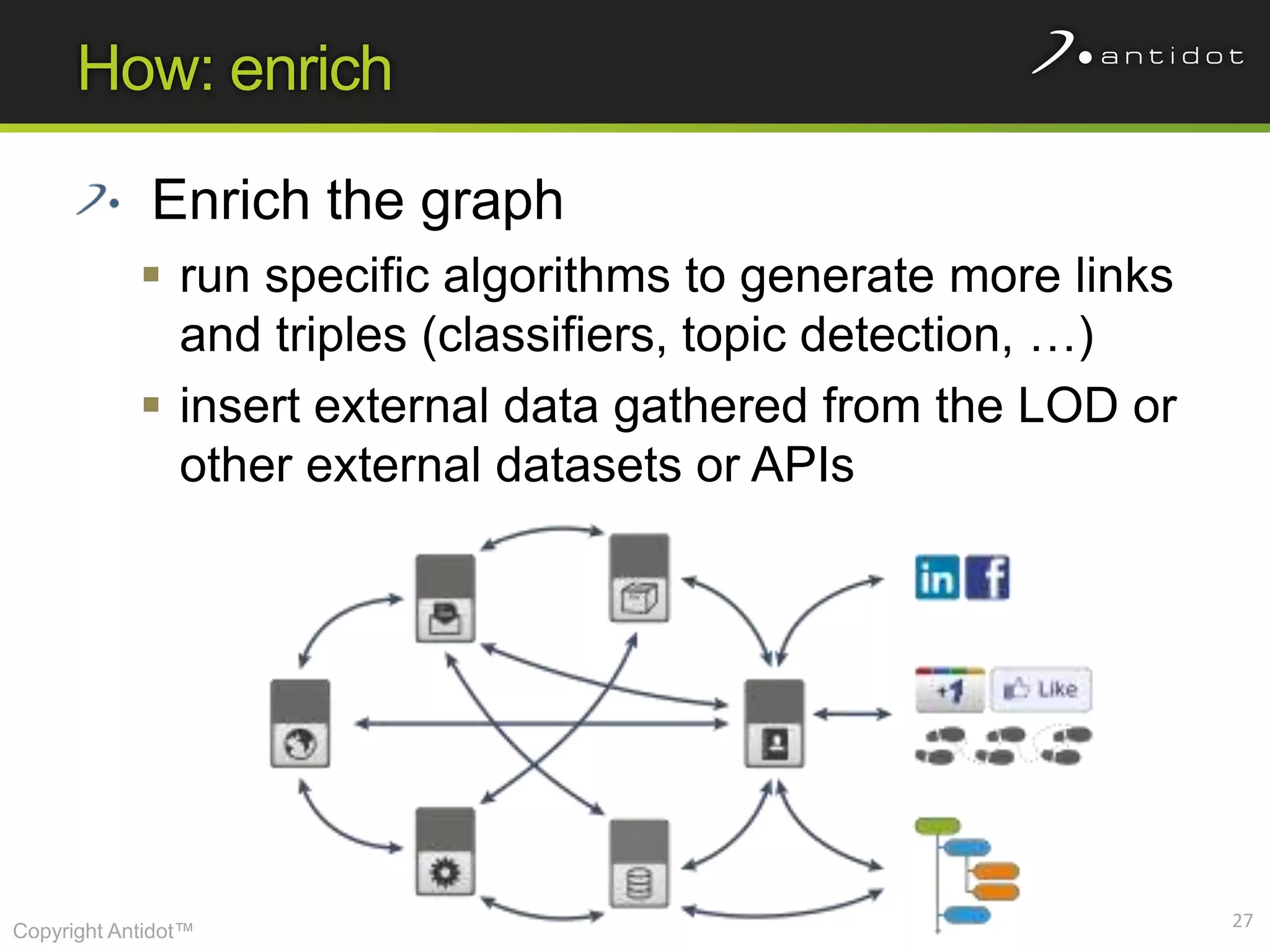
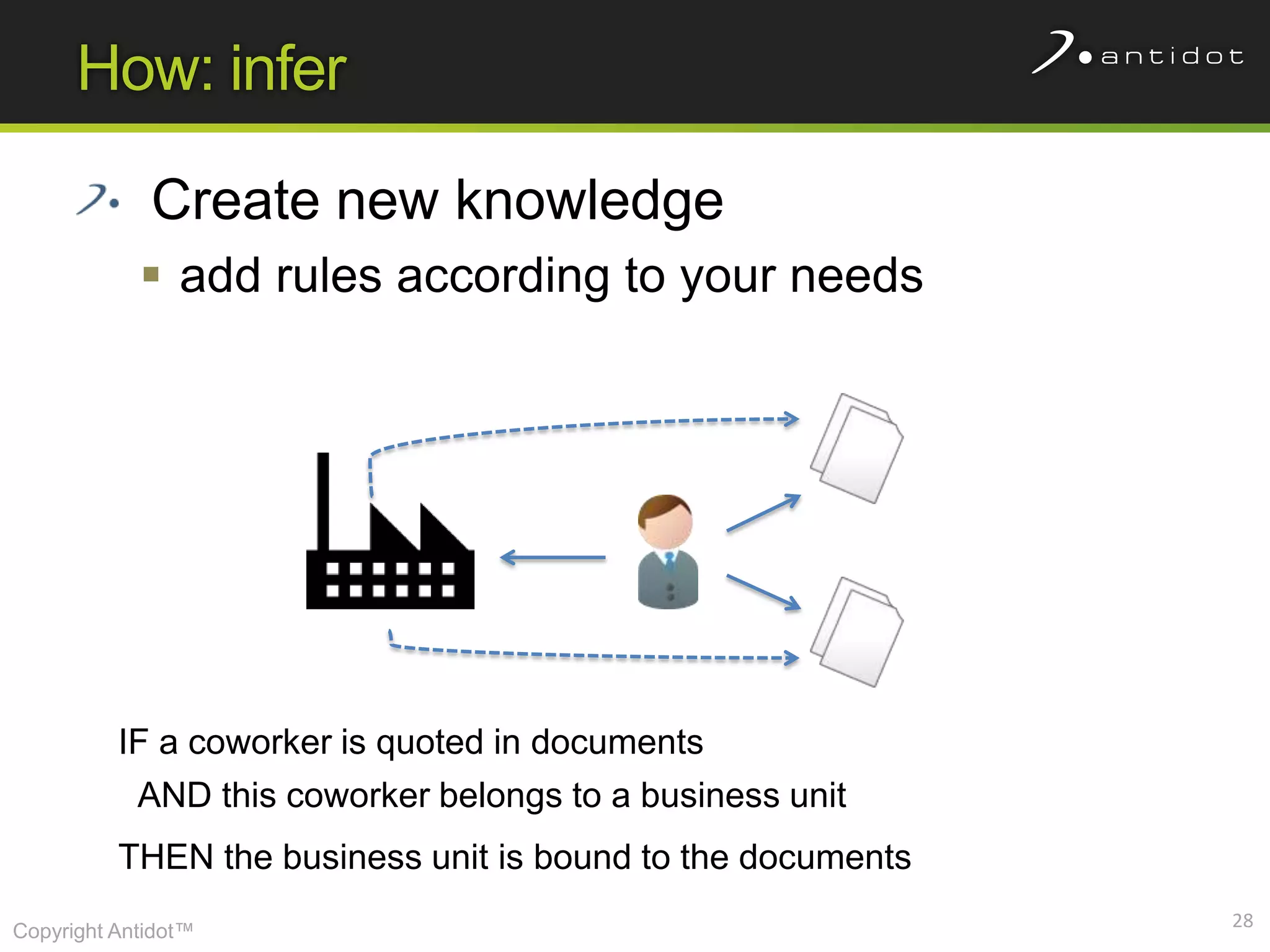
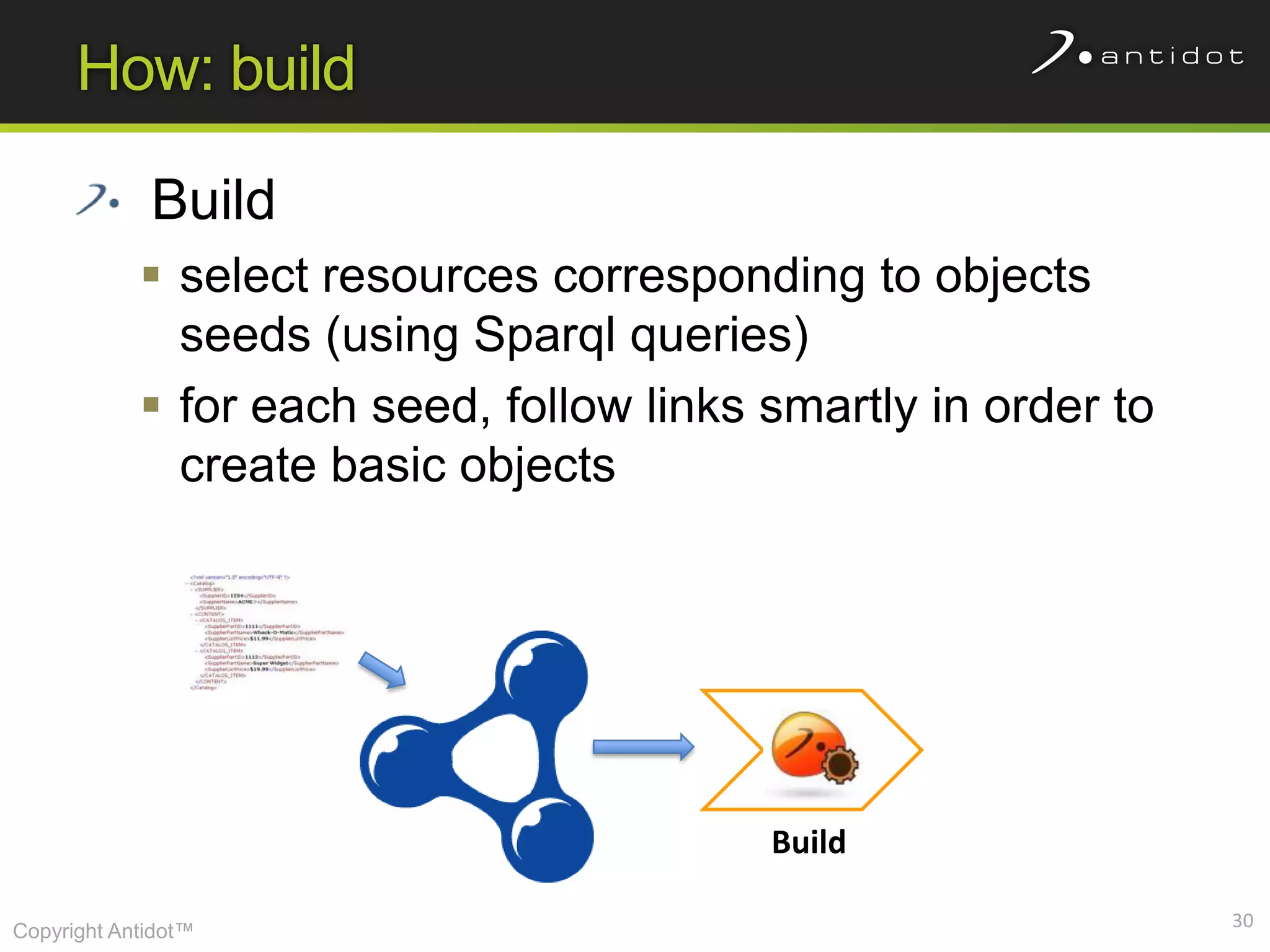
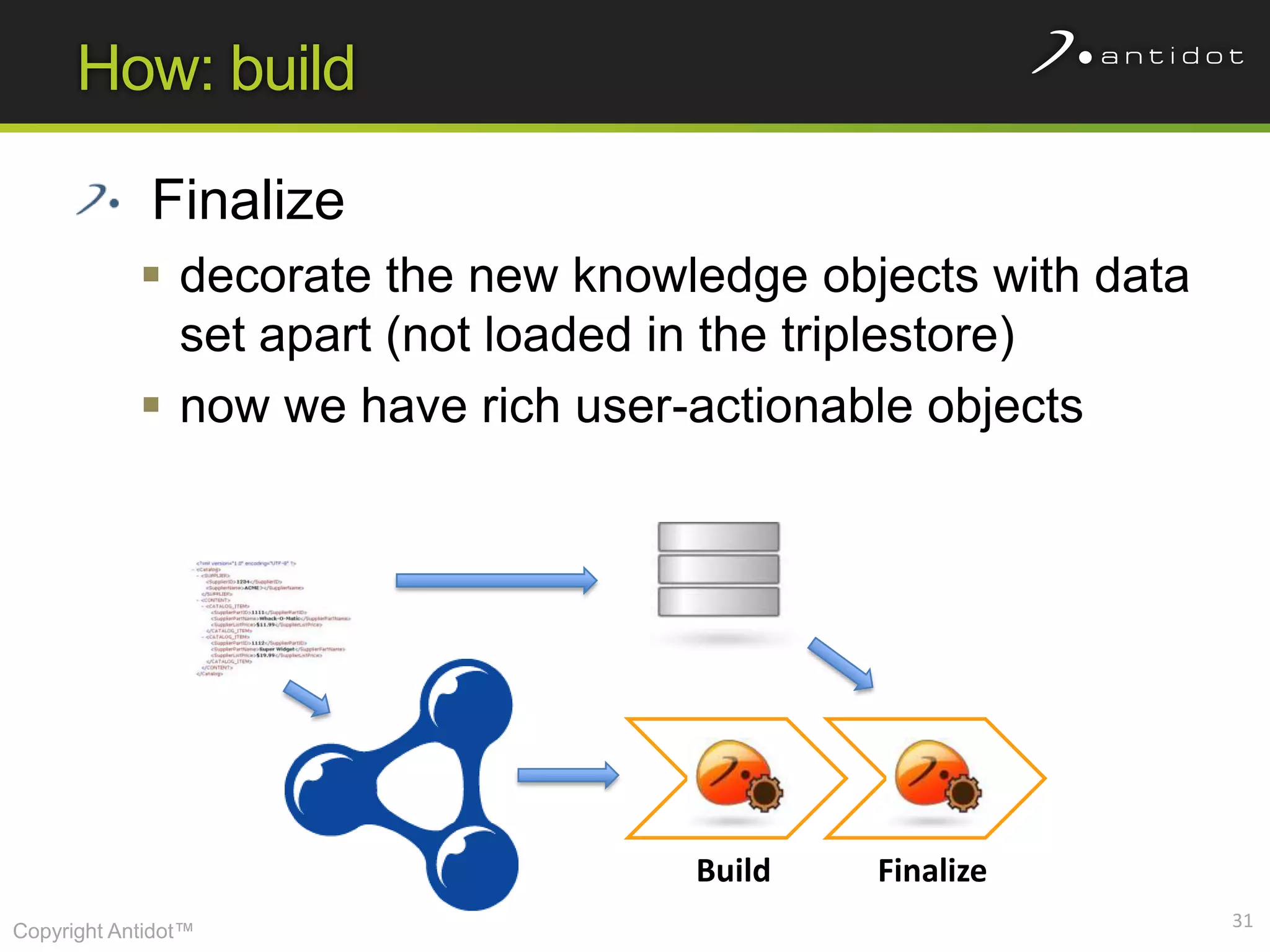
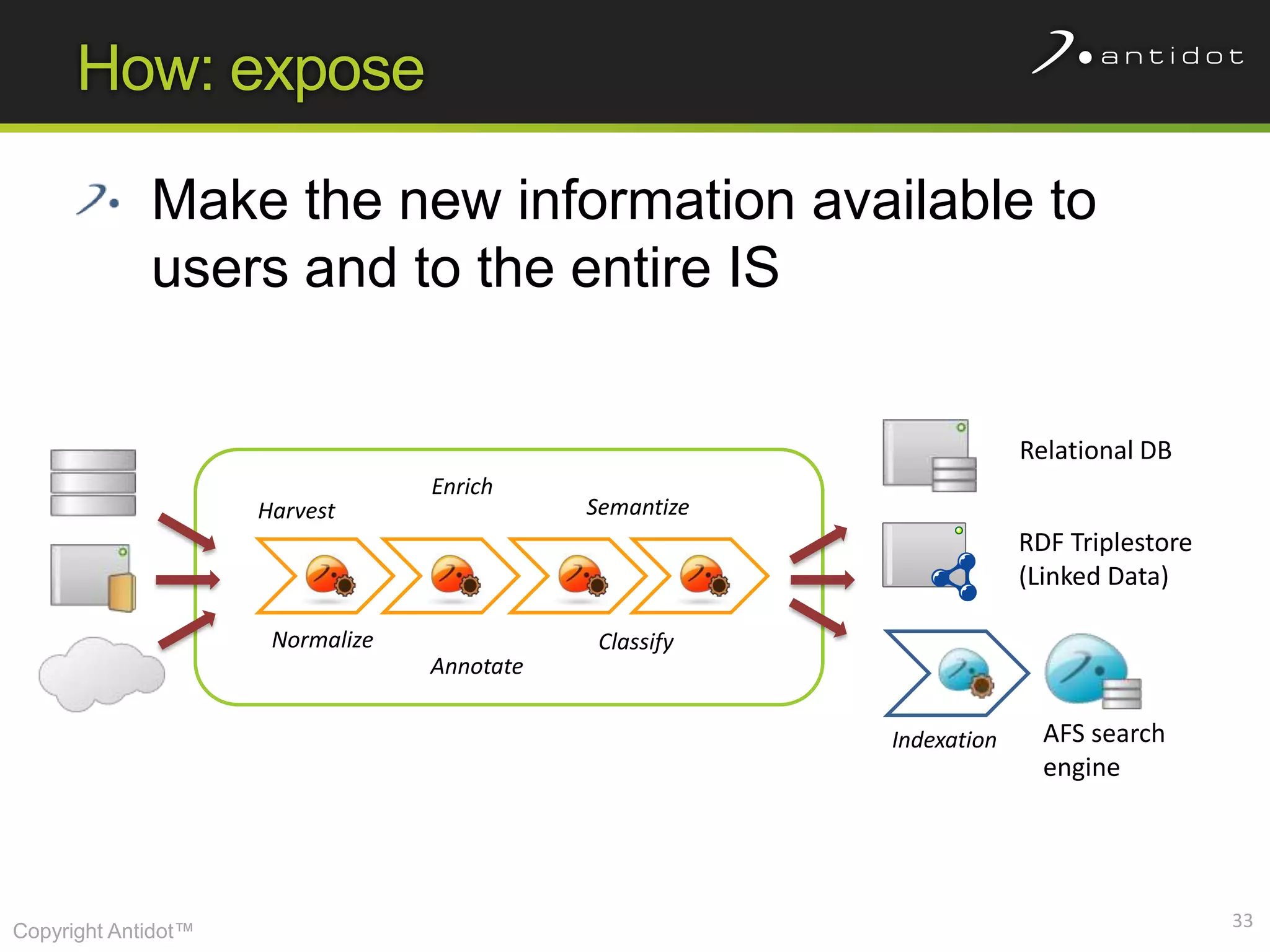

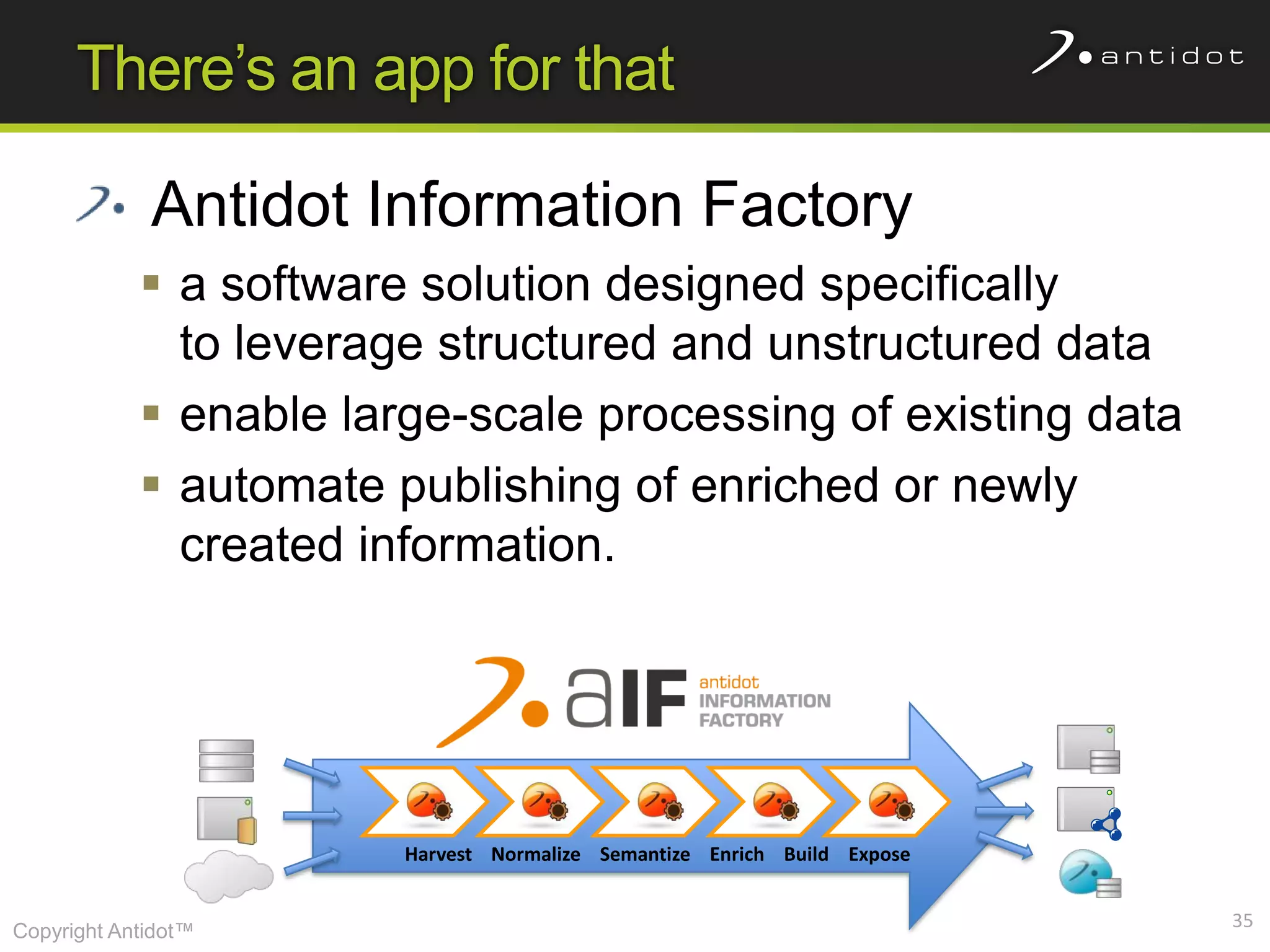



The document discusses leveraging semantic web technologies and linked data principles within corporate environments to improve data management and create value from both structured and unstructured data. It emphasizes transitioning from application-centric to data-centric approaches and constructing an enterprise graph by generating triples from various data sources. The conclusion highlights the feasibility of integrating semantic web frameworks to facilitate agile and dynamic data processing.





































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












