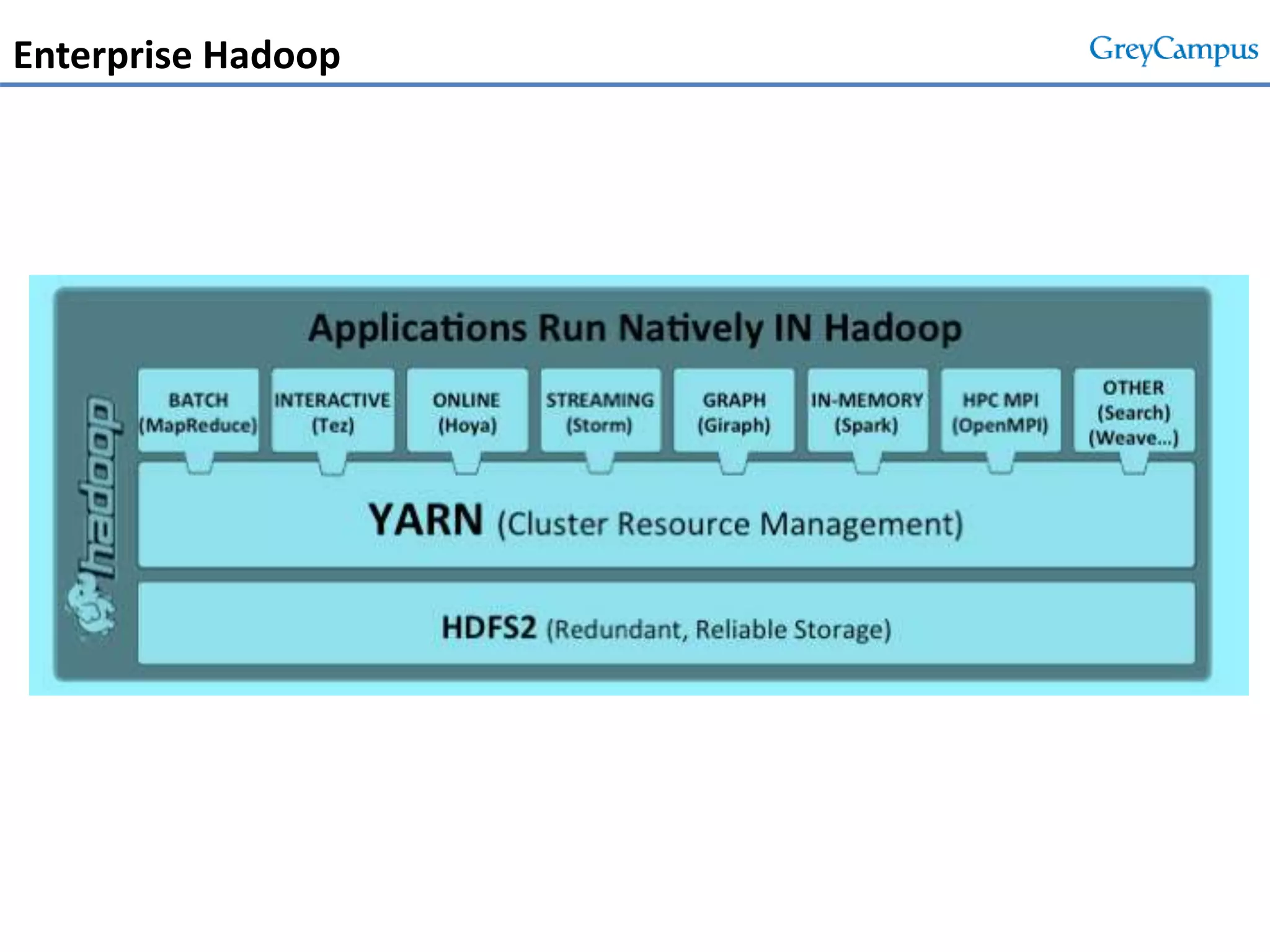
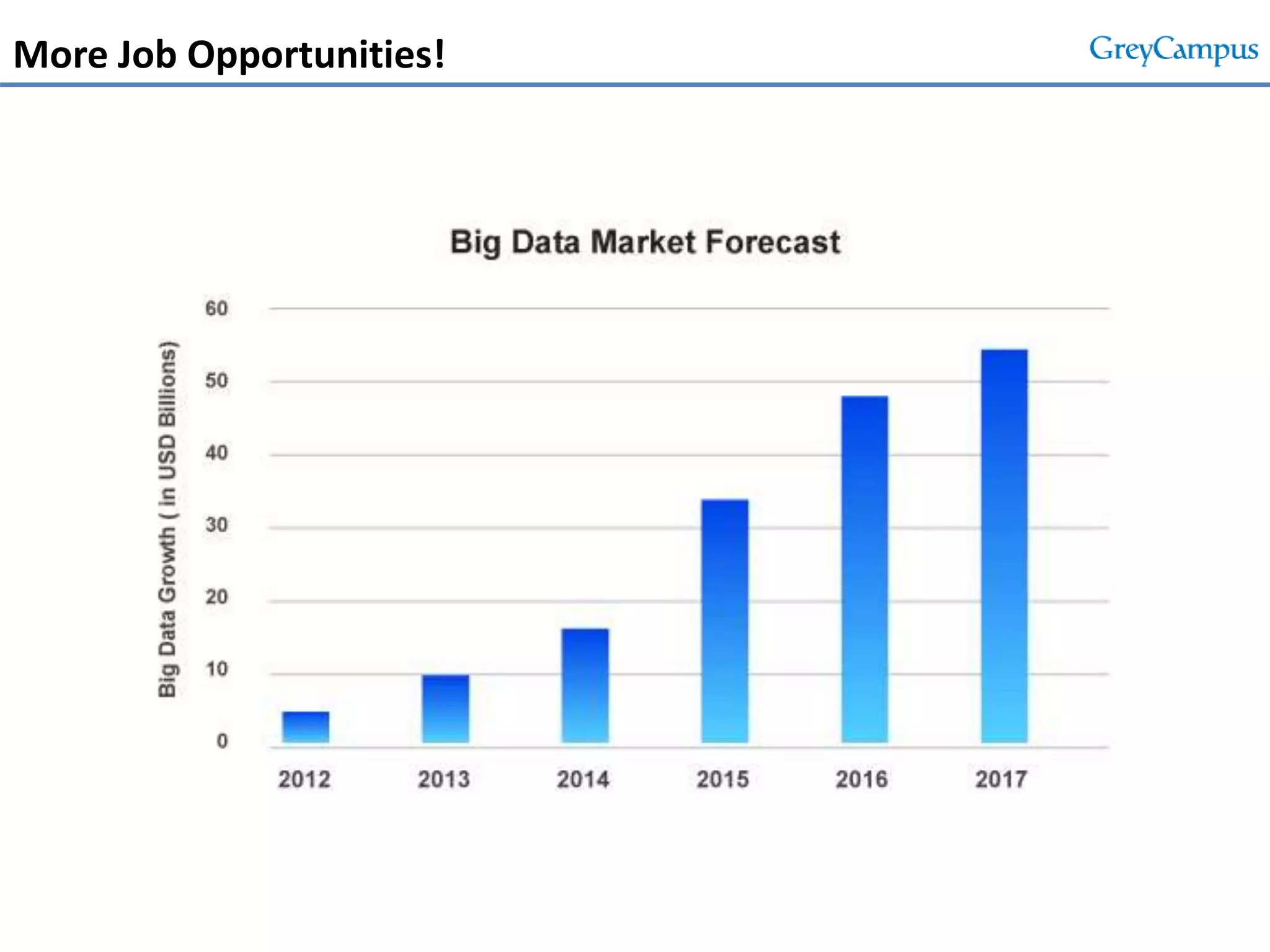
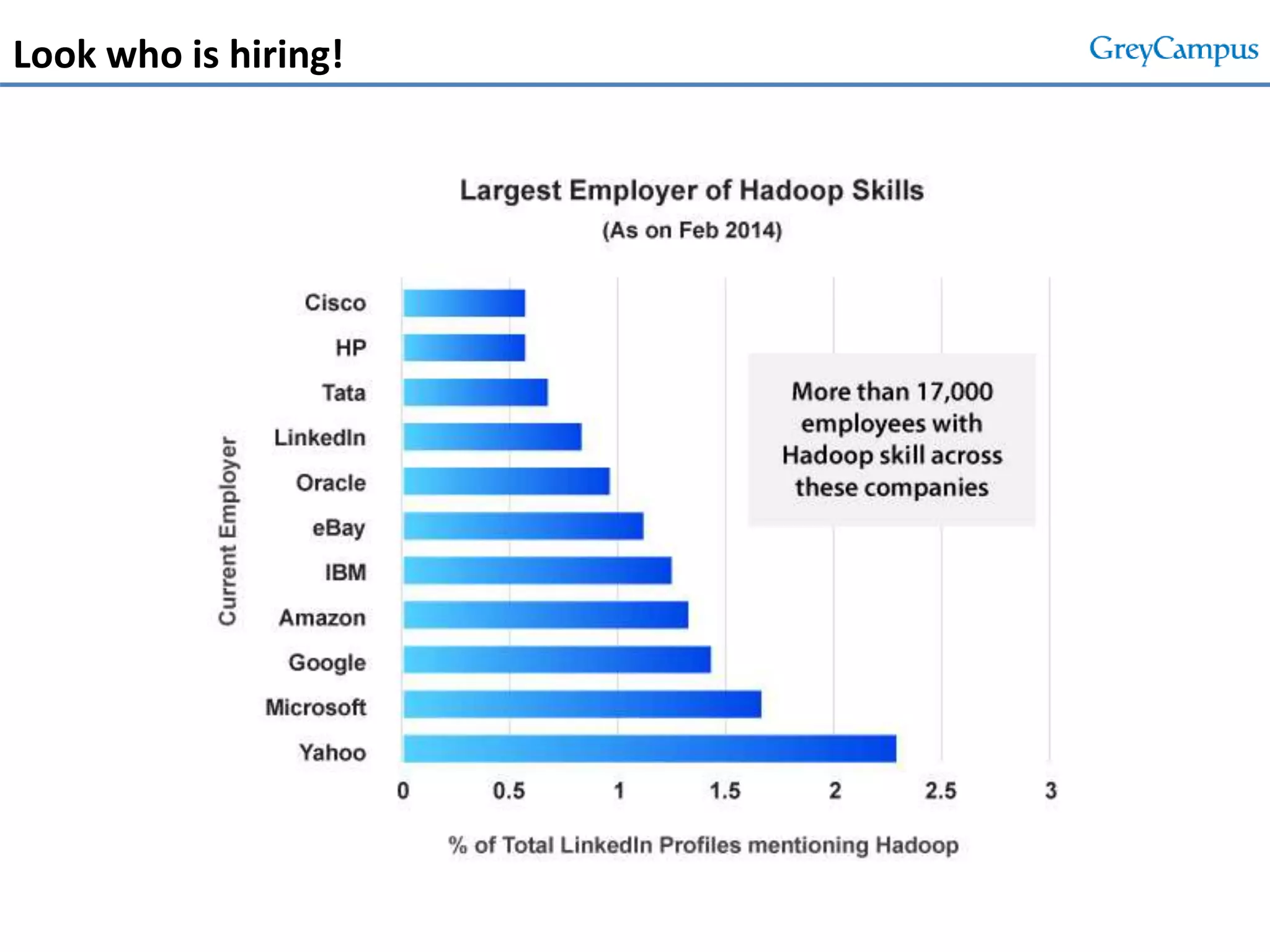
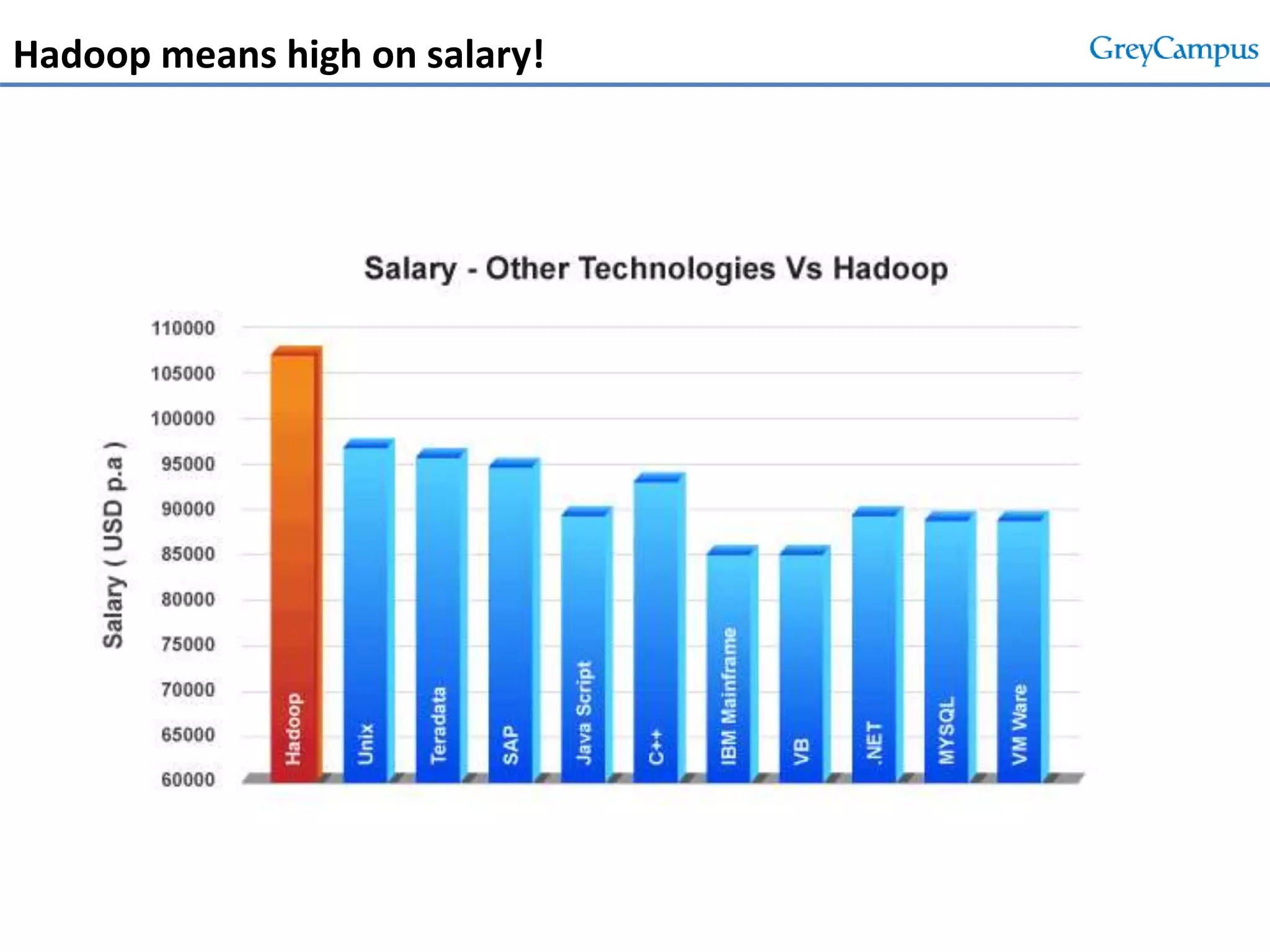
This document serves as an introduction to big data and Hadoop, detailing its importance, characteristics, and the enterprise opportunities it presents. It outlines the growing volume of data, the need for efficient processing mechanisms, and describes the structure of the big data course offered at GreyCampus, covering topics like HDFS and MapReduce. Additionally, it highlights the increasing demand for skilled professionals in the field and the potential for significant career growth in big data-related roles.