What you willlearn in this Subject in ML?
• What is Machine Learning (ML)?
• What are the different forms of ML?
• What is ML used for?
• What is difference between machine learning and artificial intelligence?
• How Machine Learning works?
• What is classification and Regression?
• What is linear and logistic regression?
• What is gradient descent?
• What is clustering algorithms?
What is Learning?
•a process that leads to change, which occurs as a result of experience
and increases the potential for improved performance and future
learning.
• If an expert system--brilliantly designed, engineered and
implemented--cannot learn not to repeat its mistakes, it is not as
intelligent as a worm or a sea anemone or a kitten.
6.
What is ML?
•Over the past few years, Machine Learning has become the center of focus
in the field of information technology and is a part of human life as well.
• As data is increasing day by day, strong and smart data analysis has become
a need for all technological processes.
• Machine Learning is a key to the problems where we don’t want to invent
the code for every new application.
• With machine learning, we somewhat form prototypes to reduce the range
of different kinds of problems.
• Some of the well-known applications that we see around include speech
recognition, self-driving cars, web search recommendations, etc.
7.
What is ML?
•Thus, the central idea of machine learning is to build computer
programs that perform certain jobs (tasks) which when fed with data,
can learn automatically from that data by themselves (experience)
and improve their performance (performance).
• This performance is improved with experience. It is an iterative
process.
8.
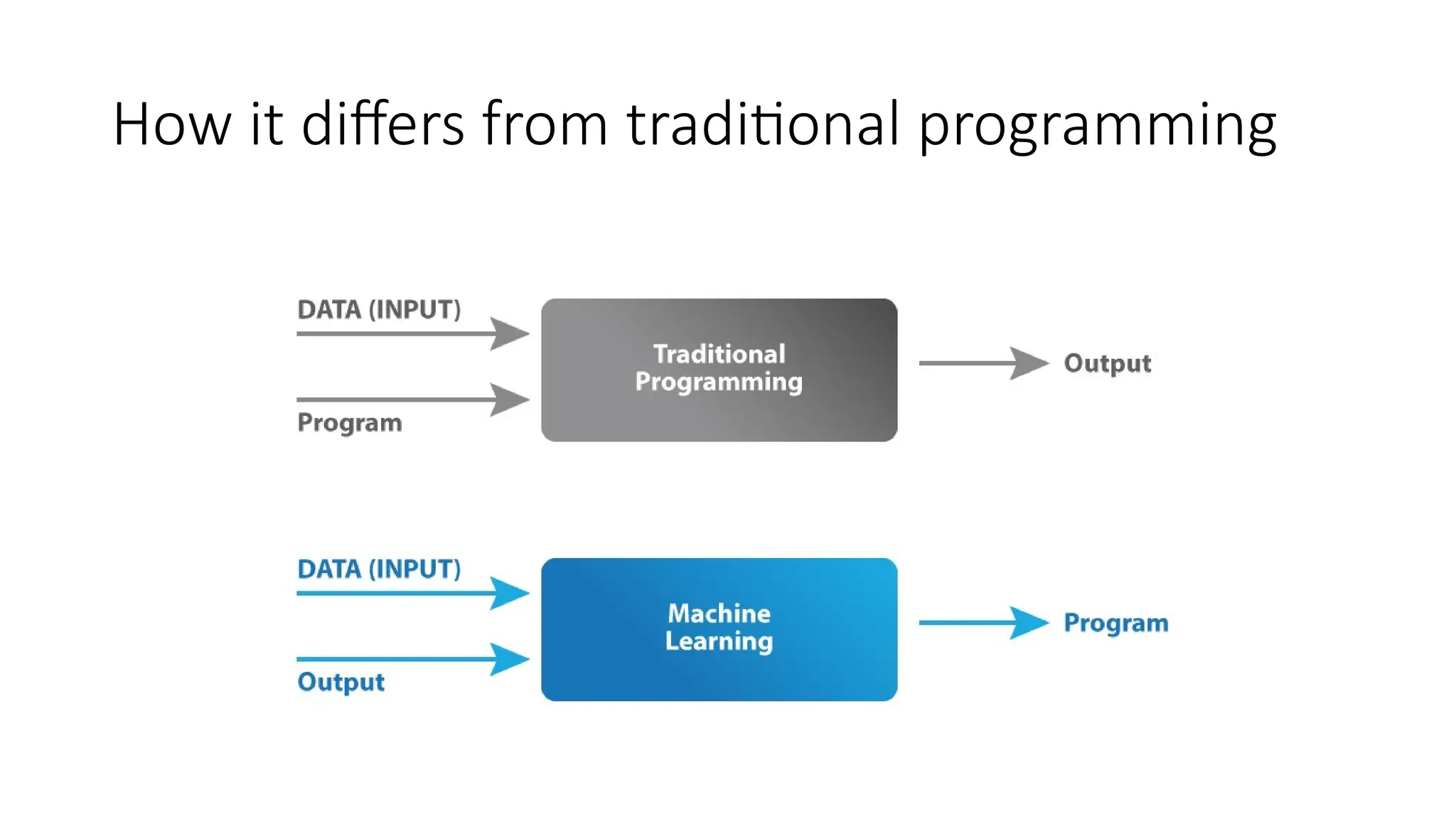
What is ML?
•Machine learning is a subfield of artificial intelligence that gives
computers the ability to learn without explicitly being programmed.
• The goal of AI is to create computer models that exhibit “intelligent
behaviors” like humans, according to Boris Katz, a principal research
scientist and head of the InfoLab Group at CSAIL. This means
machines that can recognize a visual scene, understand a text written
in natural language, or perform an action in the physical world.
• Machine learning is one way to use AI. It was defined in the 1950s by
AI pioneer Arthur Samuel as “the field of study that gives computers
the ability to learn without explicitly being programmed.”
9.
Formal Definition ofML
• Tom Mitchell provides a more modern definition: “A
computer program is said to learn from experience E with
respect to some class of tasks T and performance measure
P, if its performance at tasks in T, as measured by P,
improves with experience E.”
10.
Formal Definition ofML
• The Task, T
• If we want a robot to be able to walk, then walking is the task.
• “Learning is our means of attaining the ability to perform the
task”
• We could program the robot to learn to walk, or we could directly
write a program that specifies how to walk manually.
11.
Formal Definition ofML
• The Performance Measure, P
• In order to evaluate a machine learning algorithm, we must measure its
performance.
• For tasks such as classification, we often measure the accuracy of the model.
• Accuracy is just the proportion of examples for which the model produces the
correct output.
12.
Formal Definition ofML
• The Experience, E
• Machine learning algorithms can be broadly categorized as
unsupervised or supervised by what kind of experience they are
allowed to have during the learning process.
• Unsupervised learning algorithms experience a dataset containing
many features, then learn useful properties of the structure of this
dataset.
• Supervised learning algorithms experience a dataset containing
features, but each example is also associated with a label or target.
13.
Example
• Take theevery-day case of the decision problem of discriminating spam
email from non-spam email.
• How would you write a program to filter emails as they come into your
email account and decide to put them in the spam folder or the inbox
folder?
• In our spam/non-spam example, the examples (E) are emails we have
collected. The task (T) was a decision problem (called classification) of
marking each email as spam or not, and putting it in the correct folder.
Our performance measure (P) would be something like accuracy as a
percentage (correct decisions divided by total decisions made multiplied
by 100) between 0% (worst) and 100% (best).
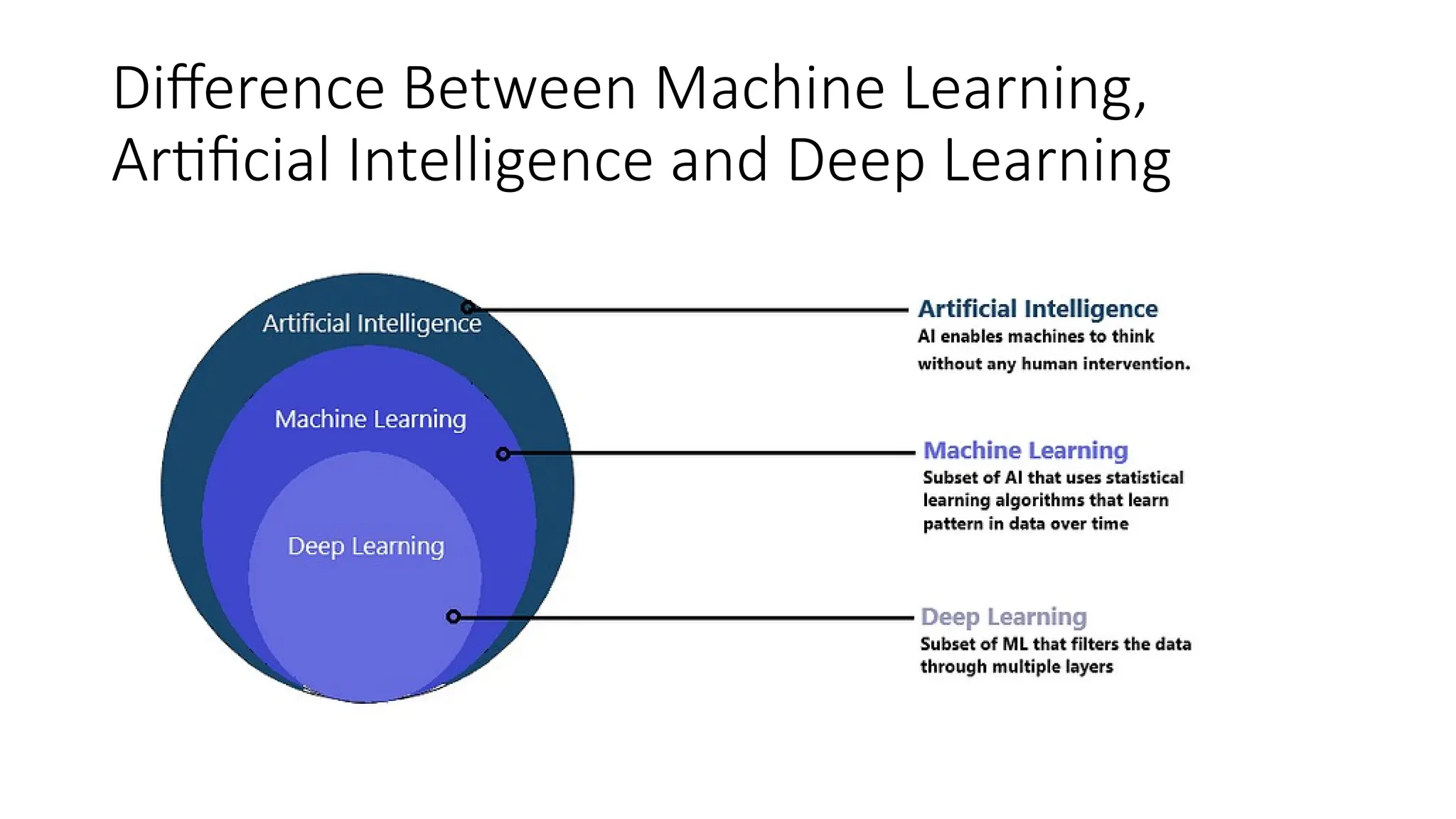
Difference Between MachineLearning,
Artificial Intelligence and Deep Learning
Concept Definition
Artificial intelligence
The field of computer science aims to
create intelligent machines that can think
and function like humans.
Machine learning
A subfield of artificial intelligence that
focuses on developing algorithms and
models that can learn from data rather
than being explicitly programmed.
Deep learning
A subfield of machine learning that uses
multi-layered artificial neural networks to
learn complex patterns in data.
16.
• How AIcan save our humanity | Kai-Fu Lee: https://youtu.be/ajGgd9Ld-Wc
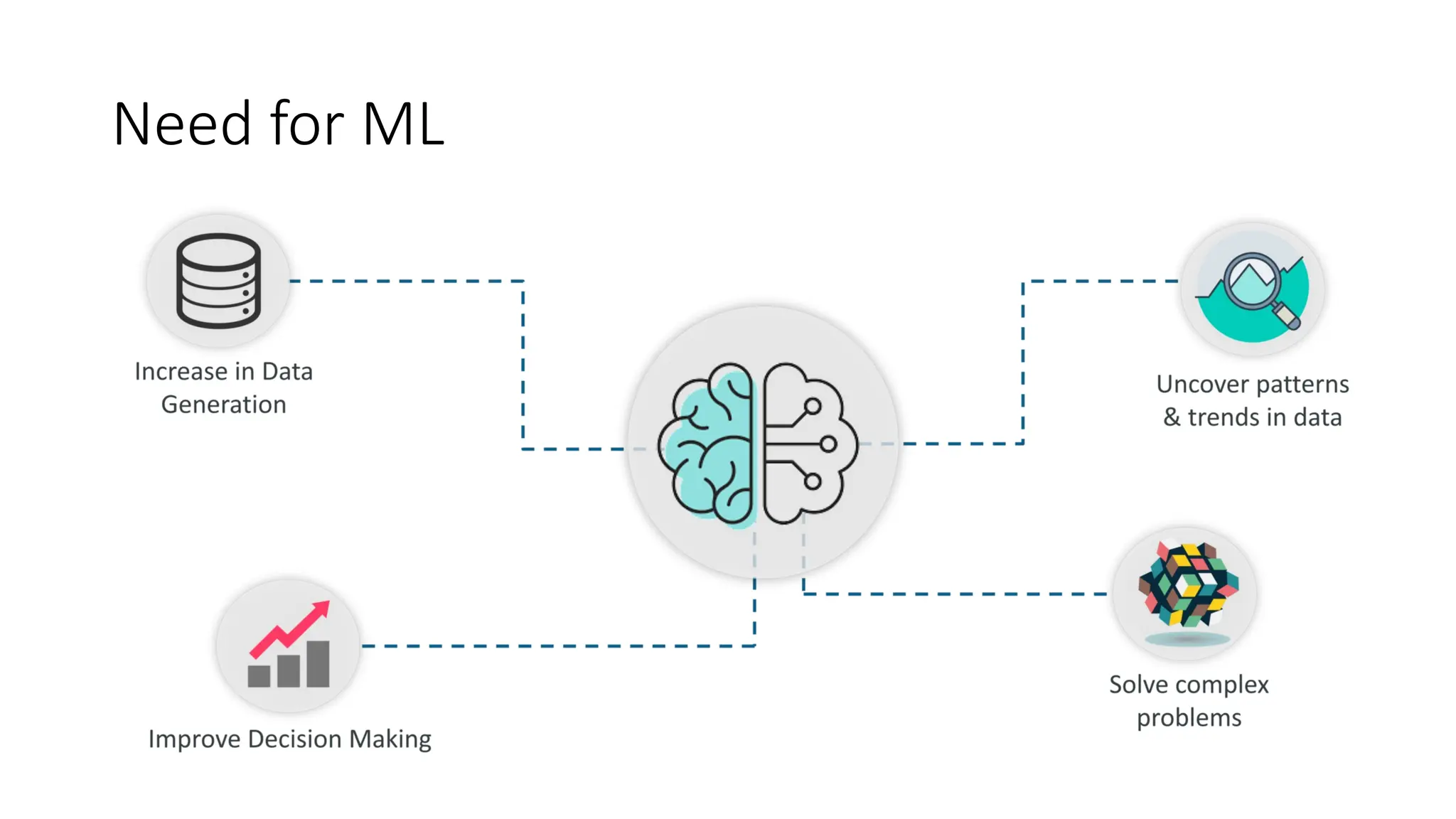
Need for ML
•Ever since the technical revolution, we’ve been generating an
immeasurable amount of data. As per research, we generate around 2.5
quintillion bytes of data every single day! It is estimated that by 2020,
1.7MB of data will be created every second for every person on earth.
• With the availability of so much data, it is finally possible to build
predictive models that can study and analyze complex data to find
useful insights and deliver more accurate results.
• Top Tier companies such as Netflix and Amazon build such Machine
Learning models by using tons of data in order to identify profitable
opportunities and avoid unwanted risks.
Need for ML
•Increasein Data Generation: Due to excessive production of data, we need a
method that can be used to structure, analyze and draw useful insights from
data. This is where Machine Learning comes in. It uses data to solve problems
and find solutions to the most complex tasks faced by organizations.
•Improve Decision Making: By making use of various algorithms, Machine
Learning can be used to make better business decisions. For example, Machine
Learning is used to forecast sales, predict downfalls in the stock market, identify
risks and anomalies, etc.
22.
Need for ML
•Uncoverpatterns & trends in data: Finding hidden patterns and extracting key
insights from data is the most essential part of Machine Learning. By building
predictive models and using statistical techniques, Machine Learning allows you
to dig beneath the surface and explore the data at a minute scale.
Understanding data and extracting patterns manually will take days, whereas
Machine Learning algorithms can perform such computations in less than a
second.
•Solve complex problems: From detecting the genes linked to the deadly ALS
disease to building self-driving cars, Machine Learning can be used to solve the
most complex problems.
23.
Machine Learning Everywhere
•Someone who doesn't know anything about machine learning basics or Artificial
Intelligence (AI) may only think of robots or machines, as sci-movies portray it.
• But most people are unaware of how common machine learning basics are used
in our daily lives.
• Google
• Facebook
• Twitter
• With the growing ubiquity of machine learning, everyone in business is likely to
encounter it and will need some working knowledge about this field. A 2020
Deloitte survey found that 67% of companies are using machine learning, and
97% are using or planning to use it in the next year.
24.
Machine Learning Everywhere
•Netflix’s Recommendation Engine: The core of Netflix is its infamous recommendation
engine. Over 75% of what you watch is recommended by Netflix and these
recommendations are made by implementing Machine Learning.
• Facebook’s Auto-tagging feature: The logic behind Facebook’s DeepMind face verification
system is Machine Learning and Neural Networks. DeepMind studies the facial features in
an image to tag your friends and family.
• Amazon’s Alexa: The infamous Alexa, which is based on Natural Language Processing and
Machine Learning is an advanced level Virtual Assistant that does more than just play
songs on your playlist. It can book you an Uber, connect with the other IoT devices at
home, track your health, etc.
• Google’s Spam Filter: Gmail makes use of Machine Learning to filter out spam messages.
It uses Machine Learning algorithms and Natural Language Processing to analyze emails in
real-time and classify them as either spam or non-spam.
25.
Machine Learning Everywhere
•Automatic Language
Translation in Google Translate
• Faster route selection in Google
Map
• Driverless/Self-driving car
• Smartphone with face
recognition
• Speech Recognition
• Ads Recommendation System
• Netflix Recommendation
System
• Netflix Recommendation
System
• Auto friend tagging suggestion
in Facebook
• Stock market trading
• Fraud Detection
• Weather Prediction
• Medical Diagnosis
• Chatbot
• Machine Learning in Agriculture
ML Terminology
• Model:Also known as “hypothesis”, a machine learning model is the
mathematical representation of a real-world process. A machine learning
algorithm along with the training data builds a machine learning model.
• Feature: A feature is a measurable property or parameter of the data-set.
• Feature Vector: It is a set of multiple numeric features. We use it as an
input to the machine learning model for training and prediction purposes.
• Training: An algorithm takes a set of data known as “training data” as
input. The learning algorithm finds patterns in the input data and trains
the model for expected results (target). The output of the training process
is the machine learning model.
28.
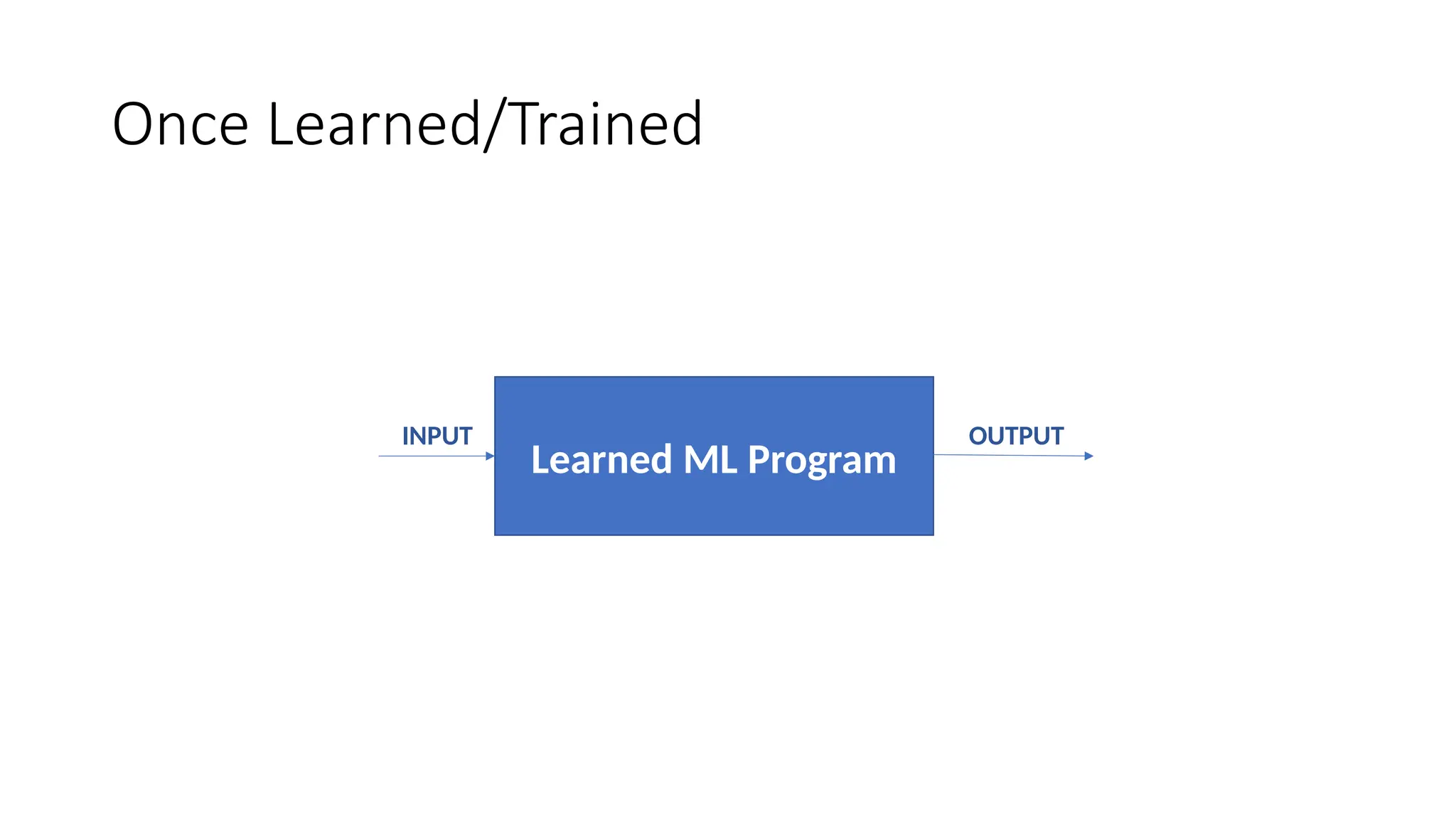
ML Terminology
• Prediction:Once the machine learning model is ready, it can be fed with
input data to provide a predicted output.
• Target (Label): The value that the machine learning model has to predict is
called the target or label.
• Overfitting: When a massive amount of data trains a machine learning
model, it tends to learn from the noise and inaccurate data entries. Here the
model fails to characterize the data correctly.
• Underfitting: It is the scenario when the model fails to decipher the
underlying trend in the input data. It destroys the accuracy of the machine
learning model. In simple terms, the model or the algorithm does not fit the
data well enough.
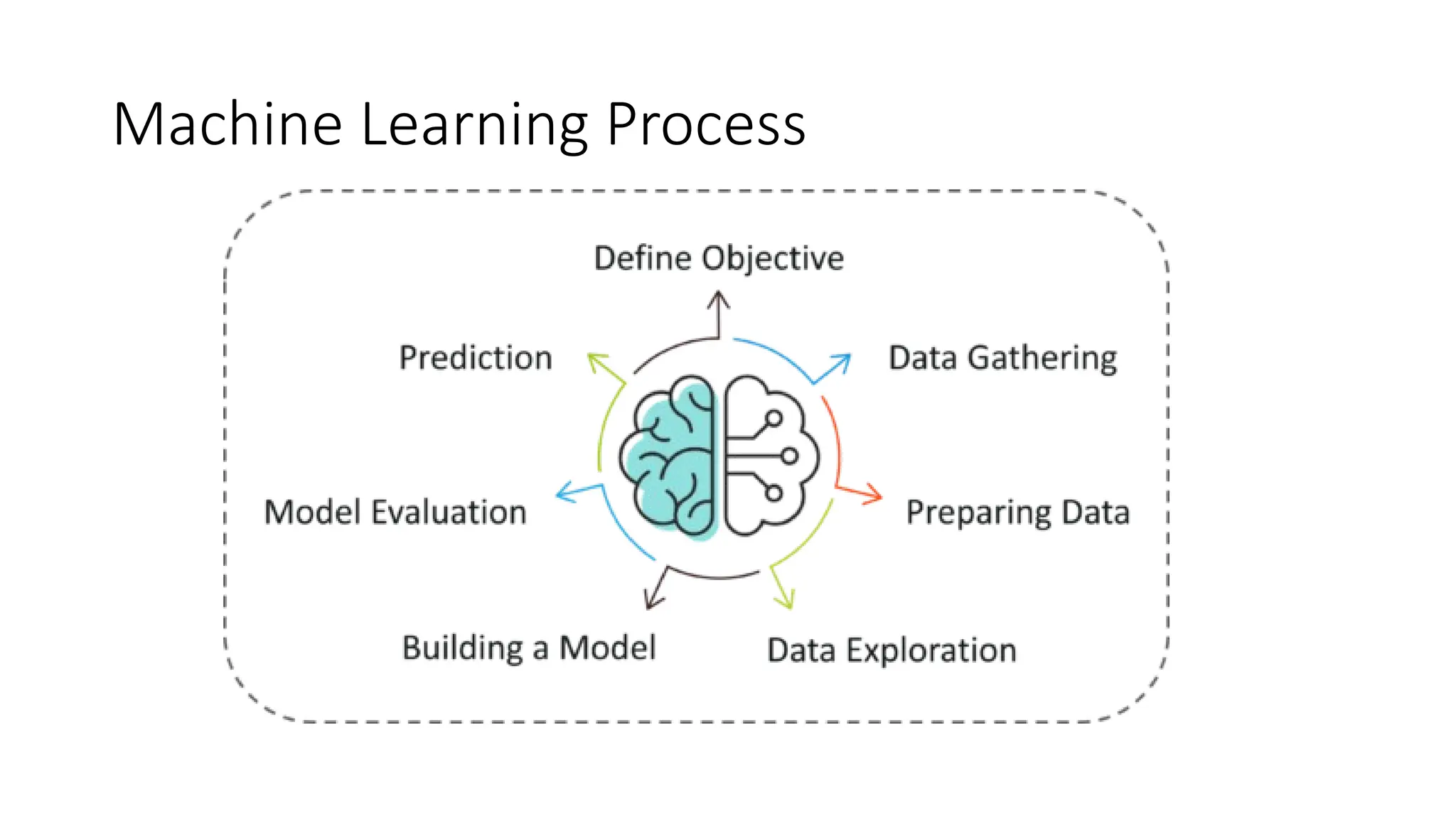
Machine Learning LifeCycle
Step 1: Define the objective of the Problem Statement
• At this step, we must understand what exactly needs to be predicted.
• For example, the objective is to predict the possibility of rain by studying weather
conditions.
• At this stage, it is also essential to take mental notes on what kind of data can be used
to solve this problem or the type of approach you must follow to get to the solution.
34.
Machine Learning LifeCycle
Step 1: Define the objective of the Problem Statement
• At this step, we must understand what exactly needs to be predicted.
• For example, the objective is to predict the possibility of rain by studying weather
conditions.
• At this stage, it is also essential to take mental notes on what kind of data can be used
to solve this problem or the type of approach you must follow to get to the solution.
Step 2: Data Gathering
35.
Machine Learning LifeCycle
Step 1: Define the objective of the Problem Statement
• At this step, we must understand what exactly needs to be predicted.
• For example, the objective is to predict the possibility of rain by studying weather
conditions.
• At this stage, it is also essential to take mental notes on what kind of data can be used
to solve this problem or the type of approach you must follow to get to the solution.
Step 2: Data Gathering
• At this stage, you must be asking questions such as,
• What kind of data is needed to solve this problem?
• Is the data available?
• How can I get the data?
• Once you know the types of data that is required, you must understand how you can
derive this data. Data collection can be done manually or by web scraping.
Machine Learning LifeCycle
Step 3: Data Preparation
• The data you collected is almost never in the right format. You will encounter a lot of
inconsistencies in the data set such as missing values, redundant variables, duplicate
values, etc.
• Removing such inconsistencies is very essential because they might lead to wrongful
computations and predictions.
• Therefore, at this stage, you scan the data set for any inconsistencies and you fix them
then and there.
Machine Learning LifeCycle
Step 4: Exploratory Data Analysis
• EDA or Exploratory Data Analysis is the brainstorming stage of Machine Learning.
• Data Exploration involves understanding the patterns and trends in the data. At this
stage, all the useful insights are drawn and correlations between the variables are
understood.
• For example, in the case of predicting rainfall, we know that there is a strong possibility
of rain if the temperature has fallen low. Such correlations must be understood and
mapped at this stage.
Machine Learning LifeCycle
Step 5: Building a Machine Learning Model
• All the insights and patterns derived during Data Exploration are used to build the
Machine Learning Model.
• This stage always begins by splitting the data set into two parts, training data, and
testing data.
• The training data will be used to build and analyze the model. The logic of the model is
based on the Machine Learning Algorithm that is being implemented.
• In the case of predicting rainfall, since the output will be in the form of True (if it will rain
tomorrow) or False (no rain tomorrow), we can use a Classification Algorithm such as
Logistic Regression.
• Choosing the right algorithm depends on the type of problem you’re trying to solve, the
data set and the level of complexity of the problem.
Machine Learning LifeCycle
Step 6: Model Evaluation & Optimization
• After building a model by using the training data set, it is finally time to put the model to
a test.
• The testing data set is used to check the efficiency of the model and how accurately it
can predict the outcome.
• Once the accuracy is calculated, any further improvements in the model can be
implemented at this stage.
• Methods like parameter tuning and cross-validation can be used to improve the
performance of the model.
Machine Learning LifeCycle
Step 7: Predictions
• Once the model is evaluated and improved, it is finally used to make predictions.
• The final output can be a Categorical variable (eg. True or False) or it can be a
Continuous Quantity (eg. the predicted value of a stock).
• In our case, for predicting the occurrence of rainfall, the output will be a categorical
variable.
46.
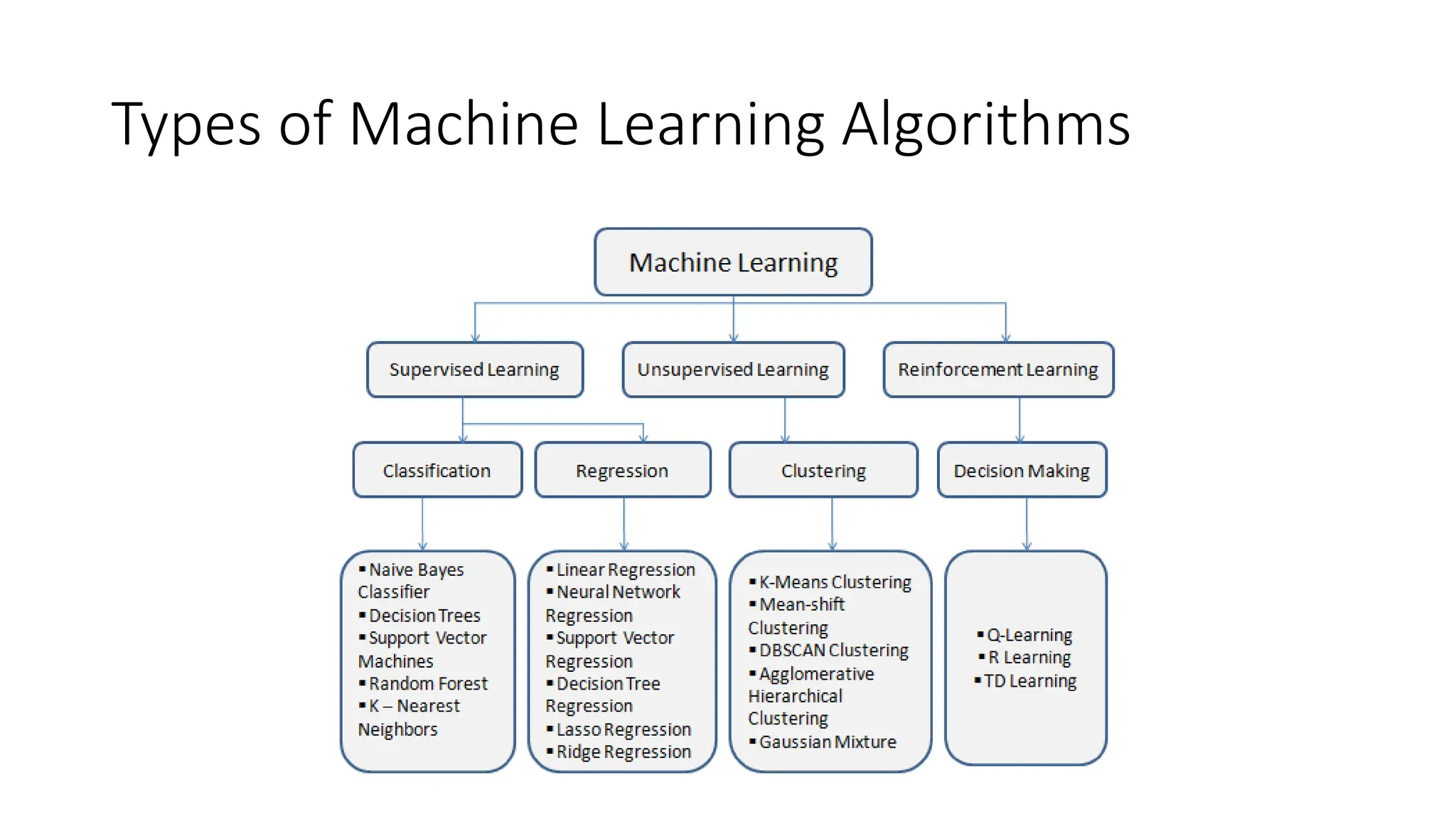
Types of MachineLearning
• There are main 3 types:
• Supervised ML
• Unsupervised ML
• Reinforcement ML
Supervised ML
• Supervisedlearning is a class of problems that uses a model to learn
the mapping between the input and target variables.
• Applications consisting of the training data describing the various
input variables and the target variable are known as supervised
learning tasks.
• Let the set of input variable be (x) and the target variable be (y). A
supervised learning algorithm tries to learn a hypothetical function
which is a mapping given by the expression y=f(x), which is a function
of x.
49.
Supervised ML
• Thelearning process here is monitored or supervised. Since we already
know the output the algorithm is corrected each time it makes a prediction,
to optimize the results.
• Models are fit on training data which consists of both the input and the
output variable and then it is used to make predictions on test data.
• Only the inputs are provided during the test phase and the outputs
produced by the model are compared with the kept back target variables
and is used to estimate the performance of the model.
• There are basically two types of supervised problems:
• Classification – which involves prediction of a class label
• Regression – that involves the prediction of a numerical value
50.
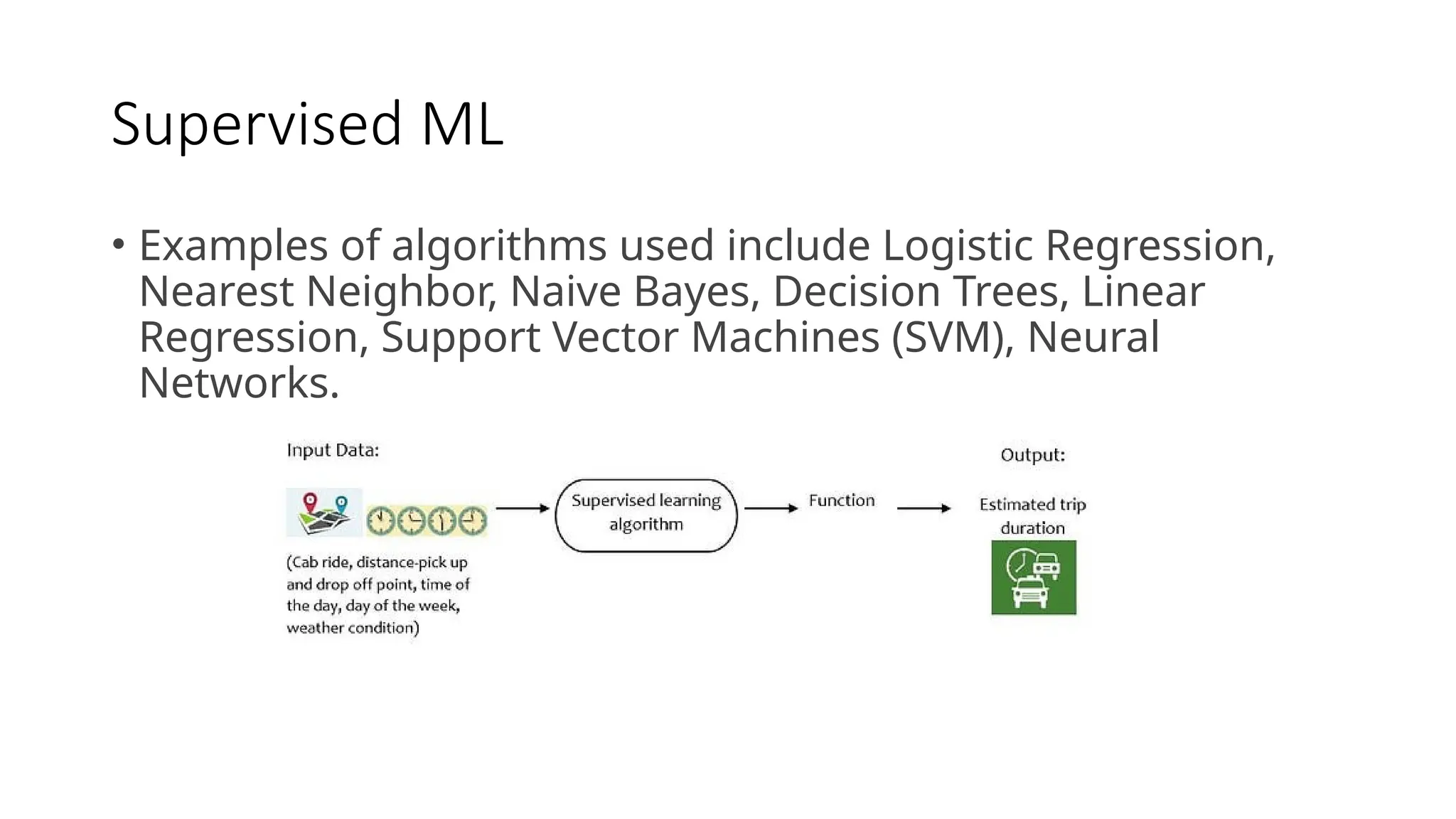
Supervised ML
• Examplesof algorithms used include Logistic Regression,
Nearest Neighbor, Naive Bayes, Decision Trees, Linear
Regression, Support Vector Machines (SVM), Neural
Networks.
51.
Unsupervised ML
• InUnsupervised learning, there is no prior information
about the data, hence the model tries to learn by itself and
recognize patterns and extract the relationships among the data.
• As in case of a supervised learning there is no supervisor or a teacher
to drive the model. Unsupervised learning operates only on the input
variables.
• There are no target variables to guide the learning process. The goal
here is to interpret the underlying patterns in the data in order to
obtain more proficiency over the underlying data.
52.
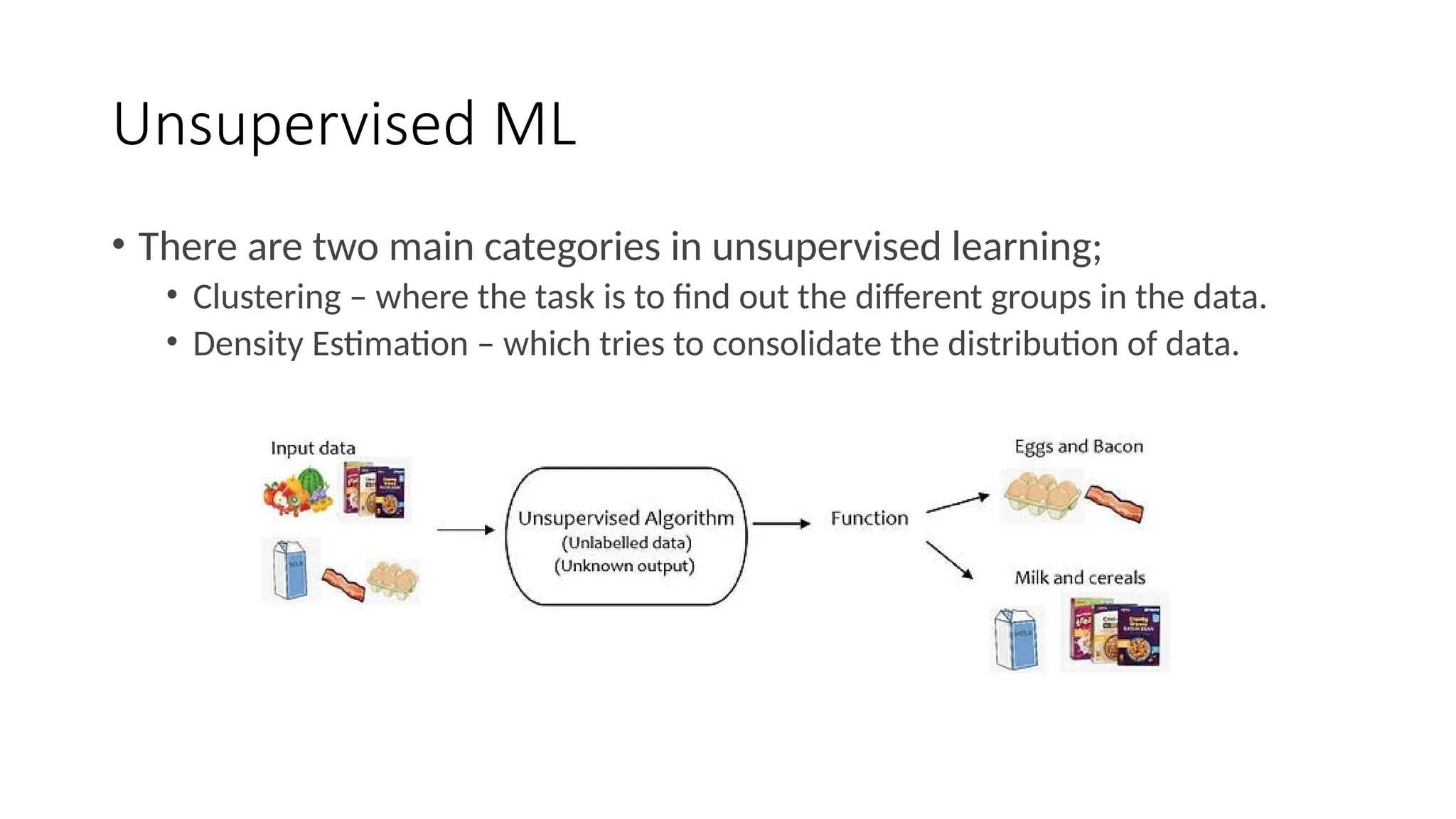
Unsupervised ML
• Thereare two main categories in unsupervised learning;
• Clustering – where the task is to find out the different groups in the data.
• Density Estimation – which tries to consolidate the distribution of data.
53.
Reinforcement Learning
• Reinforcementlearning is type a of problem where there is an agent
and the agent is operating in an environment based on the feedback
or reward given to the agent by the environment in which it is
operating.
• The rewards could be either positive or negative. The agent then
proceeds in the environment based on the rewards gained.
• The reinforcement agent determines the steps to perform a particular
task. There is no fixed training dataset here and the machine learns
on its own.
54.
Reinforcement Learning
• Playinga game is a classic example of a reinforcement problem,
where the agent’s goal is to acquire a high score.
• It makes the successive moves in the game based on the feedback
given by the environment which may be in terms of rewards or a
penalization.
55.
Semi-Supervised ML
• Thecost to label the data is quite expensive as it requires the
knowledge of skilled human experts.
• The input data is combination of both labeled and unlabelled data.
• The model makes the predictions by learning the underlying patterns
on their own.
• It is a mix of both classification and clustering problems.
56.
• How AICould Empower Any Business | Andrew Ng | TED: https://www.youtube.com/watch?v=reUZRyXxUs4
Regression
• Regression findscorrelations between dependent and independent
variables. Therefore, regression algorithms help predict continuous
variables such as house prices, market trends, weather patterns, oil and gas
prices (a critical task these days!), etc.
• The Regression algorithm’s task is finding the mapping function so we can
map the input variable of “x” to the continuous output variable of “y.”
• Examples:
• Weather forecasting
• House price prediction
• Loan amount prediction
• Car price prediction
59.
Regression Algorithms
• SimpleLinear Regression
• Multiple Linear Regression
• Polynomial Regression
• Support Vector Regression
• Decision Tree Regression
• Random Forest Regression
60.
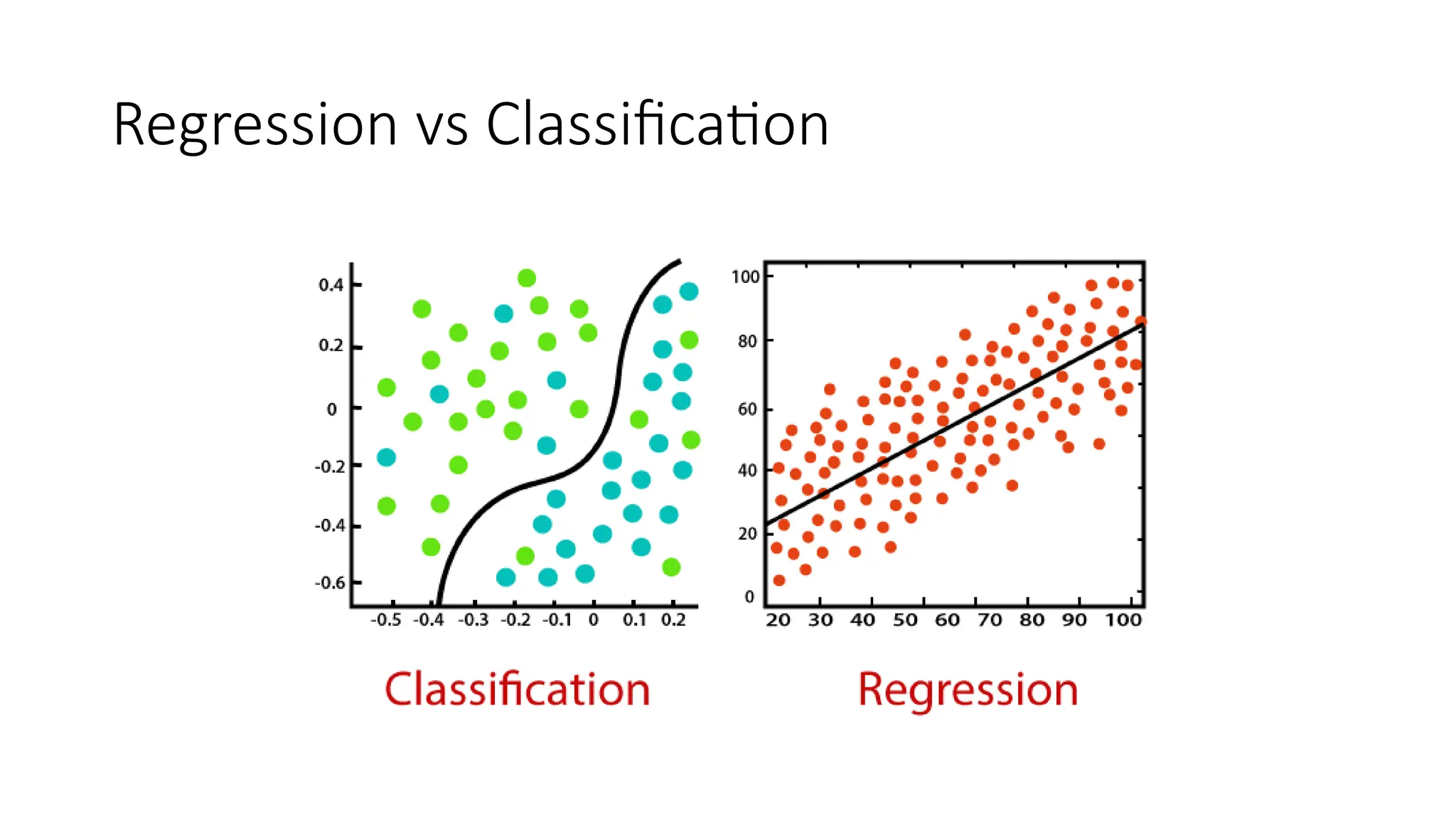
Classification
• On theother hand, Classification is an algorithm that finds functions that help divide
the dataset into classes based on various parameters.
• When using a Classification algorithm, a computer program gets taught on the training
dataset and categorizes the data into various categories depending on what it learned.
• Classification algorithms find the mapping function to map the “x” input to “y”
discrete output. The algorithms estimate discrete values (in other words, binary values
such as 0 and 1, yes and no, true or false, based on a particular set of independent
variables.
• To put it another, more straightforward way, classification algorithms predict an event
occurrence probability by fitting data to a logit function.
• Example: email and spam classification, predicting the willingness of bank customers
to pay their loans, and identifying cancer tumor cells.
61.
Classification Algorithms
• LogisticRegression
• K-Nearest Neighbors
• Support Vector Machines
• Kernel SVM
• Naïve Bayes
• Decision Tree Classification
• Random Forest Classification
62.
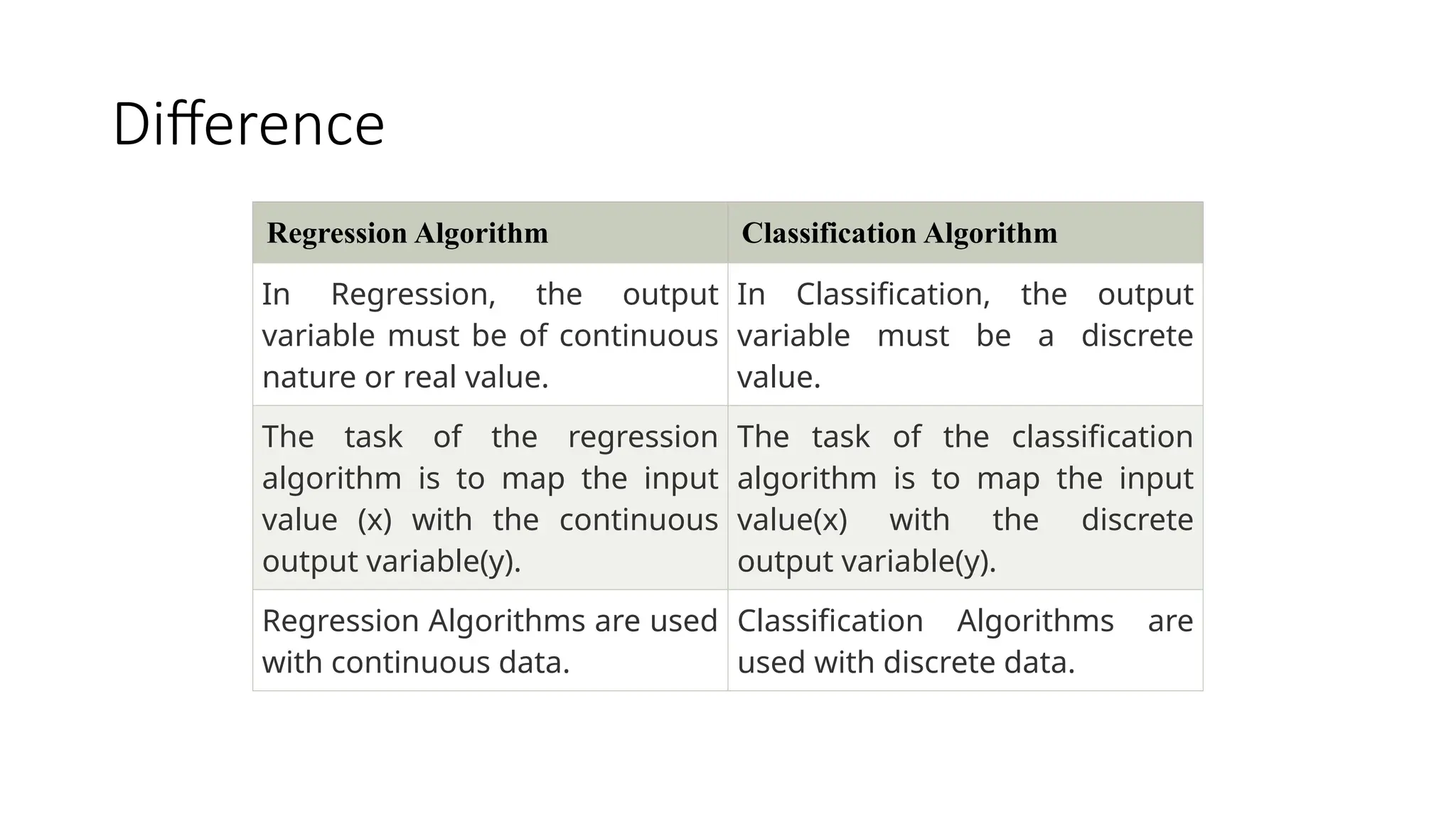
Difference
Regression Algorithm ClassificationAlgorithm
In Regression, the output
variable must be of continuous
nature or real value.
In Classification, the output
variable must be a discrete
value.
The task of the regression
algorithm is to map the input
value (x) with the continuous
output variable(y).
The task of the classification
algorithm is to map the input
value(x) with the discrete
output variable(y).
Regression Algorithms are used
with continuous data.
Classification Algorithms are
used with discrete data.
63.
Difference
Regression Algorithm ClassificationAlgorithm
In Regression, we try to find the
best fit line, which can predict
the output more accurately.
In Classification, we try to find
the decision boundary, which
can divide the dataset into
different classes.
Regression algorithms can be
used to solve the regression
problems such as Weather
Prediction, House price
prediction, etc.
Classification Algorithms can be
used to solve classification
problems such as Identification
of spam emails, Speech
Recognition, Identification of
cancer cells, etc.
The regression Algorithm can
be further divided into Linear
and Non-linear Regression.
The Classification algorithms
can be divided into Binary
Classifier and Multi-class
64.
Different Algorithms usedin ML
• Regression Algorithm
• Instance based algorithm
• Regularization
• Decision Tree
• Bayesian
• Clustering
• Association rule learning
• Artificial Neural Network (ANN)
• Deep Learning (DL)
• Dimensionality Reduction
• Ensemble
65.
Regression Algorithm
• Regressionis a process that is
concerned with identifying the
relationship between the target
output variables and the input
features to make predictions about
the new data. Top six Regression
algorithms are: Simple Linear
Regression, Lasso Regression,
Logistic regression, Multivariate
Regression algorithm, Multiple
Regression Algorithm.
66.
Instance-based Algorithms:
• Thesebelong to the family of learning that measures new
instances of the problem with those in the training data to
find out a best match and makes a prediction accordingly.
The top instance-based algorithms are: k-Nearest Neighbor,
Learning Vector Quantization, Self-Organizing Map, Locally
Weighted Learning, and Support Vector Machines.
67.
Regularization
• Regularization refersto the technique of regularizing the
learning process from a particular set of features. It
normalizes and moderates. The weights attached to the
features are normalized, which prevents in certain features
from dominating the prediction process. This technique
helps to prevent the problem of overfitting in machine
learning. The various regularization algorithms are Ridge
Regression, Least Absolute Shrinkage and Selection
Operator (LASSO) and Least-Angle Regression (LARS).
68.
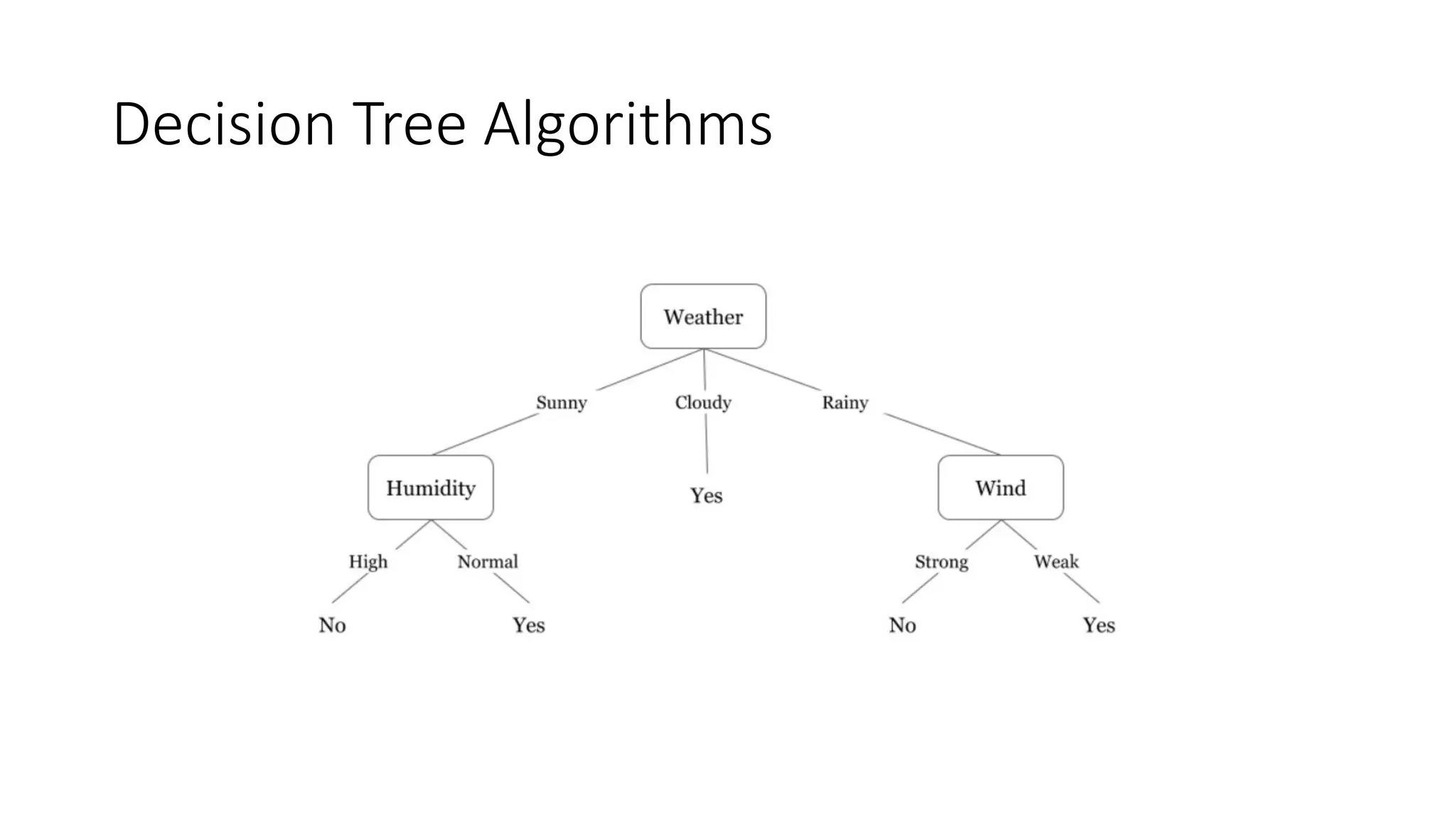
Decision Tree Algorithms
•These methods construct a tree-based model constructed
on the decisions made by examining the values of the
attributes. Decision trees are used for both classification and
regression problems. Some of the well-known decision tree
algorithms are: Classification and Regression Tree, C4.5 and
C5.0, Conditional Decision Trees, Chi-squared Automatic
Interaction Detection and Decision Stump.
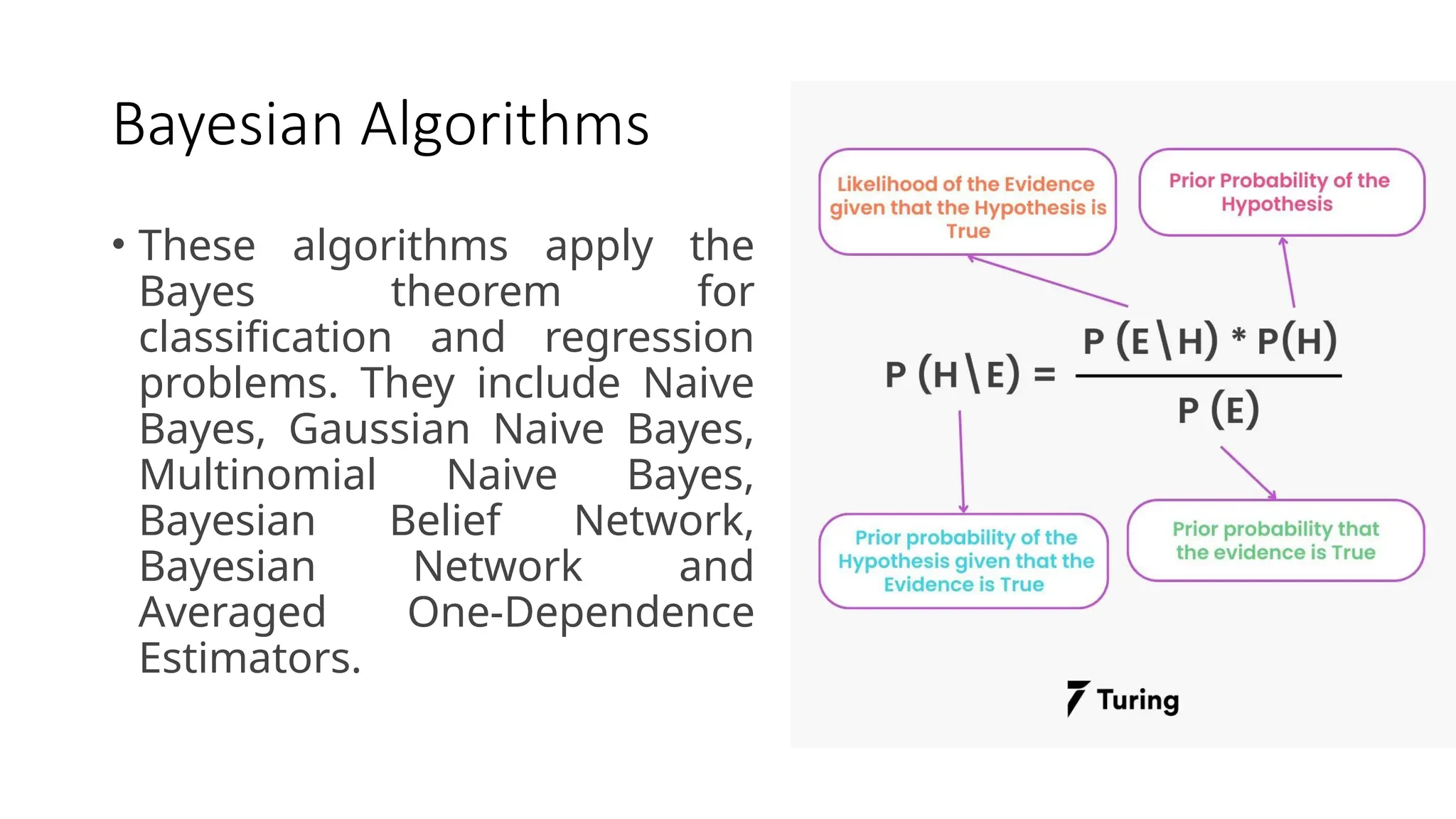
Bayesian Algorithms
• Thesealgorithms apply the
Bayes theorem for
classification and regression
problems. They include Naive
Bayes, Gaussian Naive Bayes,
Multinomial Naive Bayes,
Bayesian Belief Network,
Bayesian Network and
Averaged One-Dependence
Estimators.
73.
Clustering Algorithms
• Clusteringalgorithms involve the grouping of
data points into clusters. All the data points
that are in the same group share similar
properties and, data points in different groups
have highly dissimilar properties. Clustering is
an unsupervised learning approach and is
mostly used for statistical data analysis in
many fields. Algorithms like k-Means, k-
Medians, Expectation Maximisation,
Hierarchical Clustering, and Density-Based
Spatial Clustering of Applications with Noise
fall under this category.
74.
Association Rule LearningAlgorithms:
• Association rule learning is a rule-
based learning method for
identifying the relationships
between variables in a very large
dataset. Association Rule learning
is employed predominantly in
market basket analysis. The most
popular algorithms are: Apriori
algorithm and Eclat algorithm.
75.
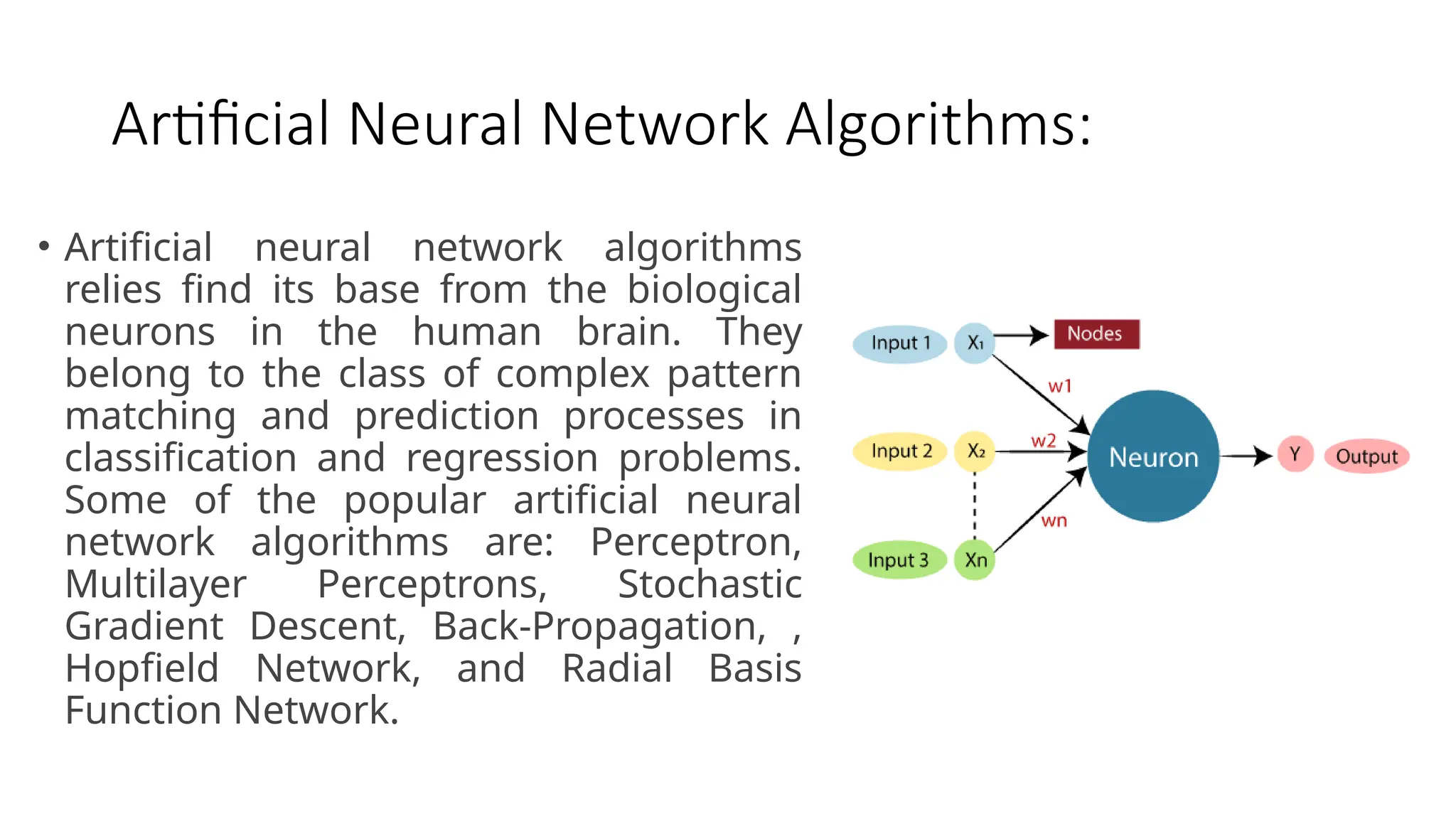
Artificial Neural NetworkAlgorithms:
• Artificial neural network algorithms
relies find its base from the biological
neurons in the human brain. They
belong to the class of complex pattern
matching and prediction processes in
classification and regression problems.
Some of the popular artificial neural
network algorithms are: Perceptron,
Multilayer Perceptrons, Stochastic
Gradient Descent, Back-Propagation, ,
Hopfield Network, and Radial Basis
Function Network.
76.
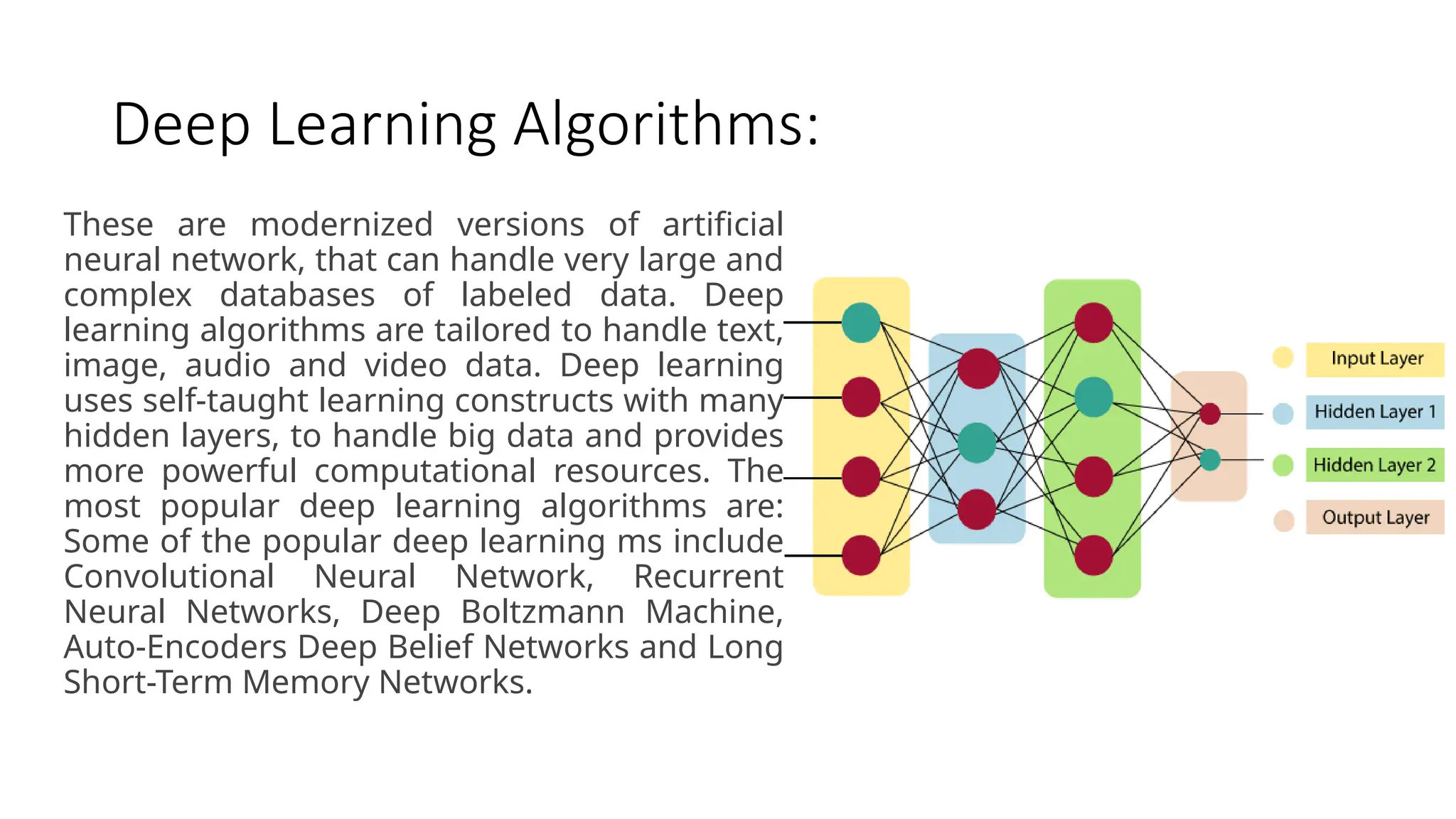
Deep Learning Algorithms:
Theseare modernized versions of artificial
neural network, that can handle very large and
complex databases of labeled data. Deep
learning algorithms are tailored to handle text,
image, audio and video data. Deep learning
uses self-taught learning constructs with many
hidden layers, to handle big data and provides
more powerful computational resources. The
most popular deep learning algorithms are:
Some of the popular deep learning ms include
Convolutional Neural Network, Recurrent
Neural Networks, Deep Boltzmann Machine,
Auto-Encoders Deep Belief Networks and Long
Short-Term Memory Networks.
78.
Dimensionality Reduction Algorithms:
DimensionalityReduction algorithms exploit the intrinsic structure of
data in an unsupervised manner to express data using reduced
information set. They convert a high dimensional data into a lower
dimension which could be used in supervised learning methods like
classification and regression. Some of the well known dimensionality
reduction algorithms include Principal Component Analysis, Principal
Component Regressio, Linear Discriminant Analysis,
Quadratic Discriminant Analysis, Mixture Discriminant Analysis,
Flexible Discriminant Analysis and Sammon Mapping.
• It is commonly used in the fields that deal with high-dimensional data, such as
speech recognition, signal processing, bioinformatics, etc. It can also be used for
data visualization, noise reduction, cluster analysis, etc.
79.
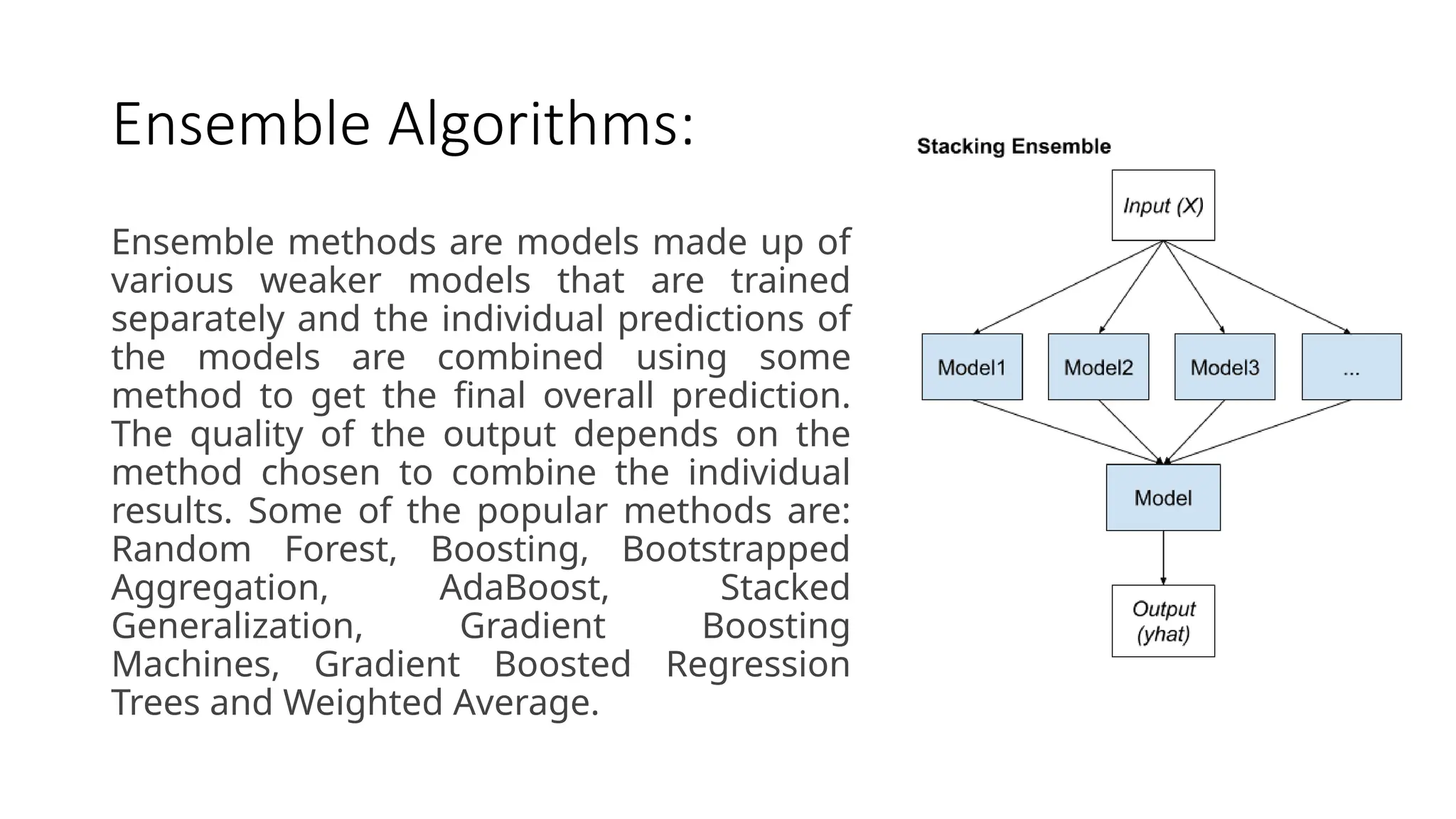
Ensemble Algorithms:
Ensemble methodsare models made up of
various weaker models that are trained
separately and the individual predictions of
the models are combined using some
method to get the final overall prediction.
The quality of the output depends on the
method chosen to combine the individual
results. Some of the popular methods are:
Random Forest, Boosting, Bootstrapped
Aggregation, AdaBoost, Stacked
Generalization, Gradient Boosting
Machines, Gradient Boosted Regression
Trees and Weighted Average.
80.
• Jobs weloose due to ML:
https://www.youtube.com/watch?v=gWmRkYsLzB4&list=PLobzMSC-r
aKifQd9vHHPkMam_jrQEyzCX&index=7
• How AI can enhance our memory, work and social lives:
https://youtu.be/DJMhz7JlPvA