Downloaded 21 times


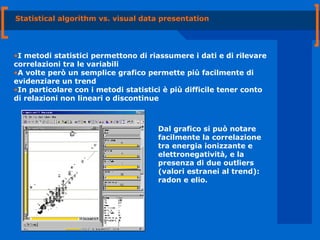


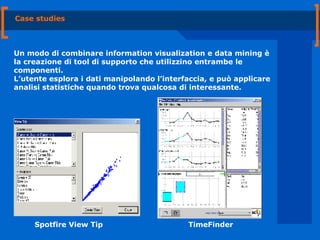


Il documento tratta dell'integrazione tra visualizzazione delle informazioni e data mining, evidenziando i metodi statistici e le visualizzazioni grafiche per identificare trend e pattern nei dati. Viene discussa l'importanza di combinare analisi esploratorie e ipotesi, oltre a fornire strumenti di supporto che facilitino la scoperta automatica di pattern interessanti. Si raccomanda di progettare strumenti intuitivi e comprensibili, tenendo conto del contesto sociale degli utenti.

































